/https://www.ilsoftware.it/app/uploads/2024/01/archivebox-salva-copia-pagine-siti-web.jpg "Salvare pagine Web e archiviarle con ArchiveBox: ecco il vostro Internet Archive")
Il Web offre un volume sconfinato di informazioni utili per la propria attività o professione. Il problema è preservare questi dati e tenerne traccia in modo tale che non vadano persi. I contenuti pubblicati online sono per definizione dinamici: l’autore può modificarli a suo piacimento, rimuoverli oppure possono essere cancellati, ad esempio, perché il fornitore del servizio hosting non viene più pagato. Internet Archive è, da quasi tre decenni, la memoria del Web. Si tratta di un’iniziativa che archivia e offre l’accesso a un ampio ventaglio di informazioni pubblicate online.
Come abbiamo spiegato in un articolo dedicato a che cos’è Internet Archive, il servizio provvede a salvare le pagine Web nel corso del tempo conservando generalmente più copie. In questo modo si può ad esempio verificare come un singolo contenuto o un intero sito Web cambiano nel corso del tempo. Le copie dei siti Web memorizzate e custodite da Internet Archive di solito sono anche “navigabili”: significa che è possibile spostarsi tra le pagine di un sito Web (anche quando non esiste più…), come si presentava tempo addietro, cliccando sui link (collegamenti ipertestuali) presenti in pagina.
Questo specifico servizio si chiama Wayback Machine ma è possibile trovare davvero di tutto. Ad esempio, Internet Archive permette di scaricare le ISO di Windows e di altri software. Ci è capitato ad esempio di non riuscire più a trovare la ISO del vecchio Windows 7 Starter: ecco, facendo attenzione all’origine del file e alla sua firma digitale, è possibile trovarla.
Costruitevi il vostro personale Internet Archive: come salvare pagine Web con ArchiveBox
Un po’ come fa Internet Archive (questa era la home page di Google a fine 1998), ArchiveBox è una soluzione che permette di salvare pagine Web creandone una copia. Il software permette di memorizzare la pagina HTML insieme con tutti gli elementi che la compongono su un supporto locale, ad esempio on-premises o sul cloud.
Fino a qualche tempo fa tanti utenti facevano riferimento a strumenti online per archiviare siti Web e creare copie delle pagine. L’anno scorso, tuttavia, alcune società hanno iniziato a usare il “pugno duro”. Per limitarsi soltanto a Reddit, la nota piattaforma social ha cominciato a impedire l’archiviazione delle sue pagine da parte di soggetti terzi. I siti che permettevano di salvare i contenuti pubblicati su Reddit hanno chiuso i battenti e le informazioni precedentemente memorizzate dagli utenti sono scomparse.

Perché avere fiducia in un servizio di archiviazione online se è possibile utilizzare un software a costo zero per memorizzare gli stessi dati, renderli comodamente ricercabili ed evitare di perderli?
Se vi è mai capitato di aggiungere ai segnalibri una risorsa importante pubblicata sul Web per poi scoprire successivamente che non è più disponibile, sapete quanto questo può essere frustrante.
Cos’è e come funziona ArchiveBox
Internet Archive è un servizio eccellente ma, com’è ovvio, non può tenere traccia di tutte le pagine pubblicate sul Web. Inoltre, giusto per fare un esempio, non è in grado di acquisire Facebook. È possibile chiedere manualmente di avviare la memorizzazione di un insieme di contenuti: la procedura fallisce, tuttavia, se il file robots.txt impedisce le attività di Web scraping.
Il crescente utilizzo di Javascript e di contenuti video incorporati rende inoltre più difficile l’acquisizione delle risorse e la conseguente archiviazione. Basti verificare come, ai siti archiviati su Internet Archive, manchino buona parte delle funzionalità originali.
ArchiveBox è uno strumento open source progettato per funzionare come un sistema di raccolta Web personale. Gli utenti possono salvare una copia statica di una pagina web e tutti i suoi contenuti associati. L’applicazione permette di creare il proprio archivio personale, successivamente consultabile anche se il contenuto originale dovesse diventare inaccessibile o dovesse essere rimosso.
