/https://www.ilsoftware.it/app/uploads/2024/07/moshi-chatbot-kyutai-IA-vocale.jpg "Moshi, l'intelligenza artificiale adesso esprime emozioni: come provarla")
Kyutai è il primo laboratorio di ricerca indipendente sull’intelligenza artificiale in Europa, inaugurato a Parigi il 17 novembre 2023. Progetto senza scopo di lucro e con un’anima aperta, Kyutai ha come obiettivo primario quello di democratizzare l’IA attraverso tool che siano pubblicamente disponibili e accessibili.
Secondo i fondatori, l’Europa ha tutte le carte in regola per far sentire la sua voce nella corsa all’intelligenza artificiale, grazie alla potenza di calcolo disponibile e al dinamico ecosistema IA. Dal canto suo, Kyutai mira a fornire modelli di IA affidabili e ad alte prestazioni per l’intero ecosistema europeo.
Ma chi sono i fondatori della società transalpina Kyutai? I nomi sono certamente altisonanti: ci sono Xavier Niel, CEO di Iliad ed Eric Schmidt, ex CEO di Google. A loro si aggiunge Rodolphe Saadé, presidente di CMA CGM, nota società di logistica. Il CEO di NVIDIA, Jensen Huang, ha definito Kyutai come parte della “seconda era dell’intelligenza artificiale“, in cui l’IA sarà utilizzata in molti settori business, ad esempio in ambito manifatturiero e nelle biotecnologie. Senza dubbio un bell’endorsement.
Moshi è l’intelligenza artificiale che sembra mostrare emozioni e un comportamento più umano
Proprio in queste ore, Kyutai ha presentato Moshi, un rivoluzionario modello multimodale che lavora e fornisce risposte in tempo reale. Sebbene sia ancora suscettibile di notevoli migliorie, il modello appena svelato supera per certi versi anche GPT-4o di OpenAI, presentato a maggio 2024.
Moshi è un chatbot vocale progettato per comprendere ed esprimere emozioni, in grado di parlare in diverse lingue. Il sistema speech-to-text mantenuto costantemente in esecuzione, ascolta le richieste dell’utente e genera audio mantenendo un flusso conversazionale continuo.
Una delle caratteristiche più sorprendenti di Moshi è la sua capacità di gestire contemporaneamente due flussi audio, consentendo all’IA di ascoltare e parlare simultaneamente. Questa interazione in tempo reale è supportata da un pre-training congiunto su una miscela di testo e audio, sfruttando i dati provenienti da Helium, un LLM (Large Language Model) da 7 miliardi di parametri sviluppato da Kyutai.
Il processo di fine tuning di Moshi ha coinvolto 100.000 conversazioni sintetizzate, convertite utilizzando la tecnologia text-to-speech (TTS). La voce del modello è stata addestrata su dati sintetici generati da un modello TTS separato, raggiungendo un’impressionante latenza end-to-end di 200 millisecondi.
Gli ingegneri di Kyutai hanno messo a punto anche una variante più compatta di Moshi che può funzionare su un MacBook o una GPU di classe consumer, rendendo il sistema accessibile a un pubblico molto più ampio.
Come provare subito un botta e risposta vocale con il chatbot Moshi
Vi suggeriamo, innanzi tutto, di guardarvi la dimostrazione del funzionamento di Moshi pubblicata in questo video su YouTube. Come si vede il “botta e risposta” tra i responsabili di Kyutai e Moshi è istantaneo. Addirittura, molto spesso le voci si accavallano – come succede spesso in una normale conversazione tra umani -. Eppure, Moshi mantiene sempre dritte “le antenne”: è in grado di fermarsi e integrare quanto affermato con le osservazioni o le richieste aggiuntive pervenute a valle del riconoscimento vocale. Un altro esempio di interazione con Moshi è disponibile qui.
Potete anche voi provare Moshi puntando il browser su questa pagina. Per iniziare, basta digitare un indirizzo email nell’apposito campo quindi cliccare il pulsante Join queue.
