/https://www.ilsoftware.it/app/uploads/2024/09/sviluppo-software-chatbot-IA.jpg "Sviluppo software con i chatbot e l'intelligenza artificiale")
Siamo sempre dell’avviso che l’intelligenza artificiale (IA) non può e non deve sostituire il ruolo degli sviluppatori. Quasi agli albori dei moderni chatbot, Matt Welsh si affrettò a dichiarare, anche provocatoriamente, che la programmazione informatica è morta. Più di recente noi stessi abbiamo strenuamente criticato la posizione di Jensen Huang, CEO di NVIDIA, che diceva: “non imparate a programmare, ormai c’è l’IA“. Lo sviluppo software è invece vivo e vegeto e può già oggi trarre enormi benefici dall’uso dei modelli generativi, in termini di produttività, efficienza e miglioramento dei flussi di lavoro.
Come usare i chatbot e l’IA per lo sviluppo software
Il pioniere della programmazione Brian Kernighan osserva che le macchine, e quindi le IA, possono automatizzare molti compiti, ma è l’ingegno umano che guida l’innovazione e lo sviluppo di soluzioni uniche. Per questo, il consiglio migliore per le nuove generazioni è quello di imparare a programmare e non distogliere mai, per troppo tempo, l’attenzione da questa pratica.
Un suggerimento diametralmente opposto a quello di Huang, sì, ma a nostro avviso molto più sensato e con i piedi per terra.
Il funzionamento dei Large Language Model (LLM) è ormai piuttosto chiaro: alcuni di questi modelli non solo abili solamente a rispondere a quesiti posti usando il linguaggio naturale ma brillano nelle attività di produzione del codice di programmazione. In questo senso, GitHub Copilot ha svolto un ruolo pionieristico grazie a un modello generativo addestrato utilizzando milioni di righe di codice provenienti da progetti open source pubblicati sulla piattaforma. E di recente è nato GitHub Copilot Workspace che, facendo perno sull’IA, sovrintende l’intero ciclo di vita di qualunque software.
L’innovazione, però, non deve arrestarsi semplicemente perché vari modelli generativi utilizzano codice disponibile pubblicamente per creare codice di programmazione funzionante.
Utilizzare l’intelligenza artificiale per lo sviluppo software
Sono tanti gli strumenti che gli sviluppatori possono oggi utilizzare per generare codice e velocizzare lo sviluppo delle loro applicazioni. Visual Studio, ad esempio, integra sia IntelliCode (basato sull’IA) che GitHub Copilot mentre Visual Studio Code permette di sfruttare un ampio numero di estensioni per intervenire direttamente sul codice mentre lo si compone nell’editor. Lo abbiamo visto nelle differenze tra Visual Studio e Visual Studio Code.
Nulla vieta, però, di usare i migliori chatbot per chiedere con un prompt inviato in linguaggio naturale di creare un’applicazione, generare una routine che risolva uno specifico problema, correggere un problema nel codice già sviluppato, ottimizzarlo, migliorarlo e aggiungere direttamente nuove funzionalità.
Certo, non c’è in questo caso un collegamento diretto con l’IDE (integrated development environment) oppure con l’editor di codice ma si possono comunque ottenere risposte preziose per abbozzare lo sviluppo software di un progetto, gestire problematiche di carattere generale o sistemare quelle righe di codice che proprio non si riuscivano a far funzionare.
I rischi di affidarsi ciecamente ai modelli generativi per generare codice di programmazione
C’è però anche il rovescio della medaglia. Affidarsi ciecamente ai modelli generativi per la generazione del codice presenta rischi significativi che è fondamentale considerare. In primo luogo, la qualità del codice generato può variare notevolmente. I modelli possono produrre codice con errori di sintassi o logica, che, se non individuati, possono portare a malfunzionamenti delle applicazioni. Il rischio è particolarmente elevato nel caso dei progetti complessi: qui anche un piccolo errore può avere conseguenze di vasta portata.
I modelli generativi possono non comprendere appieno il contesto specifico di un progetto. Questa mancanza di comprensione può tradursi in soluzioni inadeguate o non ottimali, che non soddisfano i requisiti funzionali o di business.
Un altro aspetto critico riguarda la sicurezza. I modelli che non sono addestrati sulle best practice di sicurezza possono generare codice vulnerabile, esponendo le applicazioni a rischi come SQL injection o buffer overflow. Ciò è particolarmente preoccupante in un’era in cui la sicurezza informatica è diventata una priorità assoluta.
