/https://www.ilsoftware.it/app/uploads/2023/09/visione-artificiale-DINOv2-meta.jpg "Visione artificiale gratis nei progetti commerciali con Meta DINOv2 e FACET")
DINOv2 è un modello di visione artificiale avanzato addestrato tramite apprendimento auto-supervisionato. In un altro articolo abbiamo spiegato cos’è il modello DINOv2: svelato da Meta a fine maggio 2023 come prodotto open source, abilita lo sviluppo di applicazioni evolute per la computer vision. In altre parole, la macchina diventa in grado di “comprendere” quanto raffigurato nelle immagini, i legami tra entità ed oggetti e di prendere decisioni sulla base di quanto contenuto nelle sequenze video.
Il rilascio di DINOv2 come prodotto open source mirava a promuovere l’innovazione e la collaborazione all’interno della comunità dei ricercatori, consentendo l’uso del modello in una vasta gamma di applicazioni e soluzioni pronte per il “mondo reale”.
Con l’arrivo del mese di settembre 2023, tuttavia, Meta ha compiuto un ulteriore passo avanti annunciando la modifica della licenza. Quella precedente, infatti, non consentiva l’utilizzo del modello per finalità commerciali. Grazie all’adozione dalla licenza Apache 2.0, invece, DINOv2 può d’ora in avanti essere adoperato e integrato in qualunque progetto.
Visione artificiale sempre più protagonista
La visione artificiale è un campo dell’intelligenza artificiale che si concentra sulla creazione di sistemi informatici in grado di interpretare e comprendere il mondo, cercando di avvicinarsi il più possibile alle capacità dell’essere umano. Diventa quindi possibile elaborare in maniera automatizzata immagini e informazioni visive catturate da dispositivi come telecamere e sensori ottici.
