/https://www.ilsoftware.it/app/uploads/2024/03/rimuovere-sfondo-immagini-IA.jpg "Scontornare immagini e togliere lo sfondo, il modello Layer Diffusion lascia a bocca aperta")
A partire da Stable Diffusion, tanti studiosi e sviluppatori autonomi, hanno realizzato modelli generativi derivati che consentono di ottenere effetti davvero notevoli sfruttando i benefici dell’intelligenza artificiale (IA). Lvmin Zhang, noto per essere l’ideatore di ControlNet, ha recentemente presentato il concetto di Layer Diffusion pubblicando e condividendo un documento che descrive dettagliatamente la tecnica utilizzata.
Traendo ispirazione proprio da Stable Diffusion, Zhang non ha soltanto teorizzato ma anche realizzato un nuovo sistema che consente di creare nuove immagini con l’IA applicando uno sfondo trasparente. L’effetto che si ottiene è paragonabile all’operazione che prevede di scontornare un’immagine e togliere lo sfondo da una foto.
Cos’è Layer Diffusion e come funziona in breve
L’autore del progetto ha sviluppato una soluzione chiamata “trasparenza latente” che arricchisce i modelli di diffusione latenti come Stable Diffusion e permette di generare immagini che presentano trasparenze. Zhang ha proposto la sua idea perché il mercato manca di strumenti efficaci per togliere lo sfondo dalle immagini prodotte dai modelli generativi, e ciò a dispetto della crescente richiesta di tali funzionalità da parte del mercato.
La diffusione è un processo attraverso il quale una distribuzione di probabilità complessa viene “diffusa” o “semplificata” gradualmente durante il processo di campionamento. In termini più semplici, il modello inizia con un’immagine “rumorosa” o casuale e successivamente la aggiorna un poco alla volta, riducendo gradualmente l’incertezza e generando un’immagine più definita. Questo processo di diffusione è guidato da un approccio stocastico che determina come l’immagine viene sviluppata passo dopo passo.
Il concetto di “trasparenza latente” si riferisce allo schema proposto da Zhang per rendere trasparente una parte di un’immagine. Il termine “latente” indica che questa caratteristica di trasparenza è incorporata e manipolata nella rappresentazione latente dell’immagine. Quest’ultima è uno spazio astratto che cattura le caratteristiche significative dell’immagine in un formato compresso e interpretabile.
Per garantire la coerenza e la fusione armoniosa tra i livelli di una stessa immagine, i modelli LoRA (Low-Rank Adaptation) appositamente addestrati permettono di adattare il funzionamento del sistema alle diverse condizioni dei livelli di ciascuna immagine.
Come scontornare immagini e togliere lo sfondo usando Stable Diffusion WebUI Forge
In un altro articolo abbiamo visto come velocizzare i risultati ottenibili con Stable Diffusion e ridurre significativamente i tempi di generazione delle immagini.
Chi avesse già installato e configurato in locale Stable Diffusion WebUI Forge, soluzione sviluppata dallo stesso Zhang, può adesso aggiungere il supporto per il modulo addizionale che consente di scontornare le immagini generate, in modo semplice e veloce.
Per procedere, basta accedere all’interfaccia Web locale di Stable Diffusion WebUI Forge (indirizzo localhost nella barra del browser), fare clic sulla scheda Extensions quindi su Install from URL. Nell’apposito campo si deve inserire l’indirizzo seguente: https://github.com/layerdiffusion/sd-forge-layerdiffuse
Con un clic sul pulsante Install, il modello Layer Diffusion, brevemente descritto in precedenza, sarà a sua volta caricato sul sistema in uso. Dopo la comparsa del messaggio di conferma, si deve cliccare sul pulsante Apply and restart UI.
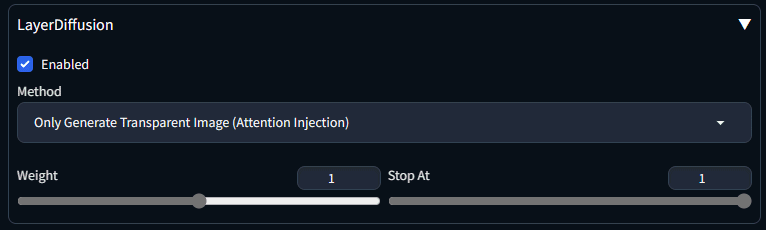
La presenza del menu a tendina LayerDiffusion, conferma che l’installazione è andata a buon fine. Bisogna solamente verificare che la casella Enabled sia attiva e che il metodo preferito sia Only generate transparent image (attention injection).
Utilizzare prompt “ad hoc” per togliere lo sfondo dalle immagini generate
A questo punto è possibile inserire un prompt per generare un’immagine, come già visto nell’articolo incentrato su Stable Diffusion WebUI Forge. Nei suoi esempi, Zhang suggerisce di ricorrere, ad esempio, al modello Juggernaut XL.
