/https://www.ilsoftware.it/app/uploads/2023/12/traceroute-tracert.jpg "Traceroute: cos'è, come funziona e a che cosa serve")
Tra i comandi Windows da conoscere per le operazioni di rete, il traceroute è uno dei più utili e importanti. Il nome del comando e la sua sintassi possono variare leggermente a seconda del sistema operativo preso in esame: su macOS, Linux e nei sistemi Unix-like, ad esempio, si chiama traceroute ma in Windows è tracert.
Traceroute è uno strumento diagnostico utilizzato per tracciare il percorso che un pacchetto di dati segue attraverso una rete di computer, che può essere Internet ma anche – ad esempio – una rete locale. È fondamentale per individuare e identificare eventuali problemi nella comunicazione tra un computer e il server remoto, aiutando a determinare dove si verificano ritardi o interruzioni.
Come funziona traceroute
Il dispositivo dal quale si avvia il comando traceroute invia una serie di pacchetti Internet Control Message Protocol (ICMP) verso la destinazione indicata. Ogni pacchetto contiene un “time-to-live” (TTL) che viene inizialmente impostato su 1. Ciascun router attraverso cui passa il pacchetto, decrementa il valore TTL di un’unità: quando il TTL raggiunge zero, il router scarta il pacchetto e invia un messaggio ICMP di “time exceeded” al mittente.
Il processo di verifica svolto mediante traceroute porta ad aumentare gradualmente il valore TTL, consentendo al mittente di identificare tutti i router attraverso cui passa il pacchetto fino a raggiungere la destinazione. Il risultato è una lista sequenziale di tutti i router attraverso cui passano i pacchetti di test, insieme ai relativi tempi di risposta.
Come usare tracert in Windows
Per effettuare un traceroute in Windows, basta aprire il prompt dei comandi (ad esempio digitando cmd nella casella di ricerca quindi premendo Invio) quindi digitare tracert seguito dall’indirizzo IP o dall’indirizzo mnemonico (ad esempio google.it, www.ilsoftware.it, www.google.it e così via) del server remoto da controllare.
Il comando inizia a inviare pacchetti alla destinazione con diversi valori di TTL e registra il percorso attraverso cui passano i pacchetti.
Non tutti i router incontrati lungo il percorso rispondono alle richieste ICMP a loro dirette: in questi casi, l’utilità tracert mostra alcuni asterischi e il messaggio Richiesta scaduta sulla destra. Questo non costituisce assolutamente un problema se gli altri hop (così sono chiamati i router incontrati lungo il tragitto) rispondono in tempi brevi (pochi millisecondi).
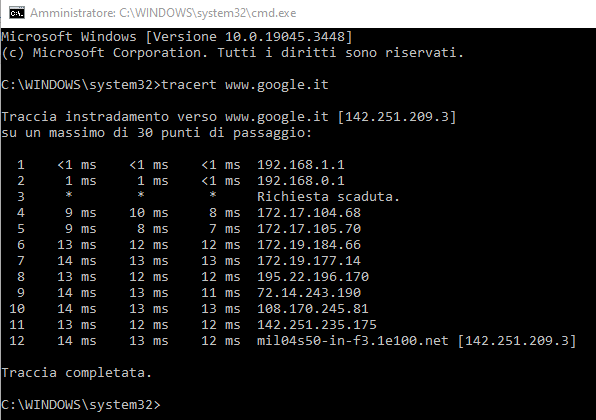
Aggiungendo l’opzione -d (esempio tracert -d www.google.it), il comando non effettua alcuna risoluzione dei nomi di dominio velocizzando il tempo di risposta complessivo dell’utilità traceroute.
Il comando seguente consente invece di forzare l’utilizzo di IPv6 anziché di IPv4:
tracert -6 google.it
Nel caso in cui IPv6 risultasse disabilitato sul sistema in uso o non fosse supportato dalla rete dell’operatore di telecomunicazioni prescelto, si ottiene un messaggio di errore.
