/https://www.ilsoftware.it/app/uploads/2024/06/GPT-4o.jpg "GPT-4o: come funziona il processo di codifica e riconoscimento delle immagini")
Le applicazioni di visione artificiale non sono nuove ma con l’avvento dei modelli più evoluti, basati sull’intelligenza artificiale generativa, esse diverranno sempre più performanti e “all’ordine del giorno”. GPT-4o (la “o” finale sta per “omni”) è il più avanzato modello di linguaggio multimodale sviluppato da OpenAI e presentato il 13 maggio 2024. Si tratta di un’evoluzione significativa rispetto alle versioni precedenti, in grado di gestire e integrare input e output di testo, audio e immagini in tempo reale.
Il riferimento a “omni” indica proprio la natura multimodale del modello: GPT-4o può “comprendere” e generare risposte basate su vari tipi di input, rendendo l’interazione con l’intelligenza artificiale molto più naturale e intuitiva.
Tra le principali caratteristiche di GPT-4o ricordiamo una finestra di contesto (context window) di dimensioni pari a 128K token, la possibilità di elaborare fino 10 milioni di token al minuto, una “base di conoscenze” (dati di addestramento) aggiornata a ottobre 2023.
Il funzionamento del processo di codifica e tokenizzazione delle immagini
Dicevamo in apertura che la tendenza di OpenAI e di altre realtà concorrenti non è più quella di far crescere vertiginosamente il numero dei parametri. L’obiettivo è adesso quello di sviluppare e migliorare modelli capaci di elaborare correttamente più tipologie di contenuti. Nel caso dei Large Language Model (LLM) più evoluti come GPT-4o, questi non si limitano in più al linguaggio naturale ma estendono le loro abilità alle immagini e, in generale, agli elementi multimediali.
Oran Looney, sviluppatore e ricercatore, ha condotto una serie di verifiche approfondite per capire il comportamento di GPT-4o nella gestione delle immagini. Come funzionano i processi di codifica e tokenizzazione?
Quando GPT-4o riceve in input un’immagine ad alta risoluzione, la suddivide in riquadri di 512×512 pixel, ognuno dei quali consuma 170 token. Questo numero, apparentemente arbitrario, ha portato Looney a indagare sul motivo per cui OpenAI ha scelto proprio 170 token per riquadro.
La sua ipotesi è che ogni riquadro sia convertito in un vettore composto da 170 caratteristiche. Un approccio evidentemente più efficiente per i modelli di deep learning come GPT-4o, che trovano più facile lavorare con vettori in uno spazio multidimensionale piuttosto che processare direttamente le informazioni dei singoli pixel.
La conversione in uno spazio vettoriale
Alla data in cui scriviamo questo articolo, GPT-4o è l’ultima incarnazione di un modello Generative pre-trained transformer (GPT). Nell’articolo dedicato a cosa sono i modelli GPT, abbiamo visto che il loro segreto consiste nel trasformare l’input in vettori numerici (embedding), utili a rappresentare il significato delle parole nel contesto in cui esse sono utilizzate.
La tokenizzazione è il processo fondamentale che consiste nella suddivisione del testo (nel caso del linguaggio naturale) in unità più piccole chiamate token. Un token non necessariamente consiste a una singola parola ma si tratta di una semplificazione spesso adottata per rendere più comprensibile il funzionamento dei modelli.
Looney spiega che con GPT-4o il concetto di token e il processo di tokenizzazione sono applicati anche sulle immagini. I token testuali sono convertiti in vettori embedding prima di essere elaborati dal modello. Questo processo è cruciale per qualsiasi tipo di dato che vogliamo inserire in un transformer, dati visivi inclusi.
Lo dice OpenAI stessa: per ogni “piastrella” delle dimensioni di 512×512 pixel, l’azienda guidata da Sam Altman addebita all’utente l’uso di 170 token. Considerando un fattore 0,75 token per parola, questo significa che una singola immagine da 512×512 pixel equivale a circa 227 parole.
Secondo Looney, GPT-4o potrebbe utilizzare una rete neurale convoluzionale (CNN) per codificare le immagini. La CNN in questione potrebbe trasformare un’immagine di 512×512 pixel in una griglia di vettori embedding 13×13 pixel. Stando ai test effettuati, GPT-4o migliorerebbe significativamente le sue prestazioni spingendosi fino all’uso di griglie 5×5 pixel. In questo modo il modello è capace di raccogliere informazioni su un’immagine sia a livello globale che locale.
Mettete alla prova GPT-4o con immagini complesse
Il modo più semplice per accedere a GPT-4o, consiste nell’usare ChatGPT. Anche gli utenti del chatbot in versione gratuita possono usare di default GPT-4o per gestire un numero limitato di richieste su base giornaliera. Superata la “soglia” fissata da OpenAI, gli utenti del piano free di ChatGPT torneranno a usare automaticamente GPT-3.5.
