/https://www.ilsoftware.it/app/uploads/2024/11/ollama-llama-32-vision-chatpt-locale.jpg "Meglio di ChatGPT: Ollama e Llama 3.2 Vision per chattare con le immagini, in locale")
A fine settembre 2024, Meta ha pubblicato i suoi modelli generativi aperti Llama 3.2. In particolare, Llama 3.2 Vision è una serie di LLM (Large Language Models) multimodali, sviluppati per supportare l’elaborazione di immagini e testi. Fa parte della collezione di modelli generativi Meta Llama e si presenta in due varianti con dimensioni di 11 miliardi (11B) e 90 miliardi (90B) di parametri, istruite e ottimizzate per compiti che richiedono riconoscimento visivo, ragionamento su immagini, creazione di didascalie e risposte a domande relative ai contenuti visuali. Da oggi la piattaforma open source Ollama porta in locale il modello Llama 3.2 Vision e permette a tutti di svolgere elaborazioni complesse sulle immagini.
Cos’è Ollama e a cosa serve
Ollama è una piattaforma che consente agli utenti di eseguire modelli di intelligenza artificiale generativa, compresi quelli della gamma Llama. Si tratta di una soluzione che facilita l’interazione in locale con questi modelli, consentendo di elaborare sia il testo che le immagini tramite API e librerie integrate per linguaggi come Python e JavaScript.
In un altro articolo abbiamo visto come portare l’intelligenza artificiale sui propri sistemi con Ollama, a patto di poter disporre di una sufficiente potenza computazionale.
Di base Ollama funziona da riga di comando ma con il tempo sono nati molteplici strumenti che aggiungono a Ollama l’interfaccia grafica e consentono, ad esempio, di interagire con i moderni modelli generativi da una pagina Web.
Elaborazione delle immagini con l’AI, Ollama e Llama 3.2 Vision
Compatibile anche con Llama 3.2 Vision, Ollama consente di utilizzare anche il più recente modello Meta che integra funzionalità di visione, per elaborare immagini e testo in maniera interattiva. A seconda del modello Llama 3.2 scelto, è necessario disporre di una GPU dedicata con almeno 8 GB di VRAM oppure 64 GB di VRAM a seconda che si opti per la versione 11B o 90B.
Principali funzionalità principali di Llama 3.2 Vision integrato in Ollama
- Riconoscimento della scrittura a mano: Llama 3.2 Vision può identificare e convertire il testo scritto a mano, trasformandolo in formato digitale.Riconoscimento ottico dei caratteri (OCR): Il modello è in grado di leggere e interpretare testo presente nelle immagini, facilitando l’estrazione di informazioni da documenti scansionati e altre immagini contenenti testo.
- Analisi di grafici e tabelle: È possibile comprendere e descrivere dati strutturati in formati visivi, come grafici o tabelle.
- Domande sulle immagini: Il modello è capace di rispondere a domande basate sul contenuto di un’immagine, rendendo possibili interazioni avanzate con gli utenti.
