/https://www.ilsoftware.it/app/uploads/2024/06/modelli-IA-open-source.jpg "La verità sui modelli usati per l'intelligenza artificiale: quali non sono open source")
Negli ultimi anni, nel settore delle soluzioni basate sull’intelligenza artificiale (IA) si è assistito a un rapidissimo sviluppo, con modelli linguistici di grande scala che hanno rivoluzionato il modo con cui interagiamo con la tecnologia. Large Language Models (LLM) come GPT di OpenAI sono completamente chiusi, mentre altri come LLaMA di Meta e Gemma di Google si presentano come sviluppati in maniera aperta. Ma fino a che punto questi modelli possono davvero essere considerati open source?
Modelli generativi davvero open source od openwashing?
Il termine open source implica l’accesso al codice sorgente. Tuttavia, la complessità dei LLM e la quantità enorme di dati coinvolti rendono questa apertura una sfida notevole. Rendere completamente aperto un modello potrebbe esporlo a rischi commerciali o legali, oltre ad aumentare il rischio di uso improprio.
Secondo i ricercatori Andreas Liesenfeld e Mark Dingemanse del Centre for Language Studies, Università di Radboud (Paesi Bassi), alcune aziende che si occupano dell’addestramento dei modelli generativi per poi condividerne l’utilizzo con gli utenti, sono dedite ad attività di openwashing. Con questo termine ci si riferisce all’etichettatura dei loro prodotti come open source: una denominazione che li rende più aperti e trasparenti di quanto non siano in realtà.
Per analizzare questa pratica, il team accademico ha valutato 40 modelli linguistici che si dichiarano “open source” o “aperti” basandosi su 14 parametri, tra cui la disponibilità del codice e dei dati di addestramento, la documentazione pubblica e la facilità di accesso.
I risultati della ricerca
Come si evince dalla lettura del report di Liesenfeld e Dingemanse, sebbene ogni modello affermi di essere “aperto”, solo BloomZ di BigScience è risultato essere completamente tale in ogni categoria valutata. Al contrario, Llama 3-Instruct di Meta ha ottenuto punteggi molto bassi in termini di apertura.
Il team di ricerca ha sottolineato che molti modelli di IA che si dichiarano aperti od open source pubblicano solo i pesi. Questo significa che i ricercatori esterni possono accedere e utilizzare i modelli addestrati, ma non possono ispezionarli o personalizzarli. Inoltre, è difficile comprendere appieno come il modello sia stato perfezionato per un compito specifico.
Dingemanse ha aggiunto che l’apertura dei LLM è cruciale quando si parla di riproducibilità. Se non è possibile riprodurre qualcosa, infatti, difficilmente si può parlare di un oggetto realizzato accogliendo criteri scientifici.
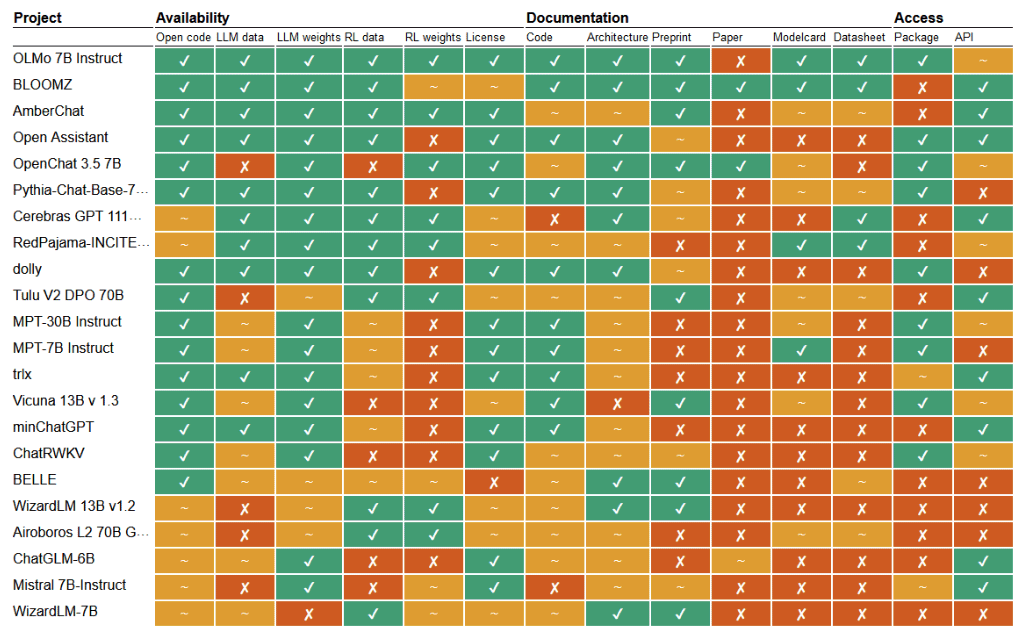
Una parte della tabella riepilogativa tratta dal documento “Rethinking open source generative AI“.
