/https://www.ilsoftware.it/app/uploads/2024/03/cerebras-WSE-3-chip-piu-grande-IA.jpg "Il chip più potente per l'IA è di Cerebras: 900mila core, 125 PetaFLOPS")
Cerebras, azienda californiana specializzata nella progettazione e realizzazione di supercomputer basati destinati a supportare applicazioni incentrate sull’intelligenza artificiale, ha annunciato il lancio della sua nuova generazione di chip IA. Promettono prestazioni doppie rispetto alla generazione precedente consumando la stessa quantità di energia.
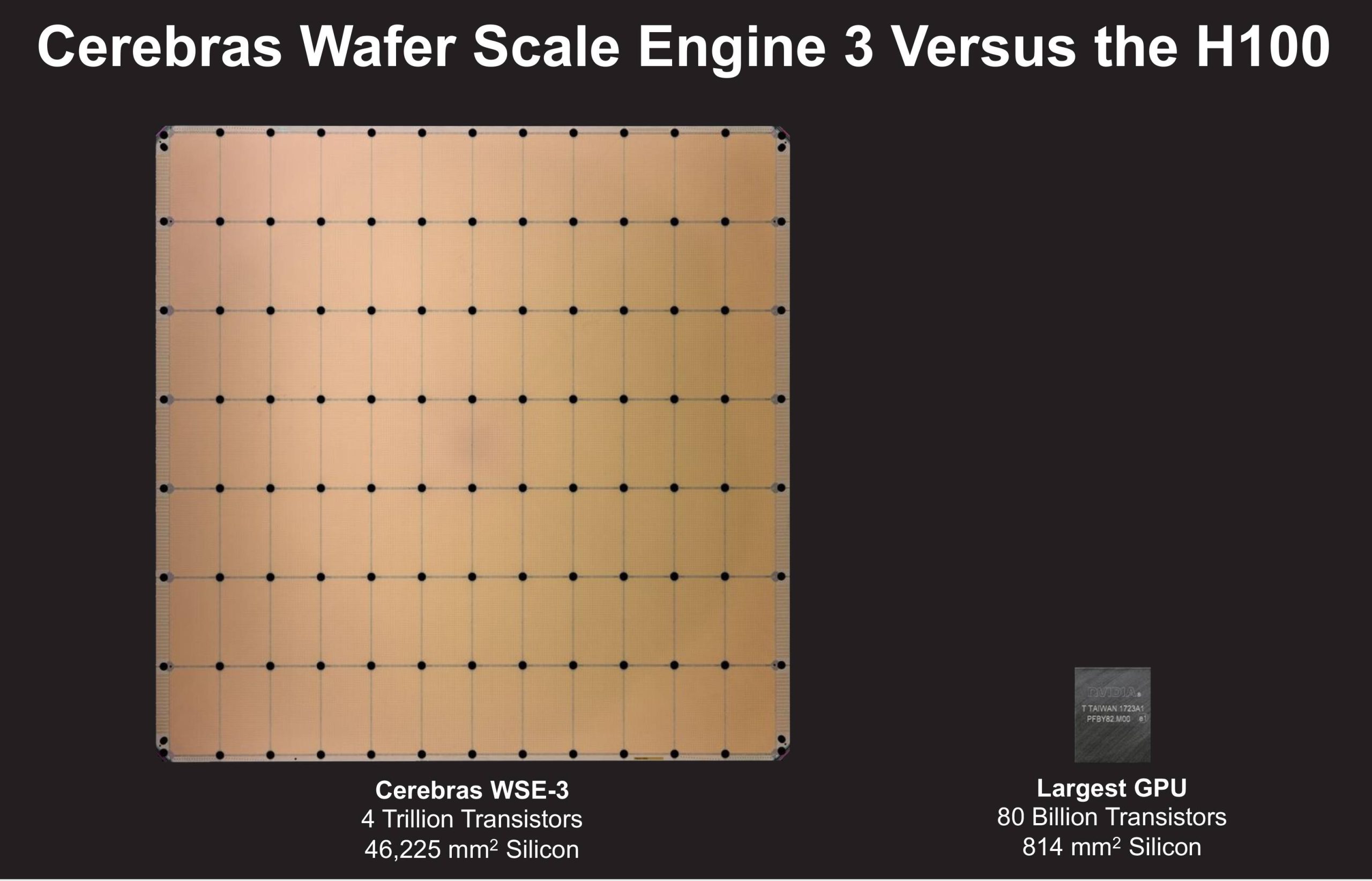
Battezzato WSE-3 (Wafer Scale Engine 3), il chip ha una forma quadrata di 21,5 centimetri per lato e si serve quasi di un intero wafer di silicio da 300 millimetri per produrre un unico esemplare. Cerebras mantiene così il suo primato nella produzione del chip di dimensioni più grandi in assoluto.