Meta fa un esempio concreto partendo dall'”ampia scala” per arrivare alla “scala ridotta”: dai rilevamenti della crescita di nuovi alberi in aree deforestate all’identificazione delle parti di una cellula, i modelli di visione artificiale hanno il potenziale per contribuire al progresso in tutta una serie di campi applicativi.
Le novità di DINOv2 e i modelli previsionali
Oltre alla licenza Apache 2.0, DINOv2 si arricchisce di una serie di modelli di previsione densa per la segmentazione semantica delle immagini e la stima della profondità monoculare, offrendo agli sviluppatori e ai ricercatori una flessibilità ancora maggiore.
Cosa significa in soldoni? Partiamo innanzi tutto dall’espressione modelli di previsione densa (dense prediction models): si tratta di modelli basati sull’apprendimento automatico progettati per effettuare previsioni sui dati in modo dettagliato e completo, spesso associando una previsione a ciascun elemento dei dati forniti in input. E come si spiega in questo documento, la dense prediction è un po’ come l’attività che assegna un’etichetta a ciascun elemento di un’immagine, per esempio a un insieme di pixel.
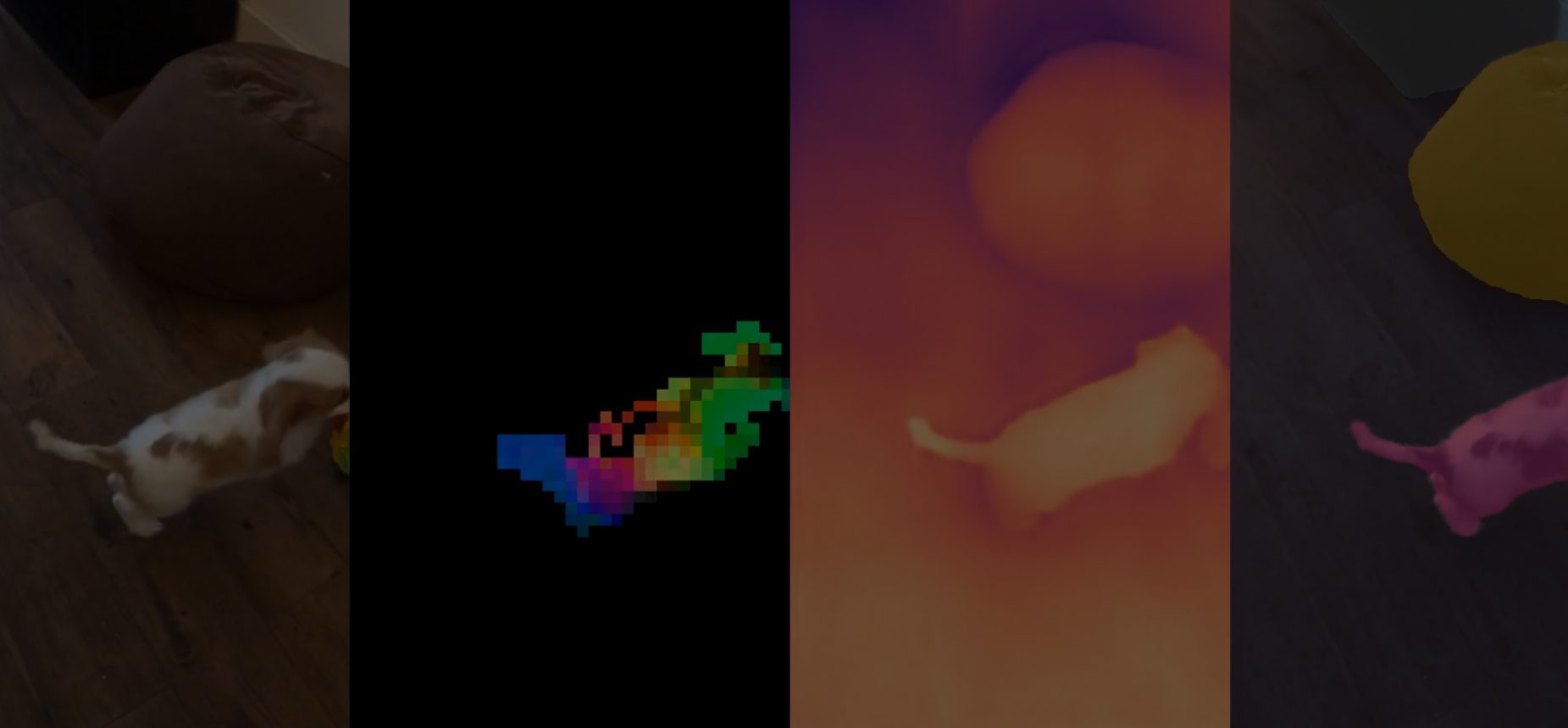
La segmentazione semantica è una tecnica che consiste nel dividere un’immagine in diverse regioni o pixel per semplificare l’attività di dense prediction descritta in precedenza. Ad esempio, nell’immagine che raffigura una strada pubblica, la segmentazione semantica può identificare le auto, le persone, i marciapiedi e altri elementi, assegnando loro etichette specifiche.
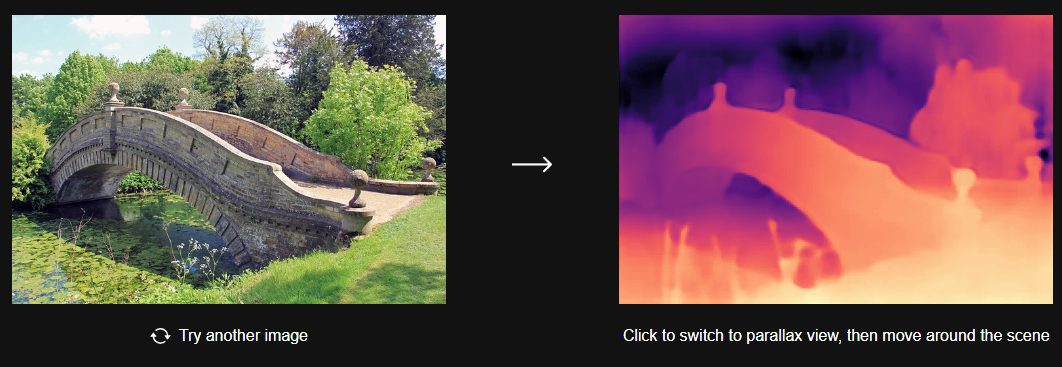
La stima della profondità monoculare, invece, è il processo mediante il quale un sistema, utilizzando una sola immagine, cerca di determinare la distanza tra gli oggetti presenti nella foto stessa. Si tratta di un approccio utile in molteplici campi, ad esempio anche nella guida autonoma: in questo caso è infatti importante comprendere quanto sono lontani gli oggetti circostanti.
