/https://www.ilsoftware.it/app/uploads/2024/02/magika-riconosce-formati-file-tipo.jpg "Google Magika riconosce i file in un battito di ciglia, grazie all'IA")
Sin dagli albori dell’informatica, rilevare con precisione i tipi di file con i quali si ha a che fare è risultato cruciale in molteplici contesti. Linux è dotato di libmagic, una libreria che integra funzionalità di identificazione dei tipi di file, spesso utilizzata per determinare il tipo di contenuto di un file basandosi sulla sua struttura e sulle prime porzioni di dati binari. In sostanza, libmagic aiuta a riconoscere il formato di un file analizzando i byte iniziali del file stesso ovvero il suo header (intestazione).
Quando si deve riconoscere la tipologia di un file non è mai bene fermarsi alla sua estensione: la presenza di un .pdf, .docx, .txt e così via potrebbe non rappresentare davvero ciò che contiene il file. Prima di parlare di file danneggiati, è bene verificarne il formato con la massima attenzione.
Il problema dell’identificazione del tipo di ciascun file
Sistemi operativi, browser web, editor di codice e innumerevoli altri software si affidano al rilevamento del tipo di file per decidere come gestire un oggetto. Ad esempio, gli editor di codice moderni utilizzano il rilevamento del tipo di file per scegliere quale schema di evidenziazione della sintassi devono attivare. L’approccio, infatti, cambia a seconda del linguaggio di programmazione.
Fino ad ora, libmagic e la maggior parte degli altri software di identificazione dei tipi di file hanno fatto affidamento su una raccolta di regole euristiche e soluzioni personalizzate per rilevare ciascun formato di file. Si tratta di un modus operandi dispendioso e soggetto a errori perché è complicato mettere a punto regole che si applichino a un ampio ventaglio di situazioni.
Google Magika, il rilevatore di file alimentato dall’intelligenza artificiale
Per affrontare il problema e fornire un’identificazione rapida e accurata di ogni genere di file, Google ha sviluppato Magika. Questa pagina dimostrativa, appositamente preparata per mostrare il funzionamento del nuovo strumento, rende palesi le abilità di Magika.
Il sistema progettato e realizzato dai tecnici della società di Mountain View aiuta a riconoscere tipi di file binari e testuali nel giro di una manciata di millisecondi, anche quando eseguito in locale appoggiandosi a una “semplice” CPU, senza quindi ricorrere a una GPU.
Magika sfrutta un modello di deep learning personalizzato e altamente ottimizzato, a sua volta addestrato ricorrendo a Keras (pesa solamente 1 MB circa). Per l’attività di inferenza (processo di applicazione di un modello già addestrato per fare predizioni o classificazioni su nuovi dati), Magika poggia su Onnx (Open Neural Network Exchange), un formato di file e un’ecosistema presentato da Microsoft e Facebook nel 2017 che consente di creare, addestrare e distribuire modelli di intelligenza artificiale (AI) in modo interoperabile tra diversi framework e piattaforme.
Ne avevamo parlato nell’articolo dedicato a come togliere lo sfondo da un’immagine usando una libreria open source e l’intelligenza artificiale.
Come provare Magika, da Web o utilizzando codice Python
È possibile provare oggi la demo Web di Magika o installarlo come libreria Python, con la possibilità di usare lo strumento anche dalla riga di comando. Basta impartire il comando pip install magika.
Dal punto di vista delle prestazioni, Magika, grazie al suo modello di intelligenza artificiale e al grande set di dati di allenamento, è in grado di superare gli altri strumenti esistenti di circa il 20%. Il giudizio finale, condiviso da Google, fa riferimento su verifiche condotte su un totale di 1 milione di file che includono oltre 100 tipi di file.
Quando manca l’estensione di un file, per riconoscerlo e risalire alla sua tipologia abbiamo in passato presento l’utilità TrID. Se si esamina la tabella pubblicata da Google, Magika surclassa tutti i “concorrenti” nel corretto rilevamento dei file, TrID compreso. Il divario si fa più marcato quando si tratta di analizzare file di testo, codice di programmazione e file di configurazione, tutti elementi con con cui altri strumenti possono avere difficoltà.
