/https://www.ilsoftware.it/app/uploads/2024/05/riconoscere-immagini-llama3-v-IA.jpg "Riconoscere immagini con Llama 3-V, il modello open source super economico da addestrare")
L’innovazione nel campo dell’intelligenza artificiale continua a sorprendere con la recente introduzione di Llama 3-V, un modello open source capace di attivare il riconoscimento delle immagini. Esistono già diversi modelli per riconoscere le immagini: che cos’ha, quindi, Llama 3-V di davvero speciale?
Come spiegano gli autori del progetto sul repository GitHub, il nuovo modello ha prestazioni paragonabili a GPT-4V di OpenAI, pur essendo significativamente più piccolo e realizzato con costi di pre-training pari ad appena 500 dollari.
Riconoscere immagini con l’intelligenza artificiale di Llama 3-V
Basato sul modello linguistico Llama3 8B rilasciato da Meta, Llama 3-V ha dimostrato di offrire performance superiori del 10-20% rispetto al popolare modello multimodale LLaVa. E sebbene di dimensioni contenute, Llama 3-V riesce a competere con i modelli closed-source di dimensioni oltre 100 volte superiori.
Già disponibile su GitHub, oltre che su Hugging Face, il modello Llama 3-V apre nuovi orizzonti per gli sviluppatori e i ricercatori. Favorisce infatti non soltanto l’innovazione, ma anche la trasparenza e la collaborazione nel campo dell’intelligenza artificiale.
Il modello Llama 3-V ha dimostrato capacità avanzate nella “comprensione” e nell’interazione con varie tipologie di immagini. Mettiamo il termine comprensione sempre tra virgolette: il motivo è spiegato nell’articolo in cui descriviamo il funzionamento dei LLM senza usare la matematica (o quasi).
Come provare LLama 3-V
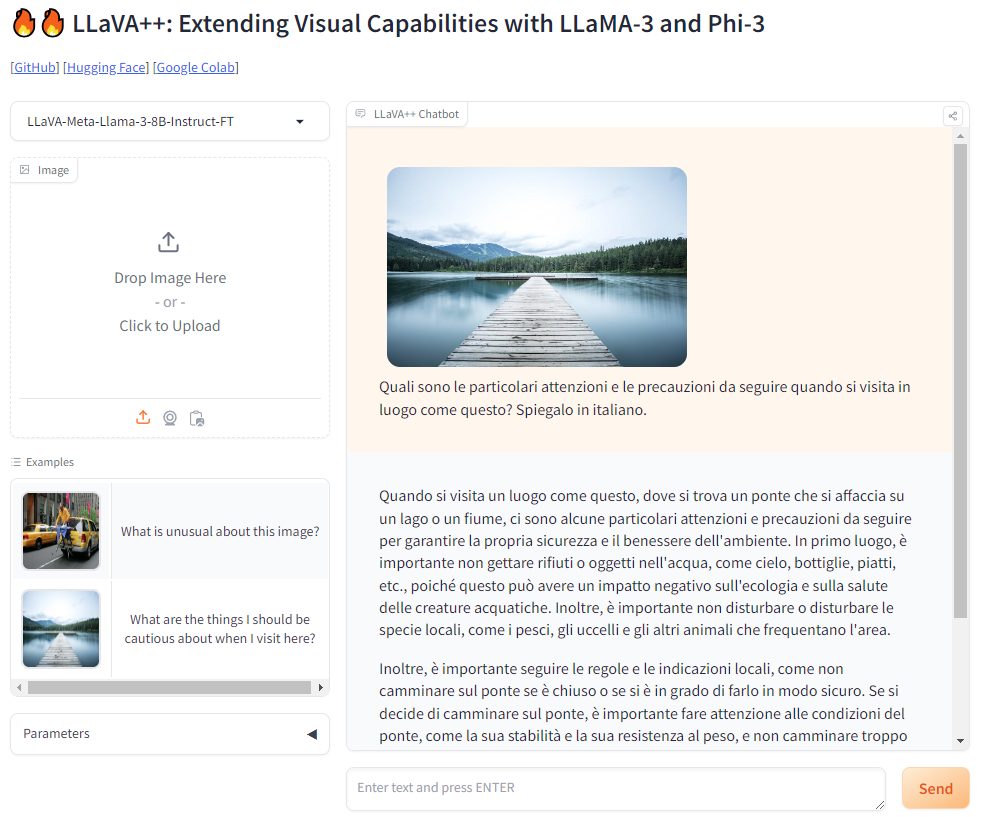
Per mettere alla prova il funzionamento di un modello come LLama 3-V, è sufficiente puntare il browser su questa pagina Hugging Face. Si può cominciare utilizzando ad esempio le immagini proposte nella colonna di sinistra. Oppure, in alternativa, si è liberi di effettuare l’upload di qualunque foto cliccando su Drop image here or click to upload.
