/https://www.ilsoftware.it/app/uploads/2024/10/modello-zamba2-7B-novita-innovazioni.jpg "Zamba2-7B, il modello che trasforma e migliora ancora l'intelligenza artificiale")
Stiamo assistendo a continue innovazioni nel settore dell’intelligenza artificiale e, in particolare, per quanto riguarda l’elaborazione del linguaggio naturale. A farsi largo nel mare magnum delle soluzioni che utilizzano i moderni e più evoluti Large Language Models (LLM) adesso c’è anche Zyphra.
Il suo nuovo modello Zamba2-7B si configura come un concorrente diretto dei più noti Google Gemma e Meta Llama 3. La startup, di stanza a Palo Alto (California) e con una crescente presenza a Montreal e Londra, afferma che il LLM supera le prestazioni dei modelli generativi più noti e blasonati grazie a un’architettura innovativa e a tecnologie all’avanguardia.
Perché Zamba2-7B è un modello innovativo per l’intelligenza artificiale: quali sono le novità
Come si legge nella nota ufficiale, Zamba2-7B è costruito sulla base di un’architettura ibrida nota come Zamba, che combina elementi della tradizionale architettura basata sull’uso dei Transformer con la più recente Mamba, presentata a dicembre 2023 (l’ultima iterazione si chiama Mamba-2).
Mamba-2 riduce significativamente il costo dell’attenzione, passando da una crescita quadratica a una crescita lineare. Una caratteristica, questa, che permette di gestire finestre di input molto più ampie, fino a un milione di token, senza un aumento esponenziale del costo computazionale. La combinazione con i Transformer consente di sfruttare le ottimizzazioni già esistenti per ottenere prestazioni migliori e risposte più precise in un ampio ventaglio di scenari pratici.
Un modello come Mamba-2 è contraddistinto da una velocità di addestramento significativamente superiore, grazie all’implementazione della tecnica State Space Dual (SSD) e della Structured Masked Attention (SMA). Il fine è quello di sfruttare al meglio l’hardware moderno, come GPU e TPU, migliorando l’efficienza durante le attività di training.

Ottimizzazione dell’efficienza per prestazioni al top
Con Zamba2-7B, l’intelligenza artificiale può trarre il meglio da Transformer e Mamba-2, aumentando l’efficienza a fronte di una riduzione del numero totale dei parametri. Una scelta progettuale consente a Zamba2-7B di sfruttare i punti di forza dell’architettura Transformer, mantenendo al contempo una struttura snella che ottimizza le prestazioni.
Per migliorare ulteriormente l’efficienza operativa, Zyphra ha implementato la tecnica Low-Rank Adaptation (LoRA) all’interno di ciascun Multi-Layer Perceptron (MLP) e blocco di attenzione condiviso. Il modello può così affinare le proprie prestazioni per diverse applicazioni.
I modelli complessi come le reti neurali richiedono enormi quantità di dati e risorse computazionali per l’addestramento. LoRA è progettata per rendere l’addestramento di modelli di grandi dimensioni più gestibile e meno oneroso. Invece di addestrare tutti i pesi di un modello, LoRA effettua una scomposizione in una forma che richiede meno risorse per l’addestramento.
Prestazioni e velocità di inferenza
Zamba2-7B conta circa 7,4 miliardi di parametri ed è stato sottoposto a un pre-addestramento su 2 trilioni di token di dati testuali e di codice. A questo si è aggiunta una fase di addestramento supplementare, che ha utilizzato circa 100 miliardi di token di alta qualità. Gli ingegneri di Zyphra sostengono che queste attività permettono a Zamba2-7B di superare altri modelli come Mistral-7B, Gemma 7B e Llama 3.1-8B.
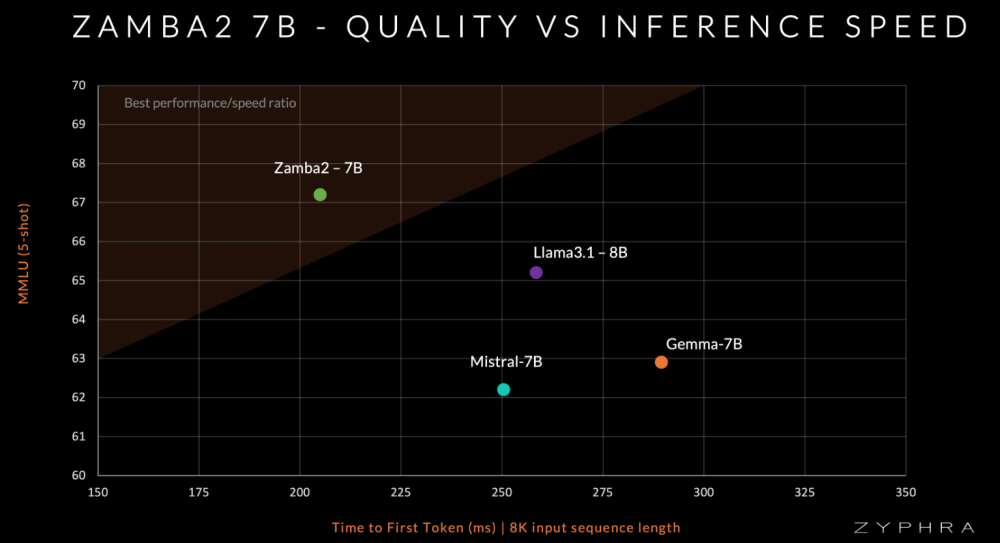
Un aspetto fondamentale su cui Zyphra pone l’accento è l’efficienza dell’inferenza di Zamba2-7B. Le valutazioni preliminari delle prestazioni, indicano che Zamba2-7B è in grado di generare token più rapidamente e con un uso della memoria significativamente inferiore rispetto ai modelli Transformer tradizionali. In particolare, il modello vanta una riduzione del 25% nel tempo di generazione dei token e un miglioramento del 20% nella velocità di generazione.
