/https://www.ilsoftware.it/app/uploads/2023/09/snapshot-backup-kopia.jpg "Snapshot con Kopia: cosa sono e come proteggono i dati")
Quando si creano copie di sicurezza dei dati, in azienda come in qualunque altro ambito, è importante abbracciare almeno la politica di backup 3-2-1 in modo tale da scongiurare la perdita di informazioni importanti in seguito ad attacchi informatici, incidenti, errori umani e così via. Gli snapshot rappresentano un pilastro essenziale per le più moderne ed efficaci soluzioni di backup. Nel nostro articolo ci soffermiamo sull’importanza degli snapshot e sul loro utilizzo presentando poi un’applicazione open source, rilasciata sotto licenza Apache 2.0, che li rende sfruttabili in qualunque contesto.
Cosa sono gli snapshot e a che servono
Gli snapshot sono utilizzati per registrare lo stato dei file e delle cartelle in un certo istante. Rappresentano un insieme di dati in un determinato momento.
Quando si crea uno snapshot, il sistema provvede a creare una copia dei dati ma annota anche i metadati e le informazioni sui file e le directory. In questo modo, in un secondo tempo, diventa possibile visualizzare e ripristinare il contenuto esatto dei file come erano al momento della creazione dello snapshot.
La generazione degli snapshot successivi può avvenire in modo incrementale: ciò significa che una volta creato il primo backup, quelli successivi contengono solo le modifiche rilevate in seguito. Si tratta quindi di un approccio che aiuta a risparmiare spazio di archiviazione poiché i dati non risultano inutilmente duplicati. Anche il ripristino può richiedere meno tempo poiché è necessario recuperare solo le modifiche apportate dopo l’ultimo snapshot.
In termini di data retention, i software di backup che supportano gli snapshot generalmente consentono di specificare per quanto tempo è necessario conservare i dati. Ad esempio, è possibile mantenere snapshot giornalieri per una settimana, snapshot settimanali per un mese e snapshot mensili per un anno. Così si può accedere alle copie dei dati in vari momenti temporali.
Gli snapshot sono utilizzati piuttosto spesso nei moderni sistemi di backup ma sono sfruttati anche in altri contesti: ad esempio, li usano i sistemi di gestione dei volume (ad esempio, a livello di file system ZFS), le soluzioni per la virtualizzazione (snapshot di macchine virtuali), database (snapshot dei dati contenuti nel database) e via dicendo.