Effettuare un traceroute su Linux
Su Linux, il funzionamento di traceroute è sostanzialmente identico. Basta digitare traceroute seguito dall’indirizzo IP o dal nome del dominio da controllare. Anche in questo caso, si può usare la sintassi tracert -n per impedire eventualmente la risoluzione dei nomi a dominio.
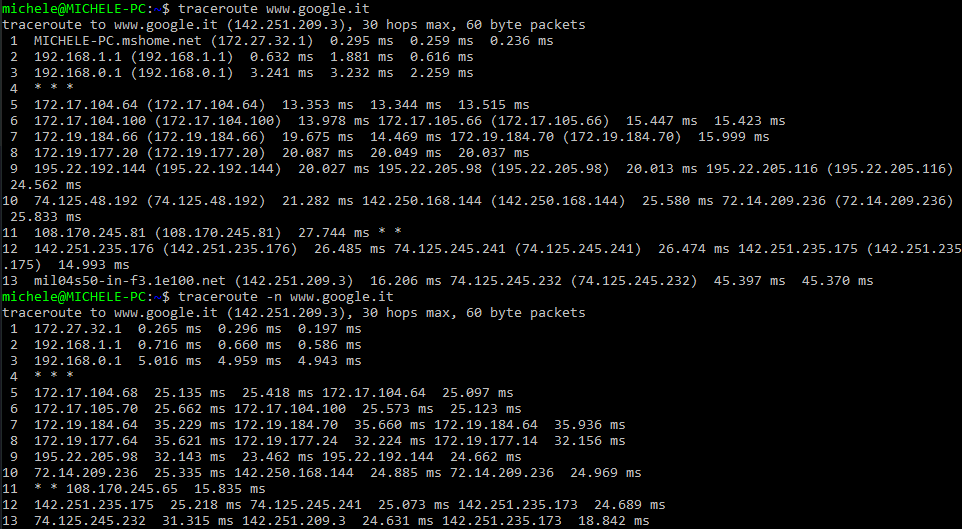
Diversamente rispetto a quanto accade in Windows, sui sistemi GNU/Linux è possibile svolgere test con traceroute anche senza utilizzare il protocollo ICMP.
ICMP, infatti, è un protocollo di comunicazione a livello di rete utilizzato per inviare messaggi di controllo e di errore all’interno di una rete IP (Internet Protocol). Il suo scopo principale, come abbiamo visto in precedenza, è quello di fornire informazioni di diagnostica sulla comunicazione tra i dispositivi di rete. Può capitare, però, che il traffico ICMP sia bloccato da uno o più hop che traceroute incontra lungo il percorso dei pacchetti dati (messaggio Richiesta scaduta).
Impartendo il comando che segue, è possibile usare il protocollo TCP anziché ICMP per effettuare le verifiche di rete:
sudo traceroute -T google.com
Ancora, in alternativa, si apuò usare il protocollo UDP:
sudo traceroute -U google.com
L’utilità traceroute consente di verificare anche una porta specifica:
sudo traceroute -p 80 google.com
È possibile ovviamente aggiungere anche l’opzione -U per usare il protocollo UDP con la porta specificata.
Matt’s traceroute
L’uso di uno strumento come traceroute è quindi particolarmente indicato quando ci sono fenomeni di perdita di pacchetti o packet loss. Il suo responso consente infatti di verificare agevolmente se il problema sia locale (ad esempio un po’ di congestione dovuta alla banda complessivamente impegnata da tutti i propri dispositivi), se dipenda dall’operatore di telecomunicazioni prescelto o se sia ancora più a monte, sulla rete Internet.
Quando è impossibile raggiungere un sito Web, uno strumento come Matt’s traceroute (MTR) è uno dei più adatti per comprendere cosa sta succedendo. Diversamente rispetto alle utilità traceroute tradizionali, infatti, MTR può essere tenuto costantemente in esecuzione per un certo periodo di tempo in modo da verificare, in tempo reale, come si comportano i vari hop.
