/https://www.ilsoftware.it/app/uploads/2024/02/modello-AI-modifica-immagini-apple.jpg "Provate a modificare le immagini con il nuovo modello IA di Apple")
Il campo dell’editing delle immagini si sta progressivamente perfezionando grazie allo sviluppo e al progressivo miglioramento delle performance dei modelli generativi. Di recente abbiamo visto come Fooocus sostituisca le applicazioni di fotoritocco: l’applicazione, eseguibile anche in locale senza appoggiarsi al cloud, permette di applicare modifiche di alto livello a foto e immagini, semplicemente fornendo indicazioni esplicite usando il linguaggio naturale.
Cosa sono i Multimodal Large Language Models (MLLM)
I MLLM sono una categoria avanzata di modelli di intelligenza artificiale che integrano la comprensione del linguaggio naturale con una percezione visiva avanzata. Sono progettati per gestire informazioni fornite con diverse modalità (ecco perché sono “multimodali“): uniscono testo e immagini, riuscendo a sviluppare una comprensione più completa del contesto sul quale operano.
I modelli di intelligenza artificiale che appartengono alla categoria dei MLLM, creano connessioni più ricche tra le istruzioni verbali e il contenuto visivo. Possono quindi interpretare istruzioni verbali e tradurle in azioni specifiche di manipolazione delle immagini.
Il meccanismo di apprendimento end-to-end fa sì che il modello sia in grado di “imparare” sia dalle istruzioni verbali che dal risultato visivo dell’operazione di editing. Una prassi che contribuisce a migliorare progressivamente le capacità di comprendere ed eseguire modifiche dirette sulle immagini.
Apple presenta in anteprima il suo modello MGIE per modificare le immagini con l’IA
Sapevamo che anche Apple è attivamente impegnata nello sviluppo di soluzioni basate sull’intelligenza artificiale che integrano abilità di computer vision. L’apprezzabile novità è che la Mela ha da poco pubblicato su GitHub il suo modello MGIE (Guiding Instruction-based Image Editing via Multimodal Large Language Models) che estremizza il concetto di MLLM.
L’obiettivo di MGIE consiste nel migliorare la controllabilità e la flessibilità della manipolazione delle immagini attraverso comandi naturali, senza la necessità di descrizioni dettagliate o l’apposizione di maschere sulle immagini.
Una delle sfide affrontate da MGIE consiste nell’elaborazione delle istruzioni fornite in linguaggio naturale, spesso troppo concise per le soluzioni attualmente disponibili. MGIE sfrutta le capacità promettenti dei MLLM nella comprensione cross-modale e nella generazione di “risposte consapevoli”.
Il modello svelato da Apple riesce a derivare istruzioni espressive e fornisce una guida esplicita per la manipolazione delle immagini. Il modello di editing cattura le informazioni e le utilizza per l’addestramento end-to-end.
Come provare subito Apple MGIE
Trattandosi di un progetto open source, è già possibile mettere alla prova il modello MGIE utilizzando Hugging Face e le risorse di calcole offerte dalla piattaforma. Basta collegarsi con questa pagina quindi trascinare o caricare l’immagine da elaborare nel riquadro di sinistra.
Nel campo Instruction, si deve invece usare il linguaggio naturale per chiedere a MGIE di effettuare una specifica modifica sul contenuto dell’immagine. Si può ad esempio chiedere di rimuover un elemento dalla foto, aggiungerne un altro, inserire oggetti e persone, applicare effetti, effettuare particolari rielaborazioni e così via.
Non aspettatevi ancora risultati eccelsi perché, come detto, il modello deve evolvere man mano che lo si utilizza ma è comunque possibile ottenere un primo assaggio, senza installare nulla in locale, proprio usando l’istanza ospitata su Hugging Face.
Poiché il sistema è attualmente preso d’assalto e la coda di lavoro risulta davvero molto lunga, si può fare clic sul link accanto alla voce “if the queue is full (this app is too busy), you can also try it here” in modo da utilizzare un server alternativo.