Cos’è e come funziona il backup con Kopia
Kopia è un software open source veloce e sicuro per il backup e il ripristino dei dati. Consente di creare snapshot crittografati e salvarli in uno spazio di archiviazione locale o remoto: la destinazione può essere un sistema collegato in rete locale, un server NAS, un servizio cloud a scelta dell’utente.
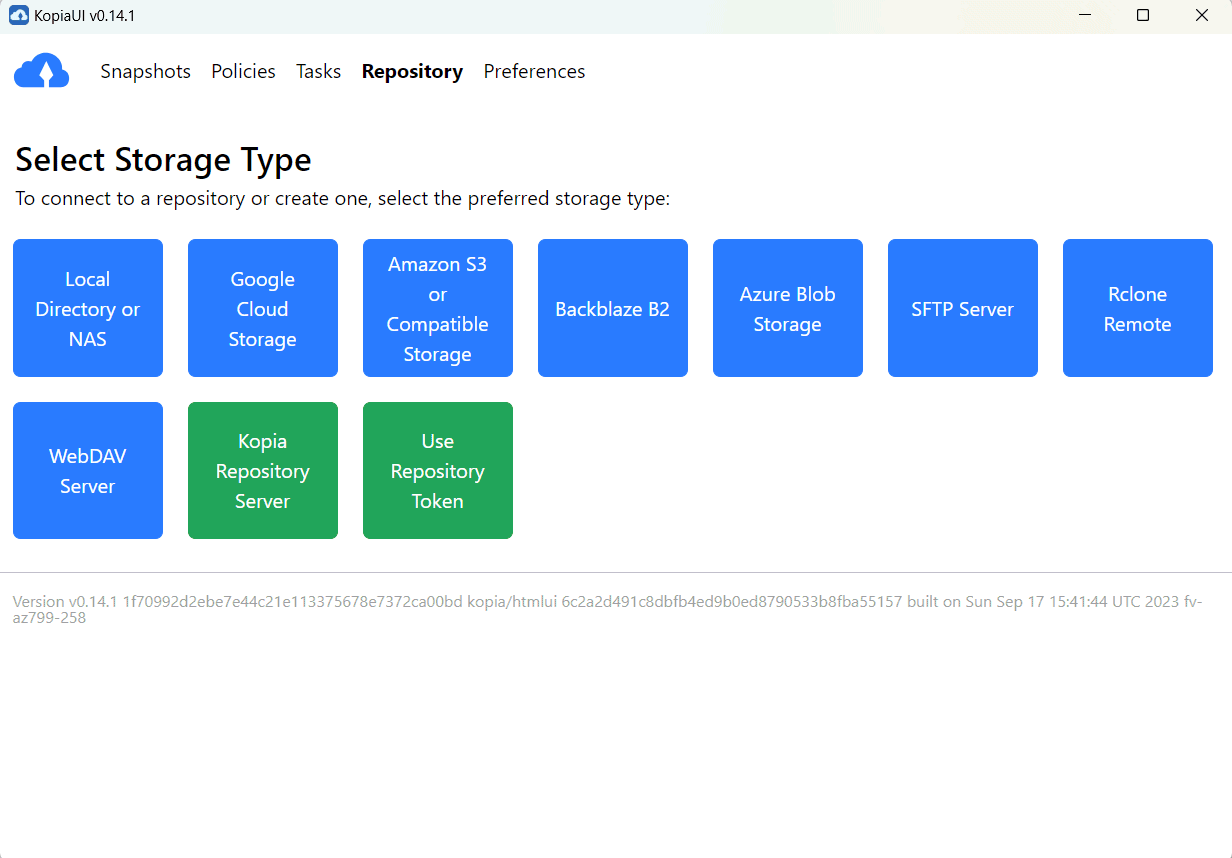
L’utente ha la possibilità di scegliere il provider di archiviazione cloud che preferisce per salvare gli snapshot. Sono disponibili diverse opzioni, tra cui:
- Amazon S3 e qualsiasi archiviazione cloud compatibile con S3
- Azure Blob Storage
- Backblaze B2
- Google Cloud Storage
- Qualsiasi server remoto o archiviazione cloud che supporti WebDAV
- Qualsiasi server remoto o archiviazione cloud che supporti SFTP
- Alcune delle opzioni di archiviazione cloud supportate da Rclone (richiede l’installazione e la configurazione di Rclone in aggiunta a Kopia)
Il supporto per Rclone è ancora indicato dagli sviluppatori come sperimentale: non tutte le opzioni di archiviazione cloud supportate da Rclone sono supportate da Kopia. Ad ogni modo, Kopia funziona alla perfezione con Dropbox, OneDrive e Google Drive attraverso Rclone.
L’applicazione non crea un’immagine completa della macchina; invece, si concentra sull’effettuazione del backup e dell’eventuale ripristino dei dati contenuti nelle posizioni di memoria che l’utente ritiene essenziali.
Compatibile con tutti i sistemi operativi, Kopia offre sia una versione con interfaccia a riga di comando (CLI) che una versione con interfaccia grafica (GUI). Lo strumento si propone quindi come una soluzione versatile e flessibile, adatta sia agli utenti avanzati che ai meno esperti.
Tra le caratteristiche di Kopia citiamo il supporto per la compressione, la deduplicazione, la correzione degli errori e la crittografia end-to-end “zero knowledge“. I dati sono cioè crittografati prima di lasciare il dispositivo e solo l’utente ha accesso alle informazioni contenute negli snapshot, previa digitazione di una password segreta. Non esiste assolutamente alcun modo per ripristinare gli snapshot (quindi i file e le cartelle dei quali si è eseguito il backup) da un repository Kopia se si dimentica la password.