Da impostazione predefinita, LLama 3-V risponde alle richieste in inglese (prompt). Nulla vieta, però, di inviare domande in italiano: LLama 3-V si comporta peraltro piuttosto bene anche nell’elaborazione di prompt avanzati nella nostra lingua. Come unica accortezza, suggeriamo di aggiungere la frase magica “Spiegalo in italiano” in calce a ogni richiesta. In questo modo si sarà certi di ricevere un riscontro in italiano.
Se si prende l’immagine del pontile sul lago, LLama 3-V offre risposte pertinenti e articolate. Riflettendo il comportamento di un modello come Llama3, che affonda le radici in uno schema stocastico, il LLM produce risposte molto diverse tra un tentativo e l’altro. Anche usando lo stesso identico prompt. Una volta, ad esempio, LLama 3-V ha riconosciuto gli elementi presenti nella foto, quindi si è concentrato sulla potenziale pericolosità del pontile. In un altro caso, invece, si è soffermato sul rispetto del luogo dal punto di vista naturalistico e paesaggistico.
La tecnologia dietro al funzionamento di Llama 3-V
Secondo Aksh Garg, che ha rilasciato Llama 3-V, il modello funziona passando prima l’immagine al modello visivo SigLIP, che analizza le relazioni tra l’immagine e il testo, e poi al modello linguistico Llama 3. Garg osserva come Llama 3 abbia davvero rivoluzionato il mondo delle applicazioni che integrano funzionalità di intelligenza artificiale, superando GPT-3.5 nella maggior parte dei benchmark e GPT-4 in alcuni di essi.
GPT-4o, rilasciato da OpenAI a metà maggio 2024, ha riconquistato la leadership in termini di accuratezza multimodale, ma Llama 3-V è un modello con un elevato carico di innovazione, capace di ridefinire le regole. A differenza dei modelli progettati e sviluppati da OpenAI e da altre aziende, Llama 3-V è il primo modello multimodale costruito su Llama 3 e, soprattutto, la fase di addestramento costa meno di 500 dollari. Davvero niente.
Llama 3-V ha il potenziale per democratizzare l’uso dell’intelligenza artificiale avanzata, offrendo strumenti potenti sia a ricercatori che sviluppatori in tutto il mondo. La sua disponibilità come modello open source su piattaforme come Hugging Face e GitHub è un invito alla comunità globale che può adesso esplorare, migliorare e applicare la tecnologia in modi innovativi e creativi.
Proponendo al modello l’immagine di un cane con una corona in testa, Llama 3-V ha osservato – tra le altre cose – come sia divertente che un cane indossi una corona, come un re. Un semplice esempio che evidenzia la capacità del modello di interpretare ogni genere di foto, rispondendo anche in modo umoristico, quando ciò risultasse coerente con il contesto.
Credit immagine in apertura: iStock.com – ktsimage
/https://www.ilsoftware.it/app/uploads/2024/03/wish-disney.jpg "OpenAI potrà usare i personaggi Disney, Google no")
/https://www.ilsoftware.it/app/uploads/2025/06/grok-donald-trump.jpg "Trump blinda l'AI: più controllo col nuovo ordine esecutivo")
/https://www.ilsoftware.it/app/uploads/2025/07/grok.jpeg "Le scuole di El Salvador si affidano all'AI Grok di Elon Musk")
/https://www.ilsoftware.it/app/uploads/2025/12/novita-GPT-52.jpg "GPT-5.2: analisi delle novità del nuovo modello AI integrato in ChatGPT e nelle API")