Cliccando sull’icona raffigurante una piccola graffetta, abbiamo passato a ChatGPT/GPT-4o questa immagine pubblicata su Unsplash. Abbiamo quindi chiesto all’intelligenza artificiale di OpenAI
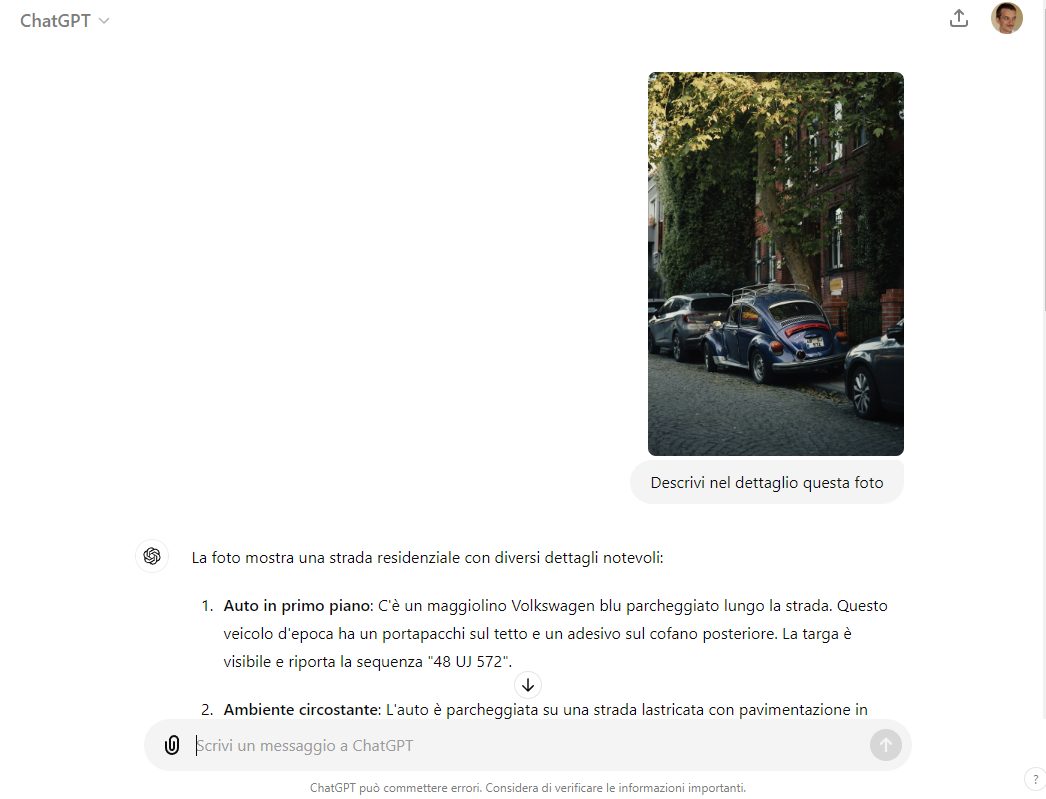
Come si vede nell’immagine, GPT-4o non solo ha riconosciuto il modello dell’auto fotografata ma ha fornito una serie di indicazioni sulle sue caratteristiche. Ha ancora rilevato il numero di targa, grazie al motore OCR integrato.
Il sistema di riconoscimento ottico dei caratteri (OCR), infatti, si comporta sorprendentemente bene. Tanto da far sostenere a Looney che per questa specifica necessità, OpenAI potrebbe aver integrato un motore OCR di terze parti. I meccanismi basati sull’intelligenza artificiale non sono infatti particolarmente abili nel riconoscimento dei dati presenti nelle immagini: GPT-4o è invece perfettamente capace di leggere testi complessi e trascriverne interi blocchi in modo preciso.

Chiedendo dove è stata scattata la foto oltre a maggiori informazioni sulla targa dell’auto, GPT-4o non solo ha ipotizzato che lo scatto arrivi dalla Turchia (come peraltro confermato dell’autore dell’immagine) ma ha fornito indicazioni corrette sul numero di targa.
L’analisi di Looney apre la strada a ulteriori ricerche su come i modelli di AI avanzati quali GPT-4o processano le immagini, evidenziando la complessità e le potenzialità di queste tecnologie. La comprensione approfondita di questi meccanismi contribuirà a introdurre miglioramenti significativi nell’elaborazione delle immagini e in molte altre applicazioni basate sull’utilizzo dell’intelligenza artificiale.
L’immagine in apertura è tratta da OpenAI.
/https://www.ilsoftware.it/app/uploads/2024/05/UALink-intelligenza-artificiale-data-center.jpg "Stargate arriva in UK: previsti investimenti miliardari")
/https://www.ilsoftware.it/app/uploads/2024/06/claude-35-sonnet-modello-generativo.jpg "Anthropic Claude ora può cercare sul web e tra le nostre email")
/https://www.ilsoftware.it/app/uploads/2024/12/2-3.jpg "OpenAI introduce libreria immagini per ChatGPT accessibile a tutti")
/https://www.ilsoftware.it/app/uploads/2025/04/microsoft-copilot-studio-computer-use.jpeg "L'AI di Microsoft ora può usare il computer al posto nostro")