In Linux si deve prima installare MTR. In Ubuntu e derivate si può usare il seguente comando:
sudo apt install mtr -y
I comandi seguenti effettuano, rispettivamente, un traceroute normale (via ICMP) e un traceroute sulla porta HTTPS (443):
mtr www.google.it
mtr -T -P 443 www.google.it
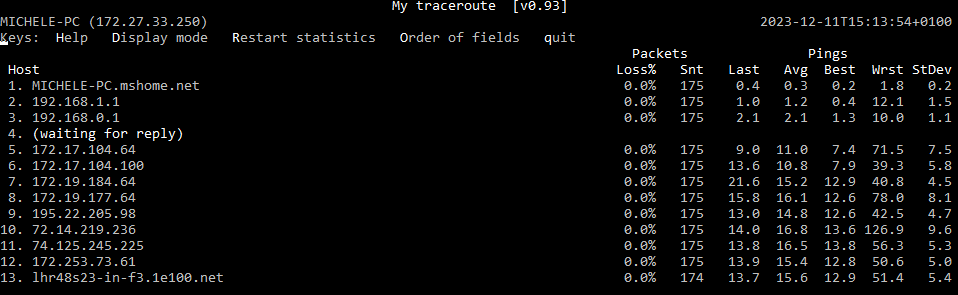
Nella figura esemplificativa, MTR ha già inviato 175 pacchetti (colonna Snt) non rilevando alcun fenomeno di packet loss (Loss%). A destra tutti tempi di risposta o latenza per ciascun hop (ultimo valore, media, valore migliore, peggiore e deviazione standard).
How did I get here? Un traceroute all’inverso
Per chi volesse approfondire, un bel progetto open source è How did I get here. Si tratta di uno strumento che mostra tutti gli hop attraversati prima di raggiungere il server di destinazione che ospita il servizio. La parte in verde del responso fornito da How did I get here è generata dinamicamente analizzando i risultati in tempo reale.
L’autore spiega di aver scritto il suo traceroute ktr in grado di trasmettere in streaming i risultati dell’analisi e allo stesso tempo cercare informazioni interessanti su ciascun hop. Sviluppato in Rust, il traceroute ktr può essere riutilizzato da parte di chiunque: il suo codice sorgente è infatti pubblicato su GitHub.
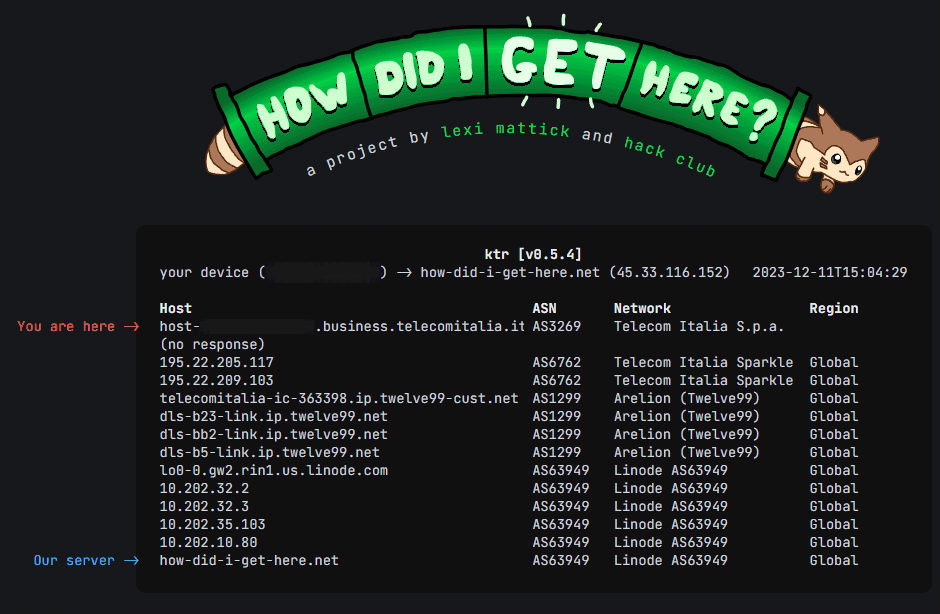
Il funzionamento dell’applicazione è davvero curioso e merita qualche considerazione in più. Aprendo il sito How did I get here con il browser Web che preferite, avrete certamente notato che il caricamento inizia a partire dall’hop finale (riga conclusiva). Il report si aggiorna quindi dal basso verso l’alto.