In termini di transistor, WSE-3 ne contiene 4.000 miliardi, con un aumento di oltre il 50% rispetto alla generazione precedente, grazie all’utilizzo di tecnologie di produzione più evolute rispetto al passato. Un singolo chip, inoltre, conta ben 900.000 core ed è in grado di esprimere una potenza pari a 125 PetaFLOPS.
Cosa cambia con WSE-3, il chip più potente di Cerebras per l’intelligenza artificiale
Innanzi tutto, Cerebras sembra seguire la legge di Moore: il primo chip dell’azienda ha debuttato nel 2019 e fu realizzato usando un processo costruttivo a 16 nm di TSMC. WSE-2 è arrivato nel 2021, con il processo a 7 nm TSMC mentre WSE-3 si è spinto ancora più in là in termini di miniaturizzazione arrivando a 5 nm.
Il numero di transistor è più che triplicato dal primo megachip a marchio Cerebras. Si è registrato anche un netto miglioramento in termini di memoria on-chip e larghezza di banda: WSE-3 utilizza 44 GB, ha una banda della memoria pari a 21 Petabyte/s e può impegnare fino a 214 Petabit/s in termini di interconnessione. Il balzo in avanti fatto registrare in termini di operazioni in virgola mobile al secondo (PetaFLOPS) ha tuttavia superato tutti gli altri valori.
Ecco quindi che WSE-3 è già in fase d’installazione presso un data center situato a Dallas (Texas, USA): andrà a sostenere il funzionamento di un supercomputer capace di elaborare ben 8 ExaFLOPS. Soltanto a giugno 2023 si iniziava a parlare di “generazione ExaFLOP” e adesso Cerebras svela una chip in grado di gestire qualcosa come 8 * 1018 operazioni in virgola mobile al secondo, ovvero un 8 seguito da ben 18 zeri.
All’atto pratico, WSE-3 può essere utilizzato per addestrare modelli generativi in grado di poggiare su 24.000 miliardi di parametri, un valore che fa impressione se confrontato con quello dei LLM (Large Language Models) più “imponenti” (fino a 1.500 miliardi di parametri).
CS-3 è il supercomputer costruito con il nuovo chip AI
I portavoce di Cerebras spiegano che il supercomputer in fase di lancio a Dallas utilizzerà 64 nuovi chip, combinati per formare un unico sistema CS-3. Basti pensare che è possibile accoppiare fino a 2.048 WSE-3 per estendere significativamente le abilità computazionali di ciascun sistema.
Teoricamente, un singolo chip WSE-3 sarebbe equivalente, per le operazioni legate all’intelligenza artificiale a 62 GPU NVIDIA H100.
Addestrare un LLM ampiamente utilizzato come Llama 70B da zero richiederebbe così appena un giorno di tempo. Il termine “70B” si riferisce al numero di parametri presenti nel modello ovvero ai “pesi” assegnati ai nodi all’interno della rete neurale artificiale durante il processo di addestramento. Sono essenziali per il funzionamento del modello, in quanto influenzano la capacità della rete neurale di apprendere e generare output accurati.
L’accordo con Qualcomm
Sebbene i computer Cerebras siano progettati per ottimizzare e velocizzare le fasi di addestramento, il CEO di Cerebras Andrew Feldman sostiene che il vero limite consista nei meccanismi di inferenza, ovvero il momento in cui il modello generativo è effettivamente eseguito.

Secondo le stime dell’azienda, se ogni persona sul pianeta utilizzasse ChatGPT, si dovrebbero scontare costi nell’ordine di 1.000 miliardi di dollari l’anno, senza contare la quantità immensa di energia richiesta. E i costi operativi sono ovviamente proporzionali alle dimensioni del modello e al numero di utenti che se ne servono.
Cerebras e Qualcomm hanno stretto una collaborazione che ha come obiettivo quello di iniziare a ridurre il costo dell’inferenza di un fattore di 10. La soluzione adottata comporterà l’applicazione di tecniche “ad hoc” per comprimere i pesi e rimuovere le connessioni non necessarie.
Le reti addestrate da Cerebras saranno poi supportate, ad esempio, dal chip Qualcomm AI 100 Ultra, specializzato proprio nelle attività di inferenza.
Le immagine pubblicate nell’articolo sono tratte dal sito ufficiale di Cerebras.
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")
/https://www.ilsoftware.it/app/uploads/2024/07/chip-IA-openai.jpg "OpenAI lancia Flex Processing: rivoluzione dei costi API per modelli AI")
/https://www.ilsoftware.it/app/uploads/2025/04/grok-lg-ai-emotiva-pubblicita.jpg "LG lancia l'AI emotiva sulle Smart TV: pubblicità su misura per i tuoi sentimenti")