La procedura di configurazione di Kopia, inoltre, permette di utilizzare eventualmente più posizioni di storage cloud. In altre parole, è possibile usare più posizioni di archiviazione diverse. Anche per memorizzare i dati provenienti da più macchine.
Politiche di backup e gestione degli snapshot
Prima di creare uno snapshot dei dati, Kopia permette di selezionare i file e le directory da memorizzare nell’archivio di backup (chiamato repository). Gli snapshot sono sempre incrementali: ciò significa che solo le modifiche ai file vengono caricate nel repository, risparmiando spazio di archiviazione in locale così come sul cloud.
Le policies di Kopia permettono la definizione di regole per la creazione e la gestione degli snapshot. Si può stabilire la frequenza degli snapshot, escludere determinati file o directory e decidere quanto a lungo mantenere uno snapshot prima di eliminarlo.
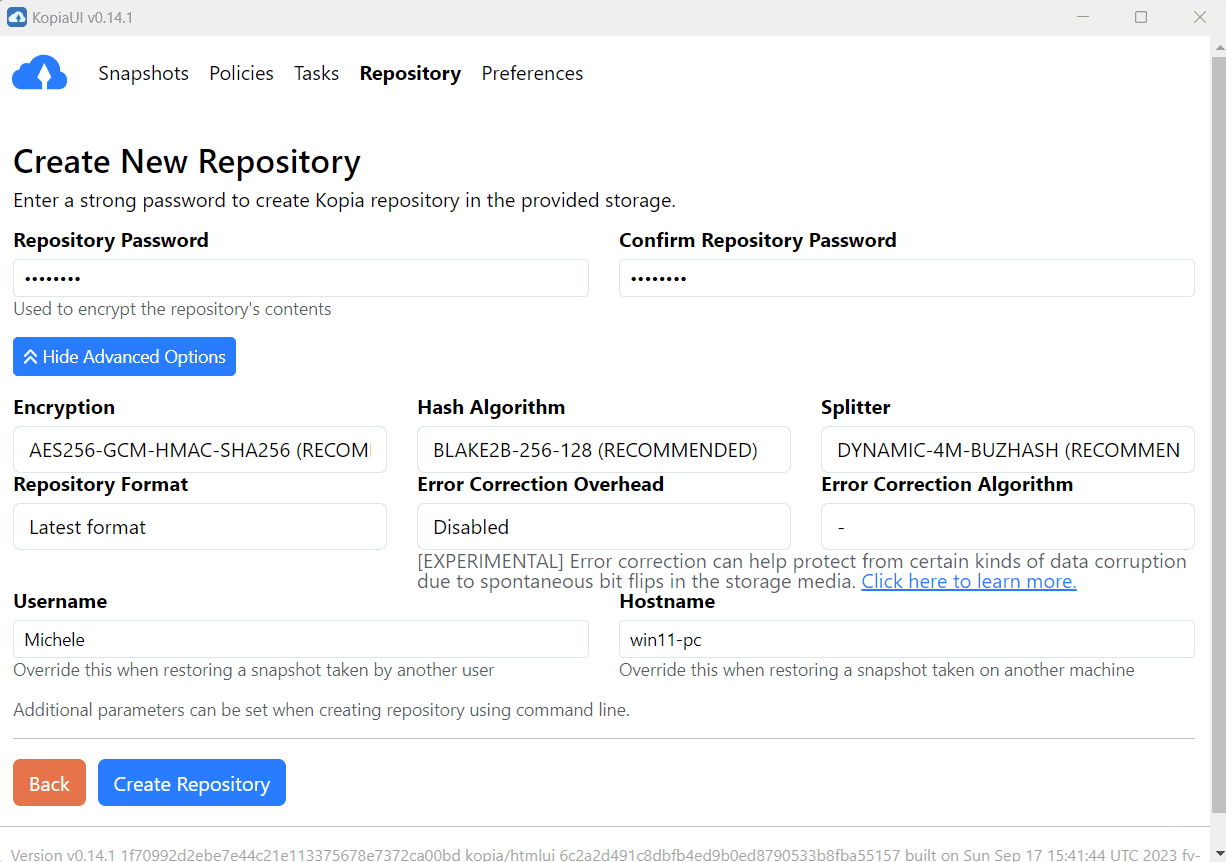
Quando è necessario ripristinare i dati, Kopia offre tre opzioni: montare uno snapshot come disco locale per la navigazione e il ripristino dei file e delle cartelle che servono, ripristinare tutti i file da uno snapshot o ripristinare file specifici.
