/https://www.ilsoftware.it/app/uploads/2023/11/modelli-generativi-attualita-perplexity.jpg "Intelligenza artificiale che conosce i fatti recenti: ecco i nuovi modelli Perplexity")
Tra le principali limitazioni degli attuali modelli LLM (Large Language Models), utilizzati per generare testo a partire dagli input forniti, c’è il problema delle allucinazioni e il fatto che l’intelligenza artificiale spesso fa fatica a fornire informazioni aggiornate e attuali. In generale, i modelli generativi non hanno visibilità sui fatti recentemente accaduti e non hanno quindi alcuna consapevolezza delle notizie di attualità.
Il chatbot Perplexity è uno dei più apprezzati in assoluto: rispetto a ChatGPT, dimostra di avere una maggiore “consapevolezza” dei contenuti più freschi pubblicati in rete e può quindi rispondere a domande che hanno a che fare avvenimenti e novità non troppo indietro nel tempo.
I modelli pplx-7b-online e pplx-70b-online rendono l’intelligenza artificiale più consapevole dell’attualità
Con la presentazione dei nuovi modelli pplx-7b-online e pplx-70b-online, Perplexity modifica alla radice il concetto di modello generativo incapace di fornire risposte attuali e aggiornate.
Entrambi i modelli sono costruiti a partire dalle base di mistral-7b e llama2-70b: abbiamo abbondantemente parlato di entrambi nelle pagine de IlSoftware.it. L’infrastruttura di ricerca, indicizzazione e crawling sviluppata internamente dagli ingegneri software di Perplexity consente di arricchire i modelli con informazioni rilevanti e aggiornate. Tanto che i nuovissimi pplx-7b-online e pplx-70b-online sono appunto in grado di utilizzare in modo efficace le informazioni estratte dalla rete.
Come funzionano i modelli di Perplexity che conoscono anche i fatti più recenti
Tre criteri principali sono utilizzati per valutare le prestazioni dei modelli di Perplexity:
- Helpfulness (Utilità): Quale risposta soddisfa meglio la domanda e segue le istruzioni specificate dall’utente?
- Factuality (Fattualità): Quale risposta fornisce informazioni accurate senza la presenza di allucinazioni?
- Freshness (Aggiornamento): Quale risposta contiene informazioni più aggiornate?
I nuovi modelli appena svelati da Perplexity superano OpenAI GPT-3.5 e llama2-70b in tutti e tre i criteri citati, utilizzando valutazioni oggettive proprie degli esseri umani.
Certo, permangono alcuni problemi di fondo che, tuttavia, tenderanno a essere superati con l’utilizzo sempre più intensivo dei modelli stessi. Ci è capitato, ad esempio, che i nuovi modelli di Perplexity non riportassero (a un primo tentativo) un recente risultato sportivo, che facessero informazioni sciocche o che mal interpretassero delle classifiche. Utilizzando l’italiano, inoltre, il modello tende occasionalmente a restituire errori grammaticali o a formulare costruzioni delle frasi poco convincenti.
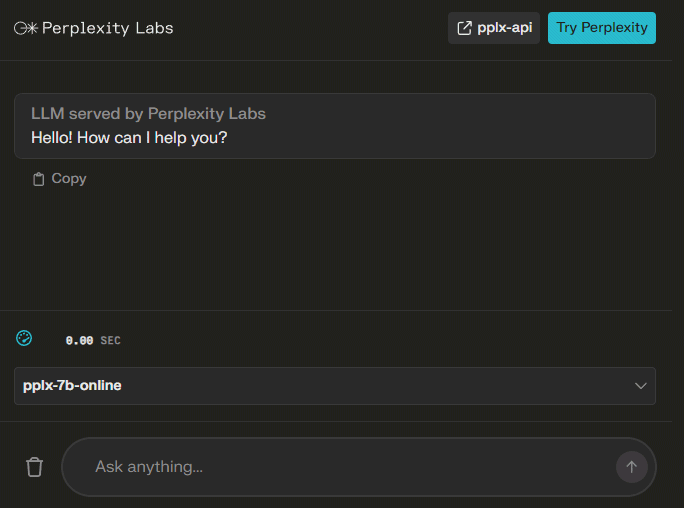
Come mettere alla prova i nuovi modelli
Se anche voi voleste provare i nuovi modelli generativi, è sufficiente fare riferimento al Perplexity Labs Playground. Il menu a tendina in basso a destra consente di selezionare il LLM che si preferisce utilizzare: quelli che presentano il suffisso “online” nel nome sono ovviamente progettati per avere maggiore visibilità sui contenuti recenti, fatti di cronaca compresi. I riferimenti “7b” e “70b” indicano il numero di miliardi di parametri utilizzati da Perplexity nella fase di addestramento.
Una volta inserita nel campo Ask anything la descrizione di ciò che si desidera ottenere, i modelli iniziano subito l’elaborazione dell’input fornendo anche alcuni dati statistici come il numero di token utilizzati, il tempo necessario per il computing (espresso in token per secondo) e la durata dell’operazione.
Disponibilità delle API per l’integrazione nei propri progetti
Le nuove pplx-api, messe a disposizione da Perplexity, consentono di collegare i modelli generativi con le proprie applicazioni. Gli sviluppatori possono quindi avvalersi delle apposite API (Application Programming Interfaces) per arricchire le proprie applicazioni di funzionalità evolute basate sull’intelligenza artificiale.
Con pplx-api il programmatore può accedere anche ai modelli pplx-7b-online e pplx-70b-online per generare risposte a domande specifiche. Grazie alla natura “online” di questi modelli, l’API consente di sfruttare conoscenze aggiornate acquisite dalla rete per rispondere in modo più preciso e attuale.
Gli utenti del piano Perplexity Pro possono beneficiare di 5 dollari di credito gratuito ogni mese, utili per provare le potenzialità delle API e dei modelli. Il prezzo del canone vero e proprio, invece, varia a seconda del volume di dati elaborato: si parte da 7 e 28 centesimi, rispettivamente in input e output, per 1 milione di token nel caso del modello più leggero da 7 miliardi di parametri.
Nel caso dei più recenti modelli “online”, invece, Perplexity non applica alcun costo per la gestione dei token in input mentre chiede 5 dollari ogni 1.000 richieste e 28 centesimi per 1 milione di token prodotti in output.
Credit immagine in apertura: iStock.com/da-kuk
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")