L’abbiamo detto prima e in altri articoli: la qualità delle sorgenti utilizzate per addestrare inizialmente i modelli riveste un’importanza cruciale. E la presenza di problemi nel codice di programmazione pubblicato in rete è cosa estremamente comune. Le probabilità di ritrovarsi queste deficienze nell’output generato sono quindi elevate.
Infine, va detto che se il codice generato è basato su materiali protetti da diritti d’autore, ciò potrebbe esporre le aziende a potenziali contenziosi legali.
Avanti, ma con cervello
I modelli generativi, quindi, sono un ausilio preziosissimo per lo sviluppatore ma sono necessarie competenze e un notevole bagaglio esperienziale per accertarsi che il codice generato dall’IA non presenti problemi sui vari piani.
Noi stessi abbiamo messo alla prova i principali chatbot utilizzando anche una modalità dumb: abbiamo cioè provato a richiedere lo sviluppo di un’applicazione da zero, verificando di volta in volta la qualità dei risultati ottenuti.
Programmare con ChatGPT è certamente possibile e il codice prodotto è indubbiamente di migliore qualità rispetto al passato. Le abilità di reasoning che OpenAI ha introdotto con o1 contribuiscono a migliorare ulteriormente il quadro: perché la programmazione è per eccellenza la disciplina che utilizza una logica ferrea per la risoluzione di problemi pratici.
Quanto prodotto, però, deve essere posto attentamente al setaccio: non aspettatevi di poter ottenere un’applicazione funzionante in due o tre passaggi di ChatGPT.
Piuttosto, affrontate un problema di programmazione in più passaggi e con un approccio “a blocchi“. Accertandovi sempre di che cosa ha prodotto il modello.
Come usare ChatGPT per generare codice
Per utilizzare ChatGPT e generare codice di programmazione funzionante, è possibile descrivere ciò che si desidera ottenere usando il linguaggio naturale. È però bene essere il più tecnici possibile, fornendo dettagli e, possibilmente, spunti di alto livello per la produzione del codice. È altresì importante specificare chiaramente il linguaggio da usare, esigenze e obiettivi.
Dopo la produzione del primo output, è possibile iniziare a conversare con ChatGPT indicando quali modifiche apportare al codice generato in precedenza. Con una serie di operazioni di “copia e incolla”, si può verificare il comportamento del codice lato IDE ed apportare tutte le correzioni e le migliorie necessarie.
È importante parlare con ChatGPT usando un linguaggio tecnico: chi è un programmatore ed è abituato a lavorare con cicli for, while, variabili, clausole if, funzioni, subroutine, classi e così via, può e anzi deve usare proprio questo linguaggio. Deve “fare le pulci” al codice indicando espressamente al modello generativo cosa non funziona e richiamando costrutti, variabili e strutture con i loro nomi.
In questo modo, gli output prodotti da ChatGPT tenderanno a essere qualitativamente elevati e risponderanno in maniera molto più puntuale alle specifiche esigenze del programmatore.
Cerebras Inference: lo strumento che ci ha lasciato a bocca aperta
ChatGPT talvolta tende a manifestare inutili “deviazioni dal seminato”, soprattutto quando il codice da elaborare in un sol colpo diventa lungo e complesso. I Claude Artifacts sono eccellenti ma per gli utenti in possesso di un account free le limitazioni sono piuttosto severe.
Cerebras Inference è un chatbot che fa davvero il vuoto dietro di sé. Utilizza un’architettura di base chiamata Wafer Scale Engine (WSE), un processore dedicato all’elaborazione di modelli di reti neurali. Il modello è rappresentato come una matrice di pesi e bias, memorizzati nella memoria del chip WSE.
Una volta caricato il modello, WSE esegue l’inferenza sui dati di input con un processo a elevata parallelizzazione che accelera enormemente l’esecuzione.
Utilizzando un approccio simile a quello adoperato nel caso di ChatGPT e descritto al paragrafo precedente, nel caso di Cerebras Inference lo sviluppatore si troverà dinanzi a risposte fornite in un battito di ciglia! Qualcosa di mai visto prima, almeno fino ad oggi!