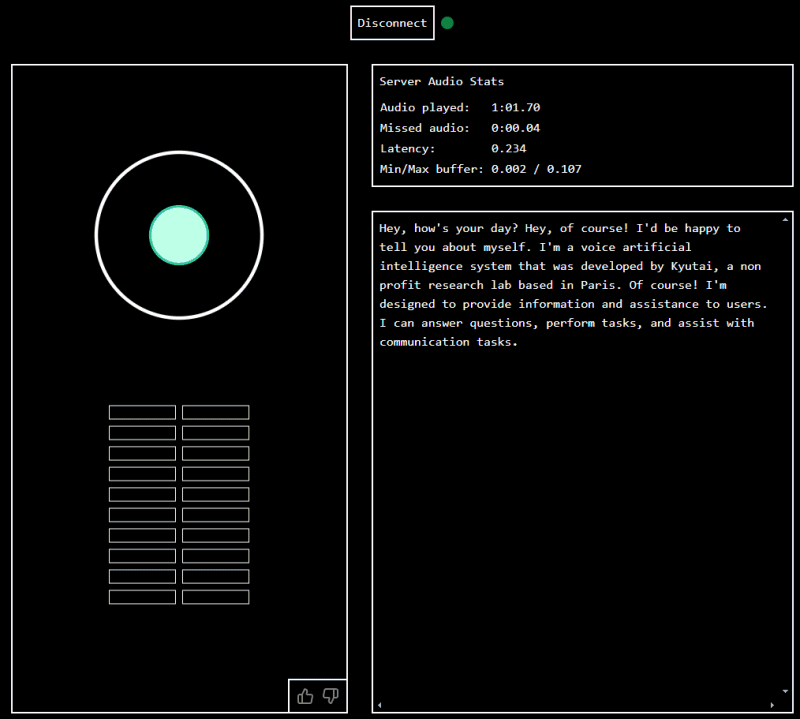
Come primo passo, si deve autorizzare l’accesso al microfono. A questo punto, è possibile iniziare a parlare. Purtroppo, al momento Moshi non riesce a conversare in italiano e non comprende né le domande né le affermazioni nella nostra lingua. Utilizzando l’inglese, comunque, potete rendervi conto delle abilità del sistema. E alla fine del dialogo, potete anche scaricare la registrazione in più formati.
Il motore TTS supporta 70 diverse emozioni e stili; è stato addestrato con 20 ore di audio registrato da una voce autorizzata. Il modello è progettato per essere adattabile e può essere adattato alle proprie specifiche esigenze con meno di 30 minuti di audio.
In diverse dimostrazioni, Moshi ha dimostrato di riuscire ad adattarsi a scenari molto differenti: ad esempio inventare e leggere una poesia con accento francese, creare racconti di pirati e storie misteriose.
Sicurezza ed etica
Kyutai è consapevole dei rischi associati con l’uso improprio delle tecnologie di intelligenza artificiale vocale, come la possibilità di creare contenuti audio fraudolenti o manipolatori.
Per questo motivo, gli sviluppatori di Kyutai hanno implementato strategie per analizzare automaticamente e in tempo reale tutto il contenuto generato da Moshi. L’obiettivo è prevenire utilizzi non conformi o addirittura illeciti.
L’azienda mantiene un database che contiene firme audio uniche per ogni clip audio generata da Moshi. Il database aiuta a identificare facilmente i contenuti, rendendo più difficile l’uso non autorizzato.
Specifiche tecniche di watermarking incorporano segni invisibili (inudibili dall’orecchio umano) all’interno degli audio generati. Queste “filigrane digitali” possono essere utilizzati per tracciare l’origine del contenuto e confermarne la provenienza.
Il futuro di Moshi
Kyutai ha piani ambiziosi per Moshi. In primis, il team di sviluppo prevede di pubblicare un report tecnico e versioni del modello aperte, inclusi il codice di inferenza, il modello 7B, il codec audio e l’intero stack ottimizzato.
Le future iterazioni di Moshi affineranno il modello sulla base dei feedback ricevuti dagli utenti. La licenza mira a essere il più permissiva possibile, favorendo l’adozione diffusa e l’innovazione.
Il modello multimodale appena svelato apre nuove vie per l’assistenza alla ricerca, il brainstorming, l’apprendimento linguistico e altro ancora, dimostrando il potere trasformativo dell’IA.
/https://www.ilsoftware.it/app/uploads/2025/04/comandi-ai-tag-gestire-schede-browser.jpg "Browser Opera: intelligenza artificiale per gestire le schede aperte")
/https://www.ilsoftware.it/app/uploads/2024/12/3-11.jpg "ChatGPT: generazione di immagini migliorata di nuovo disponibile per tutti")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")
/https://www.ilsoftware.it/app/uploads/2025/04/vulnerabilita-bootloader-AI.jpg "Microsoft usa l'AI per scoprire vulnerabilità in GRUB2, U-Boot e Barebox")