/https://www.ilsoftware.it/app/uploads/2023/05/img_21193.jpg "Nvidia presenta l'architettura Ampère a 7 nm e Tesla A100")
A distanza di due anni dalla presentazione dell’architettura Turing con supporto per il ray-tracing e dei core Tensor, NVidia toglie finalmente il velo da Ampère presentando per prima una GPU destinata ai data center – Tesla A100 – ma confermando che la stessa tecnologia costituirà la base per le future schede GeForce per il mercato mainstream.
Il processo litografico scelto per il chip A100 è quello di TSMC a 7 nm: rispetto al chip GV100 utilizzato nella GPU Tesla V100 viene adesso quasi triplicato il numero di transistor pur aumentando (di poco) le dimensioni del die (826 mm2contro i precedenti 815 mm2 e 54 miliardi di transistor contro i precedenti 21,1 miliardi).

La nuova Tesla A100 poggia il suo funzionamento su 6912 CUDA core rispetto ai 5120 della Tesla V100, funziona a 1,41 GHz in modalità turbo e aumenta significativamente la potenza sfruttabile dai core Tensor in modo da rendere ancora più performanti le più nuove ed esigenti applicazioni di intelligenza artificiale.
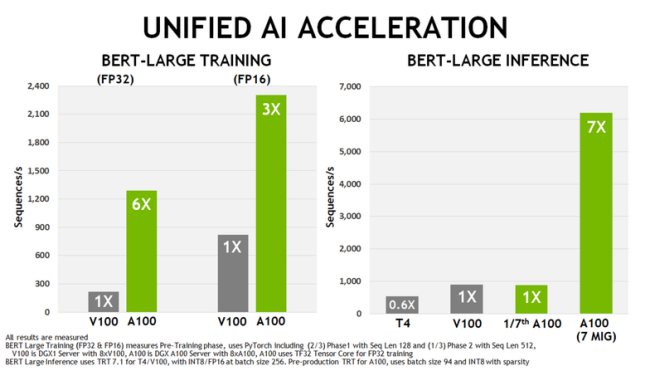
Il consumo energetico della nuova A100 passa a 400W, 50W in più rispetto al chip V100, ma in fase di addestramento delle reti neurali – secondo NVidia – la potenza che Tesla A100 riesce a esprimere è sei volte quella di una V100 e nell’elaborazione delle inferenze il fattore moltiplicativo è addirittura pari a sette.
Tesla A100 utilizza memorie HBM2 da 2,43 GHz per un totale complessivo di 40 GB di VRAM con un bus da 5192 bit – cinque chip HBM2 a 1024 bit ciascuno – per un’impressionante larghezza di banda di 1,6 TB/s.
La nuova scheda sfrutta l’interfaccia PCIe 4.0 e utilizza uno speciale connettore di comunicazione NVLink 3 che permette di far comunicare i componenti a bordo a 600 GB/s, molto di più dei 31,5 GB/s offerti sulla carta dallo standard PCIe 4.0. Si tratta di un’accortezza fondamentale per le configurazioni in cui risultasse necessario porre in parallelo fino a otto schede A100.
C’è un fatto interessante su questo chip ed è che una parte di esso è disattivata. Il chip GA100 completo, come indicato da Nvidia, comprende 8192 core CUDA con sei controllori di memoria HBM2 (bus massimo 6144 bit per circa 1,92 TB/s), che apre la porta a Nvidia per annunciare in futuro, come consentono le prestazioni di produzione, i modelli Tesla ed altre schede molto più potenti.
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")