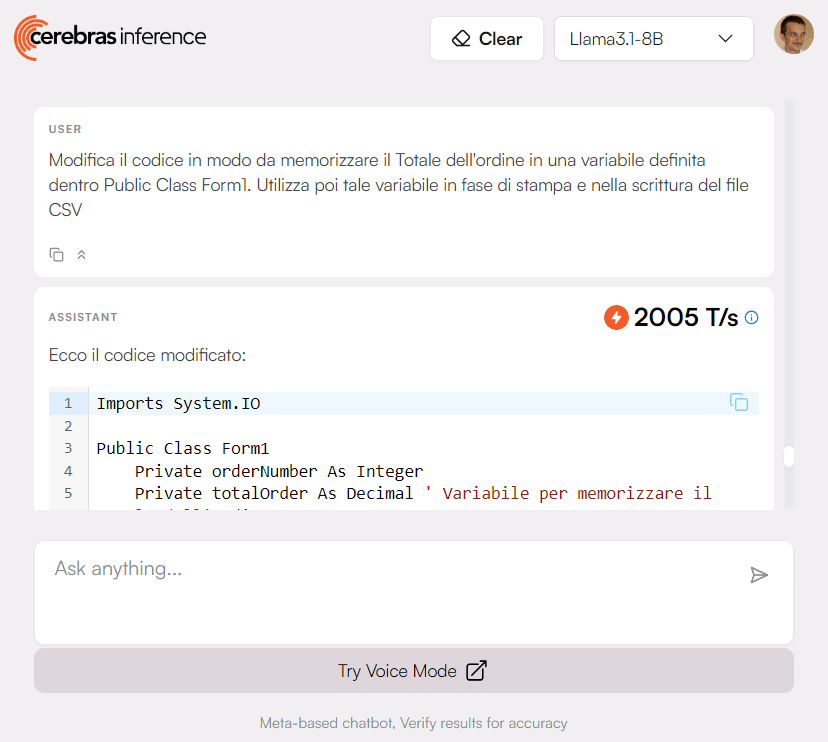
I dati parlano chiaro, per le nostre richieste complesse su vari linguaggi di programmazione, Cerebras Inference ha sempre risposto in media in circa mezzo secondo con una velocità in termini di token al secondo (t/s) pari a 8.000-10.000. Il sistema ha prodotto l’output al ritmo di oltre 2.000 t/s. Prestazioni davvero incredibili.
Ciò che fa Cerebras Inference è che tende a isolare i problemi e le sfide poste dall’utente. Quindi, al momento della generazione dell’ouput, il chatbot tende a evidenziare soltanto le modifiche da applicare sul codice preesistente.
Le API di Cerebras Inference: vi si aprirà un mondo
Il bello di Cerebras Inference è che al momento il sistema non prevede particolari limitazioni, se non nella gestione di prompt di lunghezza davvero improponibile.
Per adesso, Cerebras offre 1 milione di token gratuiti al giorno per gli sviluppatori, un incentivo goloso per testare e implementare nuove funzionalità nelle proprie applicazioni.
Le API Cerebras rappresentano una soluzione di inferenza IA a bassa latenza che offre ai developer una piattaforma per eseguire modelli generativi con prestazioni mai viste, facilitando la creazione di applicazioni complesse e innovative.
La maggior parte delle applicazioni di IA richiede una soluzione di inferenza a bassa latenza per funzionare in modo efficiente. Ciò è particolarmente vero per le applicazioni che richiedono di processare grandi quantità di dati in tempo reale, come ad esempio i sistemi di riconoscimento vocale, i sistemi di visione artificiale e quelli di previsione comportamentale.
Grazie alle API, si possono ad esempio integrare facilmente le soluzioni di inferenza Cerebras nelle proprie applicazioni. Esempi concreti sono disponibili nel repository GitHub ufficiale.
Al momento tutto questo è gratuito ed è peraltro basato sui modelli aperti Llama3.1-8B e Llama3.1-70B sviluppati da Meta.
Credit immagine in apertura: iStock.com – Userba011d64_201
/https://www.ilsoftware.it/app/uploads/2025/04/compleanno-git-20-anni-linus-torvalds.jpg "Git compie 20 anni e Linus Torvalds parla della sua creatura")
/https://www.ilsoftware.it/app/uploads/2025/04/sorgente-altair-basic.jpg "Microsoft rilascia il suo codice sorgente! Per festeggiare 50 anni di attività")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")
/https://www.ilsoftware.it/app/uploads/2025/03/linus-torvalds-critica-modifiche-kernel-linux.jpg "Linus Torvalds perde la pazienza: queste modifiche DRM nel kernel Linux sono disgustose")