/https://www.ilsoftware.it/app/uploads/2023/08/traduzione-testi-parlato-in-altra-lingua.jpg "SeamlessM4T traduce il parlato ed effettua il dubbing in un'altra lingua")
I modelli generativi e in generale gli algoritmi di intelligenza artificiale stanno sempre più rivestendo la parte del leone anche per ciò che riguarda la gestione di input vocali e la traduzione in tempo reale da una lingua all’altra. SeamlessM4T è un progetto di Meta presentato come il primo modello di traduzione e trascrizione AI multilingue e multimodale. Consente di comunicare senza sforzo attraverso il parlato e il testo in diverse lingue.
Costruire un traduttore universale, simile al Babel Fish descritto nel romanzo di fantascienza umoristica “Guida galattica per gli autostoppisti“, è una sfida davvero imponente poiché i sistemi esistenti di traduzione da voce a voce e da voce a testo coprono solo una piccola frazione delle lingue parlate nel mondo. SeamlessM4T, tuttavia, rappresenta un enorme passo avanti perché riduce errori e ritardi, aumentando l’efficienza e la qualità del processo di traduzione. Ciò consente alle persone che parlano lingue diverse di comunicare in modo più efficace.
![]()
Perché SeamlessM4T è multimodale
Nel caso di SeamlessM4T, si parla di esperienza multimodale perché il modello non si limita a una singola modalità di comunicazione, come il testo o la voce, ma è in grado di gestire diverse modalità di input e output in modo integrato. In altre parole, SeamlessM4T consente di tradurre e trascrivere non solo il testo, ma anche il parlato, in una varietà di combinazioni e lingue diverse.
Questa caratteristica multimodale è rilevante perché riflette il modo in cui le persone comunicano nella realtà, utilizzando sia il parlato che il testo in diverse situazioni. Si pensi, ad esempio, a quelle situazioni in cui risulta necessario tradurre un discorso in una lingua straniera trasformandolo in testo scritto, per condividerlo con qualcuno che non parla e non comprende la stessa lingua. Ancora, si pensi ai casi in cui si vorrebbe tradurre un testo scritto in una lingua che non si conosce effettuandone automaticamente il dubbing per aiutare qualcuno che non può leggere.
L’esperienza multimodale di SeamlessM4T permette quindi agli utenti di scegliere la modalità di comunicazione più adatta alle loro esigenze e di tradurre o trascrivere testi e parlato senza alcuna difficoltà. Ciò contribuisce a creare una comunicazione più fluida e naturale tra individui che parlano lingue diverse, eliminando le barriere linguistiche attraverso una varietà di canali di comunicazione.
Cos’è il dubbing
Il dubbing è una pratica utilizzata nell’industria dell’intrattenimento, specialmente nel cinema e nella televisione, in cui le voci originali di attori o personaggi sono sostituite da voci tradotte o doppiate in un’altra lingua. Questo processo permette al pubblico che parla una lingua diversa da quella originale del film o della serie TV di comprendere il contenuto senza dover leggere i sottotitoli.
I doppiatori rieditano e sovrappongono le loro voci ai dialoghi originali, cercando di sincronizzarle con i movimenti delle labbra e l’intonazione degli attori per rendere l’esperienza visiva il più realistica possibile.
Ecco, SeamlessM4T porta il dubbing nelle mani di tutti gli utenti facendosi carico di riconoscere il parlato originale, l’intonazione e le sfumature della voce per creare audio in un’altra lingua che sia il più possibile vicino alla versione di partenza.
Come si presenta SeamlessM4T
SeamlessM4T supporta il riconoscimento vocale del parlato in quasi 100 lingue, la traduzione da voce a testo per quasi 100 lingue in input e output, la traduzione da voce a voce supportando quasi 100 lingue di input e 36 lingue di output.
La piattaforma presentata da Meta, inoltre, offre la possibilità di tradurre da testo a testo in quasi 100 lingue; è inoltre prevista la traduzione da testo a voce, supportando quasi 100 lingue di input e 35 lingue in output.
Al momento, come sta già facendo Meta per altri progetti, la licenza con cui è distribuito SeamlessM4T permette lo svolgimento di iniziative di ricerca. Non è invece consentito, purtroppo, l’utilizzo per finalità commerciali. L’idea dell’azienda di Mark Zuckerberg è quella di facilitare il lavoro dei ricercatori e degli sviluppatori che possono usare SeamlessM4T come base per la costruzione dei loro progetti.
