/https://www.ilsoftware.it/app/uploads/2024/07/graphrag-intelligenza-artificiale-grafi.jpg "GraphRAG rivoluziona l'IA con la generazione di risposte basata su grafi")
RAG, acronimo di “Retrieval-Augmented Generation“, è una tecnica utilizzata nell’ambito dell’elaborazione del linguaggio naturale (NLP) per migliorare la qualità delle risposte prodotte dai modelli generativi. Come abbiamo spiegato nell’articolo dedicato a come portare l’intelligenza artificiale in azienda con RAG, il sistema seleziona i frammenti di testo che sono semanticamente più simili alla domanda posta dall’utente.
Dopo aver recuperato informazioni pertinenti (ad esempio da un corpus di documenti disponibili in azienda), il modello di linguaggio utilizza questi dati per generare una risposta. L’idea alla base di RAG è sfruttare la versatilità dei modelli di linguaggio nel generare testo fluido e comprensibile, combinata con la capacità del sistema di recupero nell’individuare e fornire dati precisi e pertinenti. L’approccio è particolarmente utile quando si lavora con dataset vasti, complessi e molto specifici: si pensi al materiale prodotto a valle di anni di ricerca e sviluppo all’interno di un’impresa. In questi frangenti, il semplice utilizzo dei Large Language Model (LLM) “generalisti” non è generalmente sufficiente per ottenere risposte accurate e complete.
GraphRAG
La soluzione rappresentata dall’approccio RAG è, nel caso di Microsoft GraphRAG, ulteriormente potenziato ricorrendo ai cosiddetti “grafi di conoscenza”, che organizzano le informazioni in strutture semantiche complesse, permettendo risposte più precise e contestualmente rilevanti.
I ricercatori e gli sviluppatori dell’azienda di Redmond hanno appena condiviso il codice sorgente di GraphRAG su GitHub: in questo modo gli utenti possono toccare con mano i vantaggi della soluzione. Non solo. GraphRAG Accelerator, anch’esso pubblicato su GitHub, si presenta come strumento utile per avvalersi dello strumento sulla piattaforma Microsoft Azure. In questo modo, è possibile utilizzare GraphRAG senza necessità di scrivere codice.
Come funziona GraphRAG
GraphRAG utilizza un LLM per automatizzare l’estrazione di un grafo di conoscenza da qualsiasi collezione di documenti testuali. Una delle caratteristiche più interessanti di questo indice di dati basato su grafi è la sua capacità di riportare la struttura semantica dei dati prima di qualsiasi query dell’utente. Questo avviene rilevando “comunità” di nodi densamente connessi in modo gerarchico, partizionando il grafo su vari livelli, dai temi di alto livello agli argomenti di basso livello.
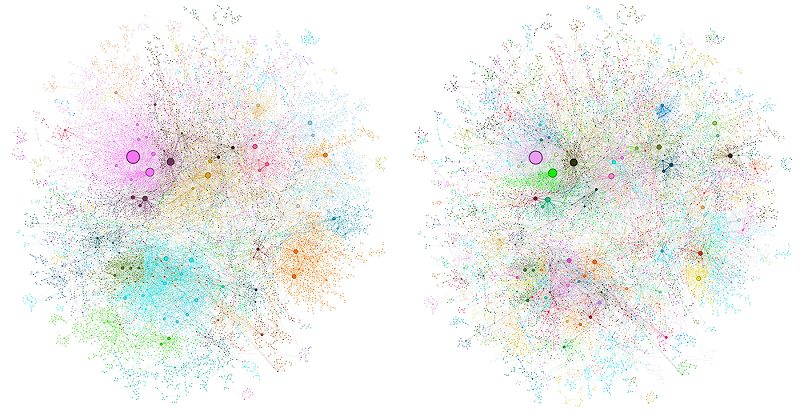
Nel caso specifico, Microsoft ha utilizzato un dataset di notizie esemplificativo, ma lo stesso principio è ovviamente applicabile su qualunque insieme di dati.
Utilizzando un LLM, si crea un sommario gerarchico dei dati, fornendo una panoramica di un dataset senza bisogno di conoscere in anticipo quali domande porre. Ogni comunità serve come base per un sommario della comunità che descrive entità e relazioni.
Gli esperti di Microsoft sottolineano che GraphRAG si comporta bene nel fornire risposte a domande globali, che riguardano l’intero dataset piuttosto che specifici frammenti di testo. Prendiamo ad esempio la domanda “quali sono i temi principali contenuti nel dataset?” È un punto di partenza ragionevole ma i RAG tradizionali, basati sulla ricerca vettoriale, spesso falliscono offrendo risposte fuorvianti. Perché? Perché un RAG considera solo i primi “n” frammenti di testo più simili mentre invece la visione dovrebbe essere molto più d’insieme.
Risultati davvero incoraggianti
I risultati pubblicati da Microsoft mostrano che GraphRAG, utilizzando sommari di comunità a qualsiasi livello della gerarchia, supera i RAG tradizionali in termini di completezza e diversità (risulta migliore nel 70-80% delle situazioni).
La soluzione proposta dall’azienda di Redmond si rivela anche più prestazionale, risultando quindi meno costosa grazie al numero di token inferiore che viene elaborato.
Seppur vi siano ancora notevoli margini di miglioramento, GraphRAG si configura come un eccellente punto di partenza e, soprattutto, non è un progetto ad uso interno. Da oggi, infatti, tutti gli utenti possono metterlo alla prova usando i propri set di dati.
/https://www.ilsoftware.it/app/uploads/2023/12/Wikipedia-generico.jpg "Wikipedia rilascia i suoi dati per salvarsi dai Bot")
/https://www.ilsoftware.it/app/uploads/2024/11/1-1.jpg "Meta blocca Apple Intelligence su Instagram e WhatsApp: cosa sta succedendo?")
/https://www.ilsoftware.it/app/uploads/2025/04/codex-cli-openai-cos-e-come-funziona.jpg "Codex CLI: cos'è l'agente AI di OpenAI che scrive e interpreta codice dal terminale")
/https://www.ilsoftware.it/app/uploads/2023/09/1-110.jpg "OpenAI: nuovo sistema di monitoraggio per prevenire rischi biologici")