/https://www.ilsoftware.it/app/uploads/2024/09/openai-rischio-ban-jailbreaking-modelli-o1.jpg "OpenAI minaccia chi cerca di scoprire il ragionamento dei modelli o1")
OpenAI ha recentemente lanciato la famiglia di modelli IA “Strawberry“, pubblicizzando le capacità di ragionamento dei LLM o1-preview e o1-mini. A fronte di questa importante evoluzione tecnologica, tuttavia, l’azienda sembra determinata a mantenere segreti i meccanismi interni di funzionamento dei nuovi modelli. Diversi utenti hanno riferito di aver ricevuto email minacciose da parte di OpenAI. Le comunicazioni sono arrivate a chi ha provato a utilizzare prompt “furbi”, congegnati con l’obiettivo di esplorare il “processo di pensiero” del modello.
In un altro articolo abbiamo svelato i segreti di OpenAI o1, chiarendo se – al netto di tutto il clamore ingeneratosi in questi giorni – un’intelligenza artificiale possa davvero ragionare o meno.
OpenAI: non cercate di scoprire il ragionamento dei modelli o1
Contrariamente ai modelli precedenti, i modelli o1 sono stati concepiti per seguire un processo di problem-solving approfondito, che verosimilmente avviene snodandosi lungo più passaggi Zero-shot-CoT (dove CoT sta per Chain-of-Thought).
Mentre soluzioni come G1, che usano un approccio aperto basato su Llama-3.1 70b espongono tutti i passaggi del “processo cognitivo” che porta alla produzione della risposta finale, OpenAI ha scelto di non mostrare i passi intermedi mantenendoli segreti “dietro le quinte”.
La comunità di ricercatori e i red-teame hanno quindi posto in essere svariati tentativi per aggirare le protezioni imposte da OpenAI attraverso tecniche di jailbreak e prompt injection, con l’obiettivo di scoprire la catena di pensiero “grezza” del modello o1. Nonostante alcune segnalazioni dei primi successi, non ci sono ancora riscontri certi.
Di fronte a tali tentativi, però, OpenAI non è rimasta a guardare: avvisi e minacce di blocco degli account sono stati inviati a chiunque abbia tentato o cerchi di sondare il comportamento del modello in profondità, oltre i limiti imposti dalle condizioni di utilizzo del servizio.
I ficcanaso rischiano il blocco dell’account OpenAI
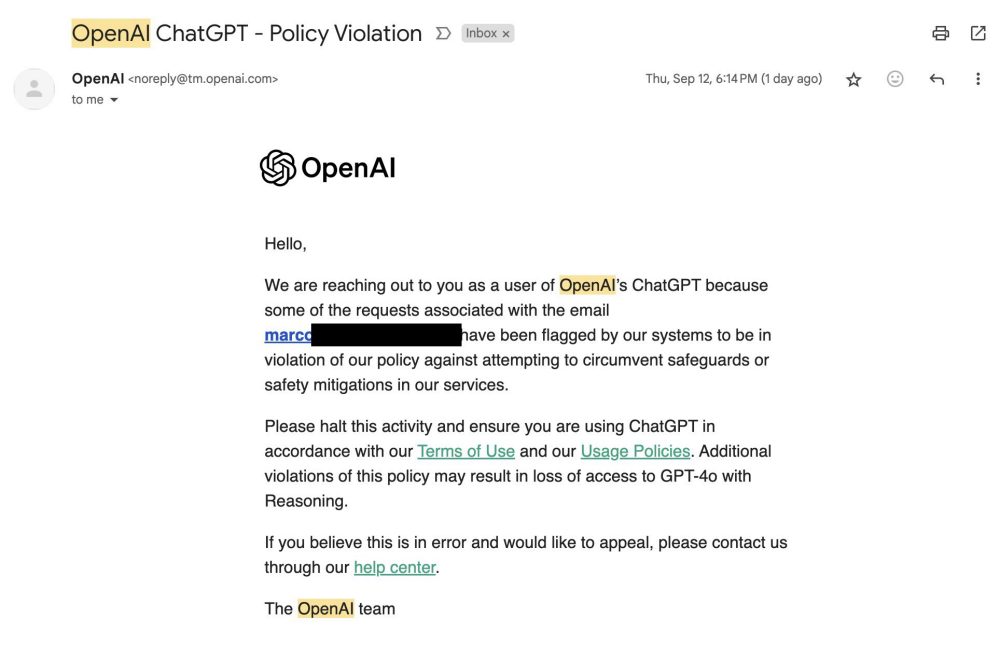
Un esempio significativo è quello di Marco Figueroa, gestore dei programmi di bug bounty GenAI di Mozilla. Il ricercatore ha segnalato di essere finito nella lista di chi rischia il ban da parte di OpenAI. Il motivo è proprio il rilevamento, da parte della società guidata da Sam Altman, dei suoi tentativi di jailbreaking del sistema.
L’immagine seguente, tratta dal profilo X di Figueroa, contiene il testo completo ricevuto da OpenAI. L’azienda spiega di aver rilevato una serie di tentativi di bypassing delle protezioni e delle misure di sicurezza imposte. Invita quindi l’utente a cessare ogni comportamento in violazione dei termini del servizio e delle policy di utilizzo. Diversamente, ulteriori comportamenti non consentiti potrebbero portare al blocco di varie funzionalità, a partire dall’uso di GPT-4o con abilità di reasoning (quindi i modelli o1).
Il clima di tensione ha ovviamente alimentato il dibattito sul bilanciamento tra trasparenza e il diritto alla protezione dei segreti commerciali di un’azienda. OpenAI, infatti, giustifica le sue scelte con la volontà di migliorare l’esperienza utente e di conservare vantaggi competitivi rispetto alla concorrenza.
Credit immagine in apertura: iStock.com – Vertigo3d
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")