I tecnici di Meta hanno inoltre rilasciato e reso pubblici i metadati di SeamlessAlign, il più grande dataset di traduzione multimodale aperto ad oggi conosciuto: contiene 270.000 ore di parlato e testi estratti dagli stessi discorsi, una base preziosissima per la realizzazione di progetti derivati. Ad esempio per l’addestramento delle intelligenze artificiali.
Come tradurre con SeamlessM4T senza installare nulla in locale
Per toccare con mano i risultati ai quali è possibile pervenire utilizzando SeamlessM4T, è sufficiente avviare da browser Web l’applicazione Seamless Communication Translation Demo. Per procedere, bisogna dapprima cliccare sul pulsante Start demo quindi spuntare la casella “I have read and agree to be bound by the SeamlessTerms and Conditions“.
Con un clic su Start recording, è quindi necessario autorizzare l’applicazione di Meta ad accedere al microfono del dispositivo in uso.
Il passo seguente consiste nella scelta della lingua: cliccando quindi su Translate, dopo pochi secondi di attesa, si ottiene sia la traduzione testuale che un file audio risultato dell’operazione di dubbing.
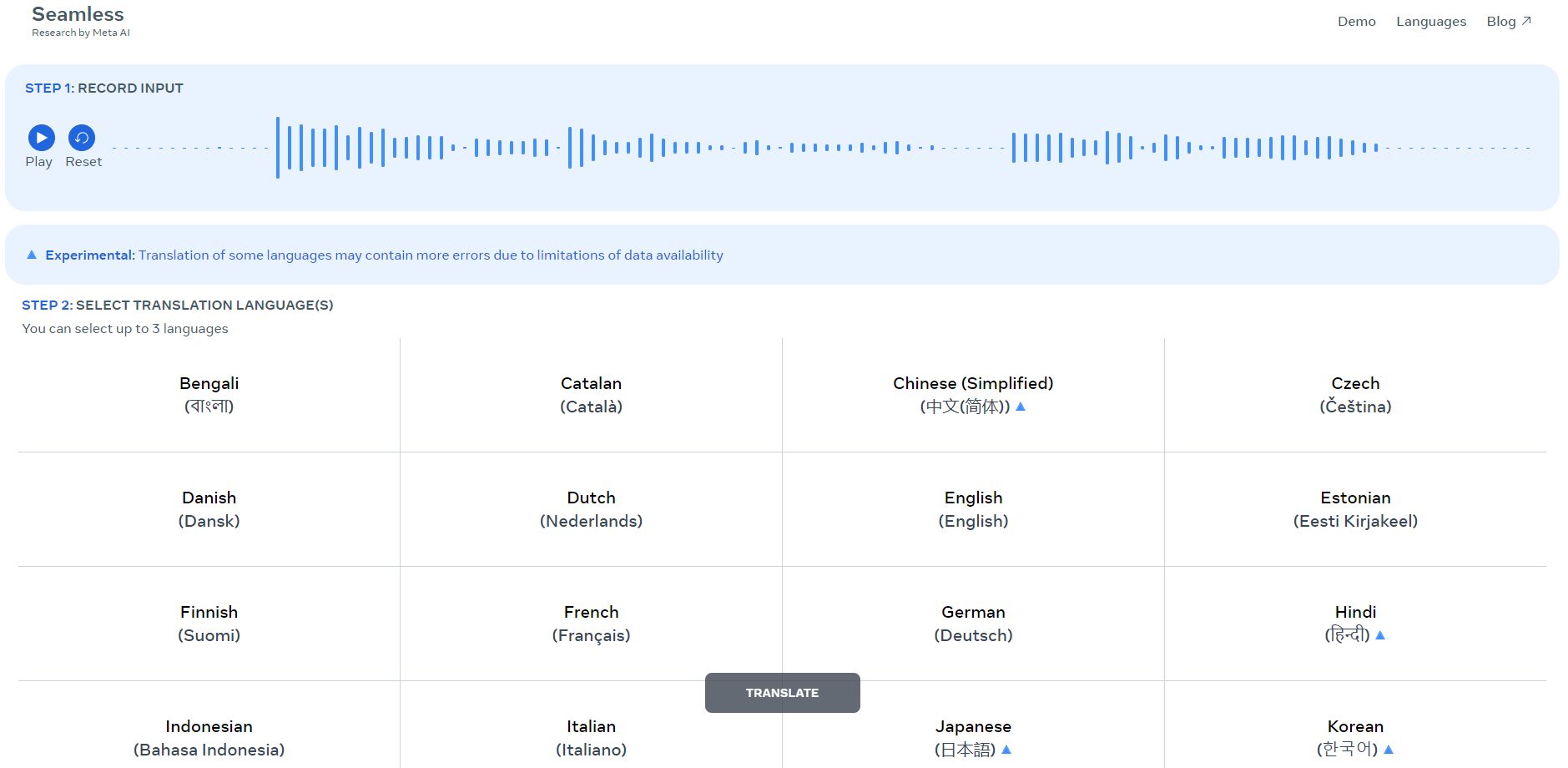
Nella parte superiore della pagina, SeamlessM4T mostra innanzi tutto il testo generato con il motore speech-to-text a partire dal parlato acquisito tramite il microfono. I due riquadri successivi, invece, propongono la traduzione testuale e la traccia audio generata nell’altra lingua (speech translation).