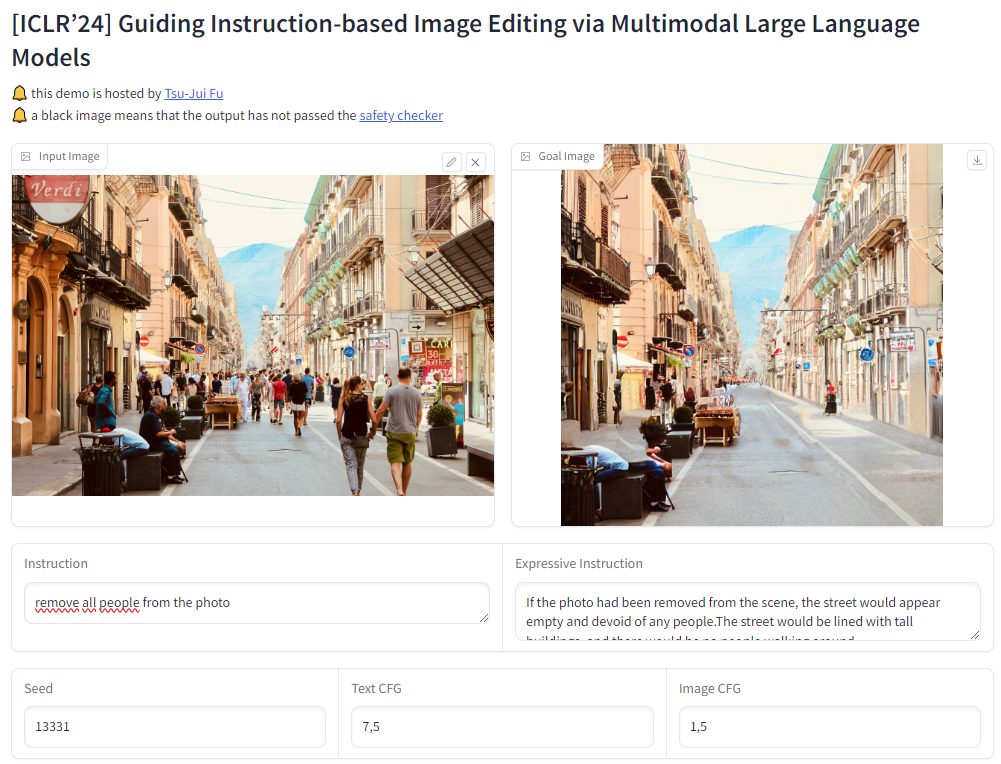
Abbiamo chiesto di rimuovere dall’immagine tratta da Unsplash tutte le persone raffigurate nella foto. Il risultato che si vede nell’immagine è tutt’altro che perfetto ma rappresenta comunque un punto di partenza.
I campi “Seed“, “Text CFG” e “Image CFG” si riferiscono a parametri o configurazioni specifici utilizzati durante il processo di manipolazione delle immagini basato su istruzioni. Forniscono una maggiore personalizzazione e controllo durante l’uso di MGIE per l’editing delle immagini.
Installazione e utilizzo locale
I tecnici Apple coinvolti nello sviluppo del progetto MGIE spiegano che per usare il modello è necessario creare un ambiente virtuale con Python 3.10 utilizzando Conda. quindi installare le dipendenze tramite pip. Il passaggio seguente prevede la clonazione del repository MGIE e la conseguente installazione delle dipendenze.
Le istruzioni per procedere in tal senso sono riassunte al paragrafo “Requirements“.
Prima di utilizzare MGIE, è necessario scaricare i dati CLIP-filtered IPr2Pr ed elaborarli. La fase di addestramento necessita della presenza dei modelli Vicuna-7B e LLaVA-7B all’interno delle due corrispondenti cartelle locali.
Ad addestramento ultimato, è possibile passare alla fase di inferenza utilizzando il modello MGIE precedentemente allenato. I passi da seguire sono indicati in questa pagina.
Credit immagine in apertura: iStock.com – Userba011d64_201
/https://www.ilsoftware.it/app/uploads/2025/02/fastweb-vodafone-cineca-ai-generativa.jpg "Cineca e Fastweb + Vodafone: alleanza per l'AI generativa nelle aziende")
/https://www.ilsoftware.it/app/uploads/2024/01/OpenAI.jpg "OpenAI: modifiche a regolamento di ChatGPT riguardo argomenti controversi")
/https://www.ilsoftware.it/app/uploads/2025/01/1-25.jpg "Rilasciato il modello AI Grok 3: è 10 volte più veloce del predecessore")
/https://www.ilsoftware.it/app/uploads/2025/02/intelligenza-artificiale-generale-AGI-google.jpg "Ecco come Google arriverà all'AGI, Intelligenza Artificiale Generale")