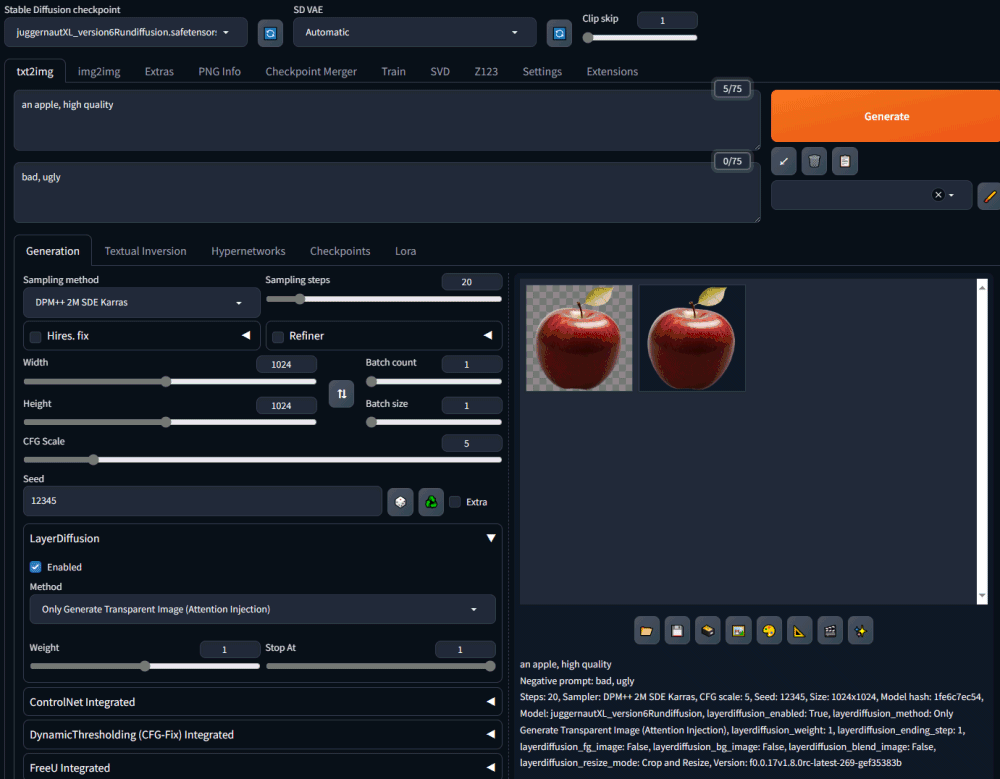
Nel repository GitHub di Layer Diffusion si possono trovare diversi prompt di esempio, per produrre una vasta schiera di immagini. C’è anche un video che mostra i diversi effetti ottenibili intervenendo sulle varie regolazioni.

Addirittura, come dimostra Zhang in questo esempio, è possibile selezionare From Background to Blending dal menu a tendina Method e passare al modello generativo un’immagine preesistente.
Il ricercatore ha “consegnato” al modello l’immagine di una panchina immersa nel verde per poi richiedere, tramite prompt, l’aggiunta di un anziano seduto sulla stessa panchina. Il risultato è quello visibile in figura: la foto della panchina nel riquadro LayerDiffusion e adesso “popolata” con l’immagine di una persona di una certa età.
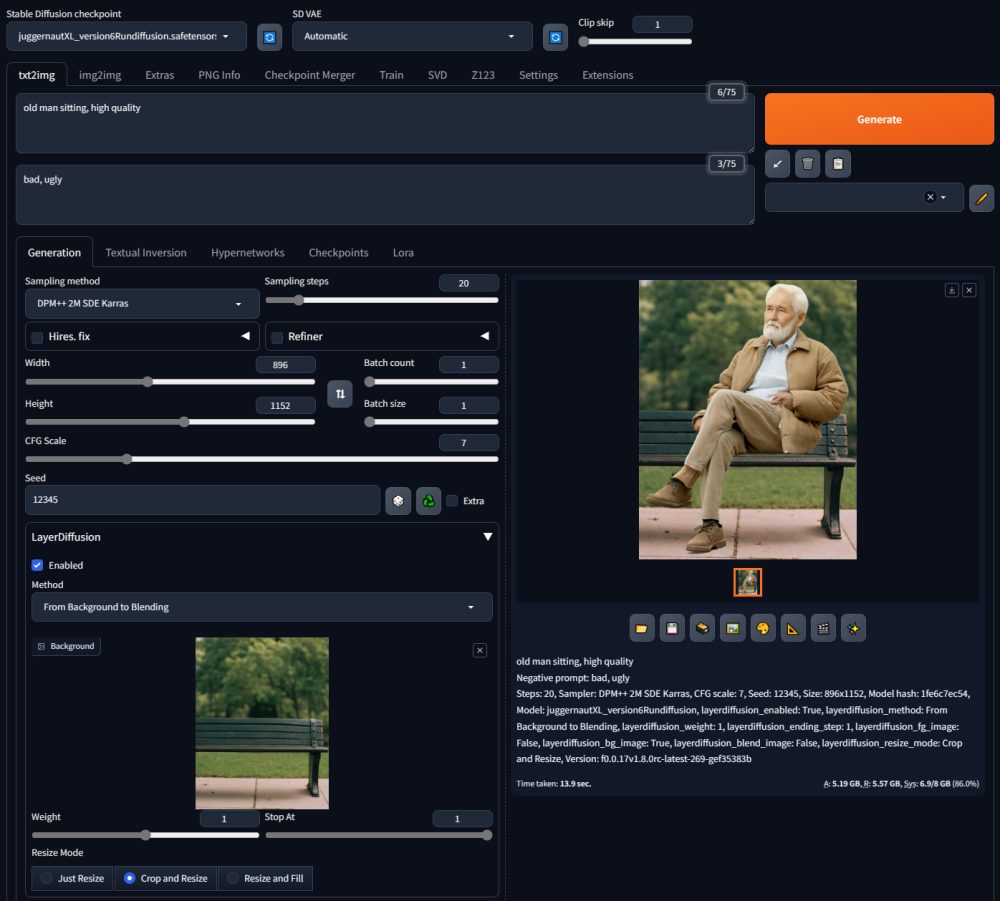
Il bello è che, trascinando l’ulteriore immagine prodotta dal modello generativo, è possibile scontornare il “protagonista” e rimuovere lo sfondo.
Credit immagine in apertura: iStock.com – Vertigo3d
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")