Come scaricare la traduzione audio
Posto che Meta non permette l’utilizzo delle informazioni generate con SeamlessM4T per finalità commerciali e che l’eventuale uso dei dati deve attenersi scrupolosamente ai termini del servizio, è possibile scaricare la traduzione audio con un semplice trucco. Vediamo come si fa con Google Chrome.
Dopo aver generato la traduzione, si può premere la combinazione di tasti CTRL+MAIUSC+I per aprire gli Strumenti per gli sviluppatori di Chrome. Qui si deve selezionare la scheda Network e, infine, fare clic sul pulsante “Play” nel riquadro Speech translation di SeamlessM4T.
Come ultima voce, nella scheda Network, compare un riferimento che inizia con la stringa blob:. È necessario farvi clic con il tasto destro del mouse e selezionare Open in new tab.
Chrome mostra un riproduttore audio piuttosto spartano: cliccando sui tre puntini quindi su Scarica, si può memorizzare in locale in formato WAV la traduzione creata con l’applicazione di Meta.
Come installare e usare SeamlessM4T sui propri sistemi
Per installare SeamlessM4T su un sistema all’interno della propria infrastruttura oppure sul cloud è innanzi tutto necessario accertarsi che Python e pip siano correttamente installati. Dalla finestra del terminale, è necessario portarsi nella cartella in cui si è scaricato il codice di SeamlessM4T. Qui va digitato il seguente comando per installare SeamlessM4T e le sue dipendenze:
pip install .
Se ci si trovasse in un ambiente Conda, va installata anche la libreria libsndfile con il seguente comando:
conda install -y -c conda-forge libsndfile
Le librerie utilizzate nel progetto
È importante tenere presente che SeamlessM4T basa il suo funzionamento su tre librerie sviluppate da Meta:
- fairseq2: È una libreria open source di sequenze di modellizzazione che fornisce componenti per la traduzione automatica, la modellizzazione del linguaggio e altre attività di generazione di sequenze. Al momento fairseq2 è supportata solo su Linux e macOS.
- SONAR e BLASER 2.0: SONAR permette la gestione di frasi multilingue con un approccio multimodale. Offre inoltre un encoder di testo e parlato per molte lingue. BLASER 2.0 è una metrica di valutazione per la traduzione multimodale.
- stopes: È una libreria per l’estrazione di dati utilizzata per il training dei modelli di traduzione, inclusi quelli per la traduzione del parlato.
Esempi di utilizzo di SeamlessM4T
Per avviare un’attività S2ST (speech-to-speech) dalla riga di comando, è sufficiente impartire il comando che segue:
m4t_predict <percorso_input_audio> s2st <lingua_destinazione> --output_path <percorso_output_audio>
Per eseguire un’attività T2TT (text-to-text) si può invece ricorrere alla seguente istruzione:
m4t_predict <testo_input> t2tt <lingua_destinazione> --src_lang <lingua_sorgente>
La guida contenuta nel file README contiene istruzioni dettagliate su come eseguire altre operazioni di inferenza sfruttando l’intelligenza artificiale di SeamlessM4T.
/https://www.ilsoftware.it/app/uploads/2024/11/generico-streaming-tv.jpg "Streaming: un'altra piattaforma introduce il Membro Extra")
/https://www.ilsoftware.it/app/uploads/2024/06/YouTube-Music.jpg "YouTube Music introduce nuova funzione per normalizzare il volume")
/https://www.ilsoftware.it/app/uploads/2025/04/pinta-editor-immagini-open-source.jpg "Arriva Pinta 3.0, alternativa leggera a Paint.NET e GIMP")
/https://www.ilsoftware.it/app/uploads/2025/04/formato-RAW-fotocamera-digitale.jpg "RAW: perché i produttori di fotocamere usano formati differenti?")