Come provare DINOv2: esempi concreti
Puntando il browser a questo indirizzo, è possibile trovare una serie di esempi concreti che descrivono da vicino il funzionamento e le potenzialità dell’ultima versione di DINOv2. Fate clic su Try the demos e lasciatevi guidare alla scoperta di uno strumento così evoluto e potente. DINOv2 sfrutta un ampio e curato dataset di dati di addestramento, formato da 142 milioni di immagini raccolte dalla rete.
Ecco gli esempi proposti:
Stima della profondità: DINOv2 offre risultati all’avanguardia e una forte capacità di generalizzazione nella stima della profondità da un’unica immagine. Questo significa che può calcolare la distanza tra gli oggetti nell’immagine senza la necessità di dati di profondità aggiuntivi.
Segmentazione semantica: Il modello è in grado di raggruppare le immagini in classi di oggetti senza la necessità di ulteriori affinamenti manuali. Questa capacità è utile per applicazioni come il riconoscimento di oggetti in un’immagine.

Recupero di istanze: DINOv2 può estrarre le caratteristiche peculiari di un’immagine e “congelarle” come set di dati. Questi informazioni possono essere utilizzate direttamente per trovare opere d’arte simili a un’immagine prendendo di esame ricche collezioni di dati. Il modello sa insomma riconoscere somiglianze tra le immagini basandosi sulle loro rispettive caratteristiche.
Corrispondenza densa e sparsa: Con DINOv2 si può mappare in modo coerente tutte le parti di un’immagine senza supervisione. Uno schema particolarmente utile quando risulta necessario comprendere come diverse parti di un’immagine sono collegate tra loro.
Per ciascuno degli esempi citati, la demo allestita da Meta sul Web permette di ricevere in ingresso un’immagine inviata dall’utente. In questo modo è possibile sbizzarrirsi con i test e approfondire i possibili campi applicativi del modello di visione artificiale.
Cos’è FACET
Sebbene DINOv2 e altri modelli di visione artificiale simili consentano di svolgere compiti evoluti come la classificazione delle immagini e la segmentazione semantica, resta sempre un problema di fondo. Come tutte le intelligenze artificiali, quanto prodotto dal modello può essere significativamente influenzato dalla qualità dei dati di addestramento e la produzione di output che siano, allo stesso tempo, equi ed etici potrebbe risentirne. Il rischio che il modello etichetti i maniera erronea delle persone e degli oggetti è elevatissimo.
FACET (FAirness in Computer Vision EvaluaTion) è un benchmark introdotto da Meta che ha come obiettivo quello di valutare l’equità nei modelli di visione artificiale. Aiuta a valutare l’abilità dei modelli di visione artificiale ad affrontare problematiche legate, per esempio, al genere, all’età, al colore della pelle e ad altre caratteristiche demografiche di ciascun individuo rappresentato nelle immagini. Il dataset usato come riferimento da FACET è composto da 50.000 foto di persone, etichettate in maniera certamente corretta ed accurata da specialisti in carne ed ossa.
Il benchmark di Meta è al momento destinato solo a scopi di valutazione nell’ambito della ricerca e non può essere utilizzato per l’addestramento. Tuttavia, sono in corso di distribuzione delle basi di dati già classificate in modo da aiutare gli sviluppatori nei loro progetti.
Le immagini dell’articolo sono tratte dal comunicato e dal sito di presentazione di DINOv2 (Meta).
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")
/https://www.ilsoftware.it/app/uploads/2024/07/chip-IA-openai.jpg "OpenAI lancia Flex Processing: rivoluzione dei costi API per modelli AI")
/https://www.ilsoftware.it/app/uploads/2025/04/grok-lg-ai-emotiva-pubblicita.jpg "LG lancia l'AI emotiva sulle Smart TV: pubblicità su misura per i tuoi sentimenti")