Il comportamento è dovuto alla scelta dello sviluppatore che ha reso compatibile il suo test con tutti i sistemi, anche quelli che hanno JavaScript disattivato. La pagina, ogni volta che aggiorna il report del traceroute, incorpora un blocco CSS che nasconde l’iterazione precedente.
Non solo. How did I get here effettua un traceroute all’inverso: la diagnosi non viene in questo caso eseguita dal dispositivo dell’utente al server remoto. È quest’ultimo che esegue un traceroute verso il dispositivo dell’utente, per poi invertire il report. Ecco perché il contenuto del traceroute sembra caricarsi in ordine inverso.
A stretto rigore, il traceroute fornito da How did I get here potrebbe non essere lo stesso che si otterrebbe effettuando il test nella direzione opposta, ad esempio con le utilità da riga di comando viste in precedenza. Alcuni nodi potrebbero assumere decisioni di routing differenti ma, in generale, la rotta seguita dovrebbe essere similare.
Sistemi autonomi e identità degli hop attraversati
La rete Internet, diversamente da ciò che alcuni pensano, è una “rete di reti” di proprietà di svariati soggetti, spesso multinazionali. Il controllo e il transito da queste reti sono regolati da transazioni finanziarie e accordi legali strettissimi.
Ogni rete, chiamata anche sistema autonomo (AS), è un insieme di router e server connessi privatamente tra loro e generalmente di proprietà della stessa azienda. I proprietari di questi sistemi autonomi stabiliscono con quali altri sistemi autonomi interconnettersi. Il traffico Internet transita quindi attraverso sistemi autonomi che hanno “accordi di peering” tra loro.
Le aziende che desiderano diventare sistemi autonomi, possono richiedere questo particolare status rivolgendosi a uno dei cinque Registri regionali che operano su scala mondiale (in Europa è il RIPE NCC, Réseaux IP Européens Network Coordination Centre).
Nel caso del servizio How did I get here, citato in precedenza, l’autore ha usato WHOIS e il database pubblico di PeeringDB per raccogliere informazioni su tutti gli hop mostrati nel report del traceroute.
I router che si trovano ai confini dei sistemi autonomi decidono a quale rete inviare successivamente il pacchetto ricevuto, finché esso non raggiunge la rete alla quale risulta fisicamente collegato il dispositivo di destinazione. Il protocollo utilizzato per questo tipo di comunicazioni si chiama Border Gateway Protocol (BGP): abbiamo già visto perché è fondamentale per il funzionamento della rete Internet. Risale al 1989, per opera degli ingegneri Cisco e IBM, la prima versione di BGP (RFC 1105).
Nel 1994 fu approvata quella che sarebbe poi diventata la versione più matura del protocollo (BGP v4); nel 1995 e nel 2006 sono state applicate alcune novità. Anche se BGP v4 è ancora il protocollo che utilizziamo per la scelta dei percorsi attraverso le reti interconnesse che compongono la moderna Internet.
Credit immagine in apertura: iStock.com/jacobius
/https://www.ilsoftware.it/app/uploads/2025/04/wp_drafter_476036.jpg "Google Fi amplia il supporto eSIM a laptop e tablet")
/https://www.ilsoftware.it/app/uploads/2025/04/Dave-Taht-QoS.jpg "Addio a Dave Täht, l'ingegnere che in silenzio ha fatto funzionare meglio le reti con il QoS")
/https://www.ilsoftware.it/app/uploads/2025/03/ILSOFTWARE-7-4.jpg "Messaggi satellitari gratis: Verizon lancia il primo servizio negli USA")
/https://www.ilsoftware.it/app/uploads/2025/03/taara-connessione-internet-laser.jpg "Connessione Internet tramite laser con Taara, Google spiega come funziona")