Interfaccia basata su riga di comando, GUI e modalità server
Per usare Kopia da interfaccia testuale (CLI, command-line interface) basta utilizzare il file binario chiamato kopia e disponibile per tutti i vari sistemi operativi. L’interfaccia grafica di Kopia si appoggia a sua volta allo stesso file binario. Va detto che alcune funzionalità avanzate sono disponibili solo tramite la CLI e non sono ancora accessibile da KopiaUI, ovvero la versione basata su interfaccia grafica.
Kopia è inoltre disponibile sia come programma desktop che come applicazione Web: quest’ultima è accessibile quando si decide di attivare la modalità server.
Le istruzioni per il download e l’installazione di Kopia sono disponibili nella pagina ufficiale. Come URL di riferimento per il download di tutte le versioni del programma suggeriamo di utilizzare questo.
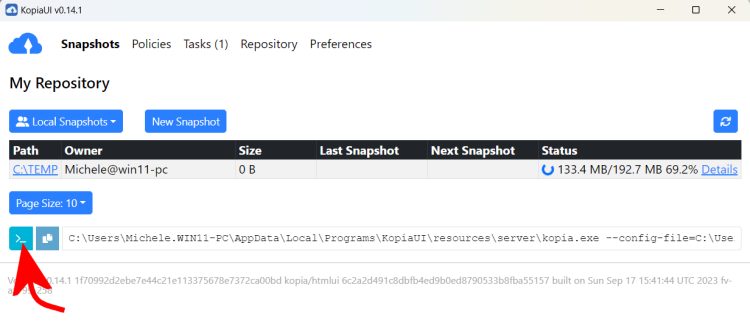
Per imparare a usare Kopia, comunque, il modo migliore consiste nell’installare in prima battuta la versione dotata di interfaccia grafica. Cliccando sull’icona evidenziata in figura, si ottiene la corrispondente sintassi utilizzabile da riga di comando.
Nell’immagine che segue, ad esempio, si vede come risulta molto semplice impostare la politica di data retention utilizzando l’interfaccia grafica di Kopia.