Zamba2-7B è già disponibile come prodotto open source: ecco come provarlo
Zyphra ha annunciato il rilascio del modello Zamba2-7B come prodotto open source, aprendo nuove possibilità per ricercatori, sviluppatori e aziende che desiderano sfruttarne le potenzialità.
La democratizzazione delle tecnologie AI avanzate è uno dei pilastri della filosofia di Zyphra. Con Zamba2-7B, l’azienda punta a creare un ambiente collaborativo per lo sviluppo di architetture innovative. È già disponibile un’integrazione Hugging Face e una versione completamente implementata in PyTorch è stata contemporaneamente rilasciata per semplificare l’adozione da parte degli sviluppatori. Chi fosse interessato a utilizzarla, può fare riferimento al repository ufficiale su GitHub.
Zyphra invita la comunità scientifica e tecnologica a unirsi all’iniziativa di cui è protagonista. Contribuendo a spingere i limiti dell’IA attraverso il contributo e l’innovazione collettiva, l’obiettivo è quello di costruire un futuro in cui i modelli generativi non solo siano in grado di rispondere alle esigenze attuali, ma definiscano nuovi standard per il settore.
Zyphra vuole sviluppare un sistema operativo basato sull’intelligenza artificiale: MaiaOS
Una realtà innovativa come Zyphra si propone di sviluppare sistemi di intelligenza multimodale attraverso la sua piattaforma principale, MaiaOS. La piattaforma combina architetture neurali avanzate, memoria a lungo termine e apprendimento rinforzato, mirando a ottimizzare l’efficienza dell’inferenza per le applicazioni di IA in tempo reale.
La startup punta a rendere l’intelligenza artificiale accessibile su una gamma più ampia di dispositivi, riducendo i costi di inferenza. Anche il modello Zamba2-7B, prodotto open source, è progettato per funzionare su dispositivi con risorse limitate, promuovendo un approccio decentralizzato rispetto ai modelli centralizzati delle grandi aziende più famose.
Secondo il CEO Krithik Puthalath, la missione è a questo punto quella di creare un’intelligenza artificiale personale che migliori la connessione tra le persone e i dispositivi. Zyphra critica l’approccio monolitico delle grandi aziende, sostenendo che l’IA dovrebbe essere personalizzata e in grado di apprendere dalle interazioni con gli utenti.
Per perseguire questo obiettivo, Zyphra non si limita a sviluppare modelli di linguaggio. Il team è impegnato nella ricerca e nello sviluppo per affrontare le sfide attuali nell’IA, ispirandosi anche ai principi della neuroscienza per migliorare le capacità dei modelli.
Il significato della fusione tra Transformer e un modello come Mamba-2
Gli shared attention blocks (o blocchi di attenzione condivisi) dei “classici” Transformer, sono componenti che svolgono un ruolo cruciale nella gestione delle dipendenze a lungo termine tra le diverse parti delle sequenze di input.
In Zamba2-7B, ci sono due blocchi di attenzione condivisi che vengono intercalati con i blocchi Mamba-2. I pesi dei blocchi di attenzione sono condivisi tra i vari strati (layer) del modello, con una conseguente riduzione del numero complessivo dei parametri necessari, ottimizzando l’uso delle risorse senza compromettere la capacità del modello di catturare le dipendenze tra le sequenze di input.
Il concetto di attenzione nei Transformer permette di gestire le relazioni tra i token (parole o frammenti di testo) all’interno delle sequenze. I blocchi di attenzione condivisi in Zamba2-7B migliorano ulteriormente queste abilità mantenendo informazioni critiche attraverso diversi strati, migliorando la coerenza e la profondità del contesto elaborato.
L’integrazione tra blocchi Mamba-2 e blocchi di attenzione contribuisce proprio a bilanciare la capacità del modello di processare grandi volumi di dati (grazie al modello Mamba-2) e, allo stesso tempo, di catturare accuratamente le relazioni tra i dati attraverso sequenze lunghe (grazie ai blocchi di attenzione).
Credit immagine in apertura: iStock.com – BlackJack3D
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")