/https://www.ilsoftware.it/app/uploads/2023/12/gigaGPT-IA-modello-generativo-cerebras.jpg "gigaGPT: un modello come GPT-3 in appena 565 righe di codice")
Cerebras è una società, della quale abbiamo spesso parlato, che si concentra sulla progettazione e sviluppo di processori per l’intelligenza artificiale (IA) e il deep learning. Fondata nel 2016 da Andrew Feldman, Cerebras ha raccolto grande interesse da parte dei big dell’industria per via della creazione di una soluzione hardware innovativa specificamente progettata per le esigenze computazionali dell’IA. L’azienda ha annunciato oggi la disponibilità di gigaGPT, presentata come la più semplice e compatta soluzione per l’addestramento e l’ottimizzazione dei modelli generativi.
Cos’è gigaGPT e come funziona
Gli sviluppatori di Cerebras spiegano di aver utilizzato, come base di partenza, il modello nanoGPT di Andrej Karpathy, membro fondatore di OpenAI e vero e proprio pezzo da novanta nell’ambito delle soluzioni di intelligenza artificiale.
Mentre nanoGPT, pubblicato su GitHub, può addestrare modelli che usano fino a 100 milioni di parametri, gigaGPT è progettato per addestrare modelli con oltre 100 miliardi di parametri. La particolarità di gigaGPT risiede nel fatto che raggiunge questi risultati senza introdurre ulteriore codice o fare affidamento su framework di terze parti. L’intero repository è infatti costituito da appena 565 righe di codice.
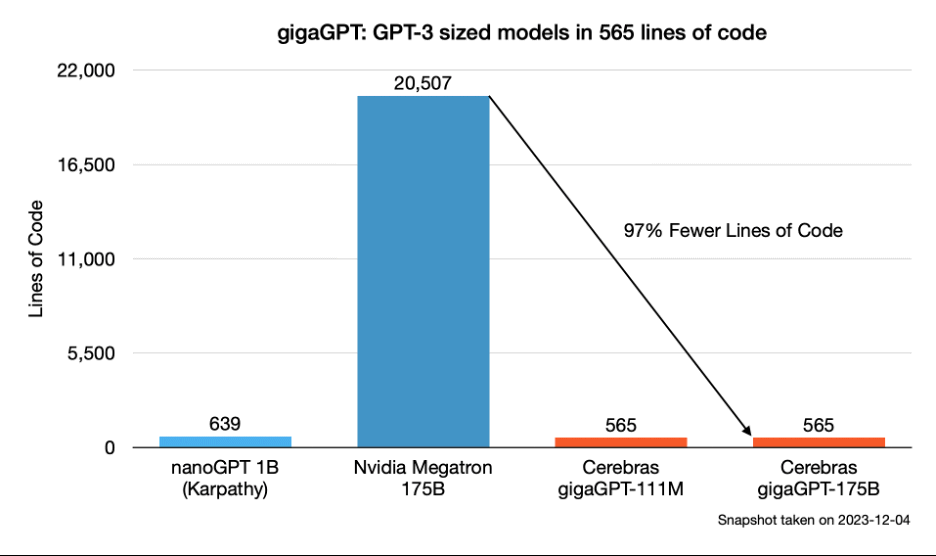
L’architettura di un transformer (abbiamo visto nel dettaglio di che cosa si tratta) è semplice; addestrare un transformer di grandi dimensioni su un gran numero di GPU è cosa decisamente più complessa.
Modelli basati sull’architettura GPT (Generative Pre-trained Transformer) senza modifiche o personalizzazioni significative soffrono di limitazioni in termini di memoria anche sulle GPU più performanti, quando si superano pochi miliardi di parametri. L’alternativa consiste nel frammentare i modelli in parti più piccole, distribuirli su più GPU, coordinare il carico di lavoro tra i nodi e “assemblare” i risultati. Questo processo, noto come “LLM scaling“, è complicato e richiede l’uso di framework come Megatron, DeepSpeed, NeoX, Fairscale e Mosaic Foundry. Il modello gigaGPT messo a punto dagli ingegneri di Cerebras, propone un approccio più semplice e leggero.
Un modello che trae massimo vantaggio dall’architettura dei processori Cerebras
Il prodotto principale di Cerebras si chiama Wafer Scale Engine (WSE): si tratta di un processore che si distingue per la sua dimensione straordinariamente grande. Invece di avere numerosi chip più piccoli su una singola scheda madre, WSE è essenzialmente un unico chip che copre l’intera superficie di una lastra di silicio o wafer. Questo approccio consente di ridurre al minimo i tempi di comunicazione tra i chip, migliorando le prestazioni per i carichi di lavoro a elevata parallelizzazione, tipici della fase di addestramento dei modelli di machine learning.
L’obiettivo dichiarato di Cerebras è quello di accelerare i progressi nel campo delle soluzioni di intelligenza artificiale fornendo una piattaforma hardware sulla quale sia possibile eseguire operazioni di calcolo avanzate in modo più efficiente rispetto alle architetture tradizionali.
La struttura del modello gigaGPT, in breve
gigaGPT non fa uso di tecniche di sharding o pipelining poiché il modello si adatta completamente alla memoria del sistema Cerebras. I cluster Wafer Scale di Cerebras consistono da 1 a 192 sistemi Cerebras CS-2, supportati da nodi server CPU che memorizzano parametri, dati e un interconnettore (SwarmX).
Lo sharding si riferisce alla suddivisione di un grande insieme di dati o di un modello in porzioni più piccole (shard): ogni shard rappresenta una parte del carico di lavoro complessivo. Il pipelining è una tecnica in cui le diverse fasi di un processo vengono eseguite simultaneamente, con l’output di una fase che diventa l’input per la successiva.
Il modello appena svelato dai tecnici Cerebras, è principalmente composto dai file Python model.py e train.py. Utilizza le primitive di PyTorch, popolare framework open source per il machine learning e il deep learning sviluppato da Facebook AI Research lab (FAIR), senza l’uso di complesse librerie esterne.
Il loop di addestramento è gestito da cerebras_pytorch, un wrapper PyTorch personalizzato, specializzato per l’esecuzione sui sistemi Cerebras. La gestione dei dati è affidata a due componenti “ad hoc” (cstorch.utils.data.DataLoader e cstorch.utils.data.DataExecutor), che coordinano la distribuzione dei dati e le operazioni di addestramento sui sistemi Cerebras.
gigaGPT è pubblicato, sotto forma di prodotto open source, nel repository GitHub ufficiale.
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")