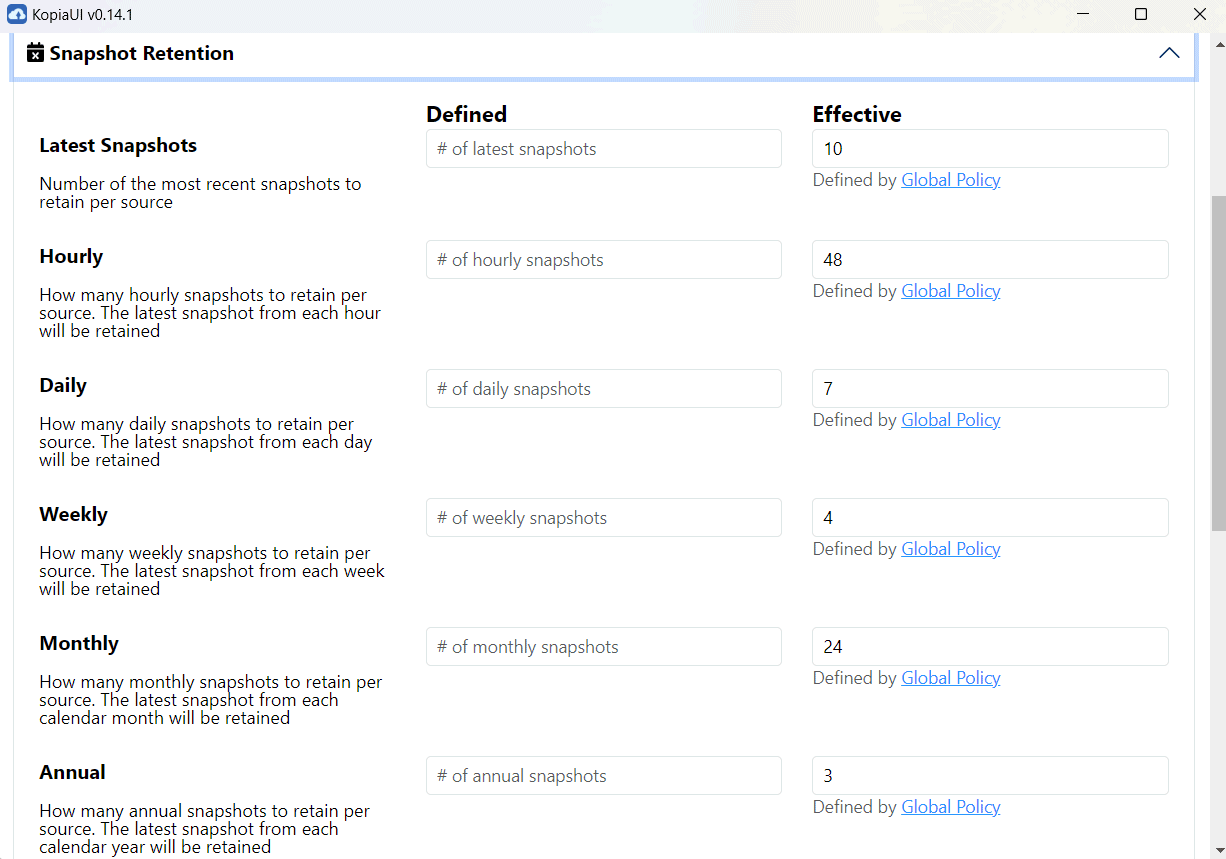
Policy globali e specifiche per il singolo repository
Kopia utilizza già delle regole o policy globali che interessano tutti i repository via via creati e gestiti. È però possibile impostare, come visto nella precedente schermata, delle preferenze “ad hoc” per le singole attività di backup.
La policy globale interviene automaticamente ed è quindi applicata sul repository ogni volta che l’utente non ne indica una personalizzata.
Le varie regole che Kopia supporta, consentono di definire quali file e cartelle ignorare, quanti snapshot orari, giornalieri, settimanali, mensili e annuali mantenere, la frequenza con cui devono essere creati gli snapshot, se comprimere o meno i dati e così via. Maggiori informazioni sulle policy di Kopia sono condivise in questo documento di supporto.
Credit immagine in apertura: iStock.com/Sakorn Sukkasemsakorn
/https://www.ilsoftware.it/app/uploads/2025/04/unita-ssd-non-alimentate-perdita-dati.jpg "Attenzione, le unità SSD possono perdere dati dopo 2 anni se non alimentate")
/https://www.ilsoftware.it/app/uploads/2025/03/ripristino-windows-11-quick-machine-recovery.jpg "Ripristino remoto Windows 11 al debutto: come funziona")
/https://www.ilsoftware.it/app/uploads/2025/03/veeam-errore-ripristino-backup-windows-11-24h2.jpg "Windows 11 24H2 fa a pugni con i backup Veeam: come risolvere")
/https://www.ilsoftware.it/app/uploads/2025/01/cubbit-esempio-virtuoso-asl-cn1-cuneo.jpg "Un esempio virtuoso: ASL CN1 sceglie Cubbit per lo storage geo-distribuito")