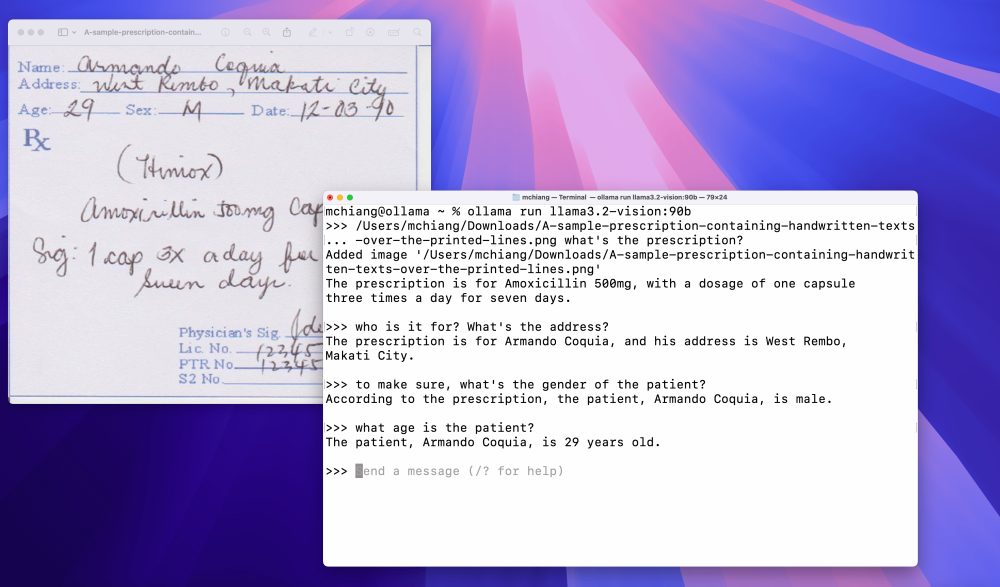
Utilizzo del modello
Per iniziare, è necessario scaricare Ollama (disponibile per Windows, Linux e macOS) e il modello desiderato, utilizzando il comando:
ollama pull llama3.2-vision
Successivamente, si può eseguire il modello con il comando che segue:
ollama run llama3.2-vision
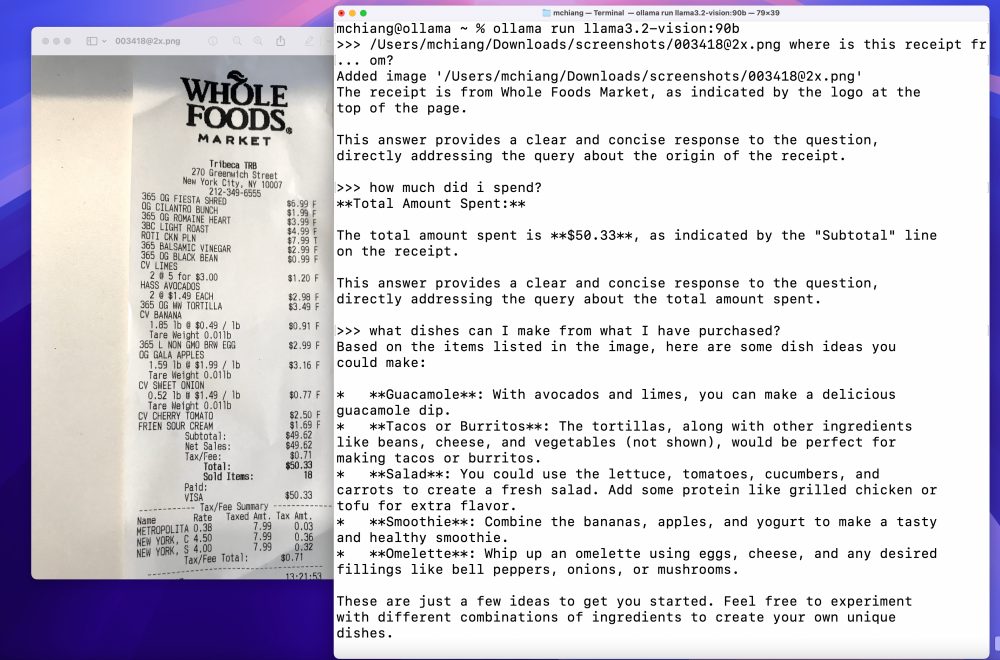
Integrazione con Python, JavaScript e cURL
Come accennato in precedenza, Ollama supporta l’uso di Llama 3.2 Vision tramite una libreria Python, consentendo di effettuare richieste basate sull’utilizzo di immagini in modo programmatico.
Sono inoltre disponibili una libreria JavaScript per utilizzare il modello all’interno di applicazioni Web e un’interfaccia API richiamabile tramite, ad esempio, tramite curl.
Gli sviluppatori possono così inviare richieste a Ollama e al modello Llama 3.2 Vision direttamente tramite cURL, utilizzando immagini codificate in base64.
Tutte le modalità di interazione con Ollama sono riassunte in questo post di presentazione.
Grazie a queste integrazioni, Ollama con Llama 3.2 Vision diviene un potente strumento per chi desidera analizzare immagini in maniera automatizzata, con applicazioni che spaziano dal riconoscimento del testo all’analisi dei dati visivi.
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")