L’accesso limitato alle informazioni sui modelli ostacola la capacità dei ricercatori di innovare e costruire su quanto già esistente. Questo, sempre secondo gli autori dello studio, contribuirebbe a rallentare il progresso complessivo nel campo dell’IA rischiando di concentrare le risorse essenziali nelle mani di poche grandi aziende tecnologiche, a discapito di una comunità scientifica più ampia e diversificata.
Metriche e parametri oggettivi
Per il team guidato da Liesenfeld e Dingemanse è a questo punto fondamentale sviluppare standard condivisi e metriche oggettive per valutare il grado reale di apertura, andando oltre le semplici etichette di marketing. Solo applicando vera trasparenza e collaborazione sarà possibile sfruttare appieno il potenziale dell’intelligenza artificiale, garantendo al contempo un progresso etico e socialmente responsabile.
La sfida per il futuro sarà trovare un equilibrio tra la necessità di proteggere gli interessi commerciali e la proprietà intellettuale delle aziende con una maggiore apertura a beneficio della ricerca e dell’innovazione.
Il dibattito è destinato a intensificarsi nei prossimi anni, perché l’IA è destinata a rivestire un ruolo sempre più centrale nella nostra società e nella nostra economia.
Come interpretare i dati
I ricercatori invitano gli interessati a tenere d’occhio il sito Opening up ChatGPT. Qui è pubblicata una tabella con i riferimenti a un gran numero di modelli generativi.
A rigore, va detto che come benchmark è presentato anche ChatGPT che in realtà non è un modello ma semplicemente un chatbot. Il LLM che fa funzionare ChatGPT è GPT, nelle sue varie iterazioni (GPT 3.5, GPT-4, GPT-4o).
Com’è immediato notare, un modello con molti ✔︎ è considerato più aperto e trasparente; quelli riportati nella parte alta della tabella sono generalmente più aperti di quelli in basso. Così come abbiamo rilevato in precedenza, è importante notare che tati modelli definiti open source possono avere aree chiuse o parzialmente aperte.
Comprendiamo, come scrivono Liesenfeld e Dingemanse, l’esigenza di alcune aziende di proteggere parti del lavoro svolto. A nostro avviso, però, il problema è unicamente di licenza. Abbiamo dedicato un intero articolo alle differenze tra open source e software libero.
Sebbene l’indagine accademica sia stata pubblicata anche su Nature, i sostenitori del movimento del software libero direbbero che il riferimento c’è già. Qualunque software che non accorda agli utenti le quattro libertà fondamentali (eseguire, copiare, distribuire, studiare, modificare e migliorare il software) non può essere definito sufficientemente aperto. Ed è proprio la licenza scelta che dovrebbe subito chiarire come si inquadra ciascun elemento che compone ogni singolo modello.
Credit immagine in apertura: iStock.com – BlackJack3D
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475925_1745315889.jpeg "Ora è ufficiale: l'AI non impedisce di correre per gli Oscar")
/https://www.ilsoftware.it/app/uploads/2024/12/2-3.jpg "ChatGPT o3 sorprende tutti superando brillantemente il test Mensa")
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")