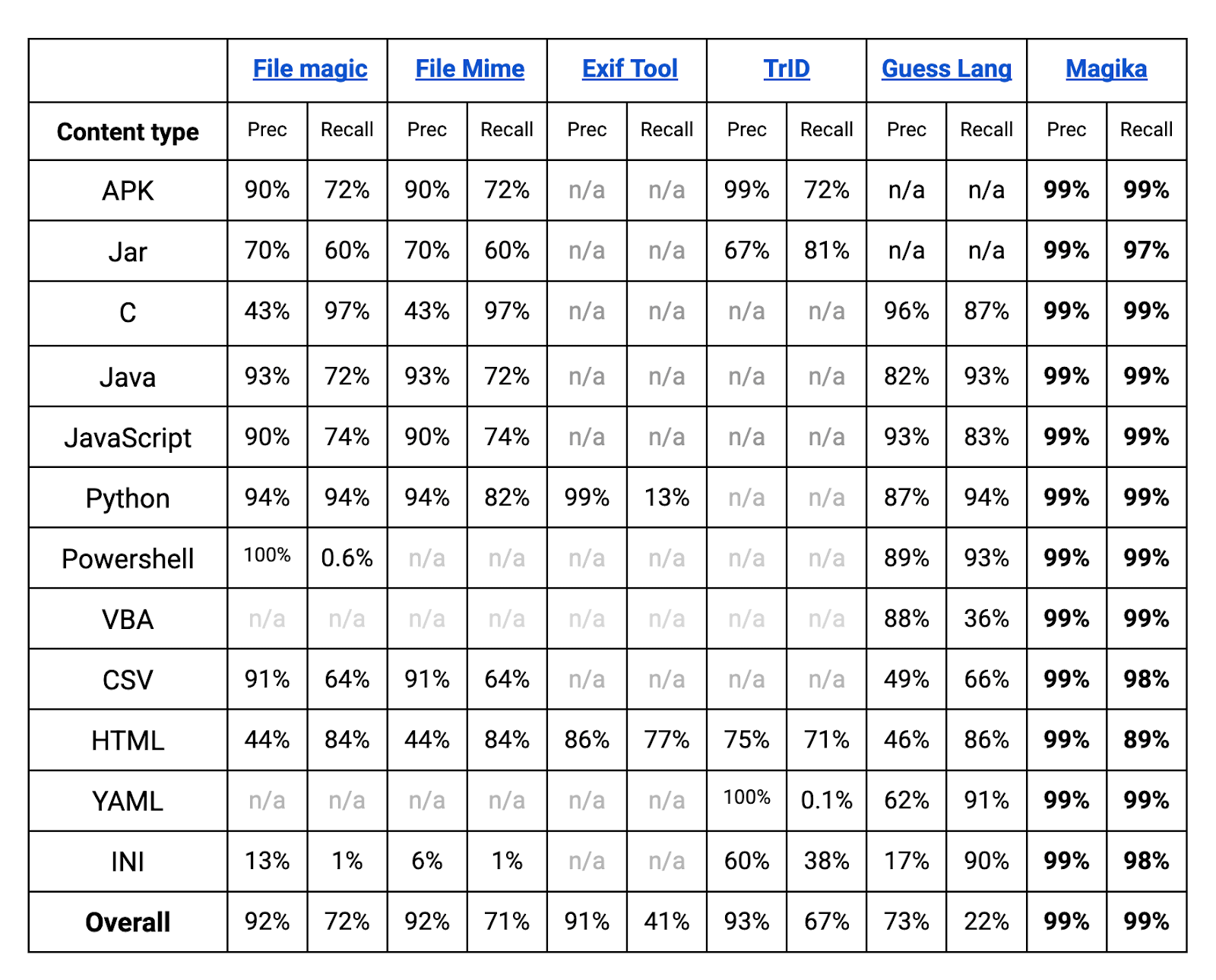
A cosa serve e servirà Google Magika
Google sta già utilizzando Magika su larga scala per migliorare la sicurezza degli utenti rilevando il contenuto degli allegati di posta su Gmail, dei file pubblicati su Drive, per migliorare il comportamento di Safe Browsing a livello di browser Web.
A breve Magika sarà integrato anche con VirusTotal andando a completare la funzionalità Code Insight della piattaforma, che utilizza l’IA generativa di Google per analizzare e rilevare codice dannoso. Magika fungerà da prefiltro prima che i file siano analizzati da Code Insight, migliorando l’efficienza e l’accuratezza dei responsi prodotti dalla piattaforma.
Trattandosi tuttavia di un prodotto open source distribuito sotto licenza Apache2 (il codice sorgente è pubblicato su GitHub), Magika può diventare uno strumento di uso comune – integrabile in altri software e piattaforme di terze parti – utile per migliorare l’accuratezza nell’identificazione dei file.
Credit immagine in apertura: iStock.com – Royalty Free
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")
/https://www.ilsoftware.it/app/uploads/2024/07/chip-IA-openai.jpg "OpenAI lancia Flex Processing: rivoluzione dei costi API per modelli AI")
/https://www.ilsoftware.it/app/uploads/2025/04/grok-lg-ai-emotiva-pubblicita.jpg "LG lancia l'AI emotiva sulle Smart TV: pubblicità su misura per i tuoi sentimenti")