L’installazione di ArchiveBox avviene su un proprio sistema locale, su un NAS oppure sul cloud, ad esempio su una macchina virtuale acquistata allo scopo. Gli utenti possono configurare ArchiveBox specificando i parametri come le directory di archiviazione, i filtri di inclusione ed esclusione, e altri dettagli.
ArchiveBox scarica la pagina Web e tutti i suoi contenuti (HTML, CSS, JavaScript, immagini,…) e li salva localmente. Questo processo crea una copia statica della pagina Web nel momento in cui è archiviata. Periodicamente, è possibile effettuare un aggiornamento dell’archivio per assicurarsi che le pagine Web siano ancora accessibili e aggiornate. L’applicazione gestisce in autonomia gli aggiornamenti e la rimozione dei contenuti obsoleti.
Dove e come installare ArchiveBox
Uno dei principali vantaggi di ArchiveBox è la possibilità di installarlo su un gran numero di piattaforme: è compatibile con la gestione tramite package manager, in tutte le principali distribuzioni Linux. Può quindi essere installato anche su un server NAS, il cui funzionamento – com’è noto – è di solito basato su kernel Linux.
In alternativa, indipendentemente dalla piattaforma utilizzata (Linux, Windows, macOS), è possibile usare Docker Compose per caricare ed eseguire ArchiveBox in forma containerizzata.
Docker Compose è uno strumento che facilita la definizione e l’esecuzione di applicazioni Docker multi-container. Grazie a Docker, così come avviene per le altre applicazioni, ArchiveBox risulta “impacchettato” – insieme con tutti i suoi componenti e dipendenze – in un ambiente isolato rispetto al resto del sistema (il container, appunto).
L’installazione con Docker Compose presuppone di aver installato sia Docker che questo software sul sistema. A questo punto è possibile avviare l’installazione usando la seguente sintassi dalla finestra del terminale:
mkdir archivebox && \
cd archivebox && \
curl -O 'https://raw.githubusercontent.com/ArchiveBox/ArchiveBox/dev/docker-compose.yml' && \
docker compose run archivebox init --setup
I primi due comandi creano una cartella chiamata archivebox e vi accedono per poi avviare il download del file di installazione e configurazione docker-compose.yml. L’ultimo comando provvede a inizializzare ArchiveBox e a configurare l’ambiente di lavoro. Si tratta di un insieme di attività che coinvolge la creazione di file, la configurazione di variabili di ambiente e altre attività necessarie per preparare l’applicazione.
Il comando seguente docker compose up avvia i servizi definiti nel file docker-compose.yml: il comando crea e carica i container per tutti i servizi specificati nel file di composizione Docker. Nel caso di ArchiveBox, basterà quindi avviare un browser Web sul sistema locale quindi digitare 127.0.0.1:8000 nella barra degli indirizzi per iniziare a lavorare con il sistema dei archiviazione delle pagine Web.
In alternativa, è possibile cliccare sulle varie sezioni in Quickstart, per ottenere indicazioni specifiche per installare ArchiveBox all’interno del proprio ambiente. Ad esempio, la guida contiene le istruzioni per installare ArchiveBox mediante package manager.
Come salvare pagine Web e renderle ricercabili in locale
Una volta installato ArchiveBox, il pulsante Add presente nella barra in alto dell’interfaccia Web consente di aggiungere la lista delle pagine Web da salvare in locale.
L’applicazione consente di specificare un singolo URL della pagina da memorizzare oppure inserire, uno per riga, più indirizzi separati. In questo modo ArchiveBox crea una copia di tutte le pagine specificate. Impostando 0 come profondità (depth), ArchiveBox acquisisce solo il contenuto di ciascun URL indicato; diversamente si può chiedere all’applicazione di seguire tutti i link presenti in pagina (limitandosi a un solo livello).
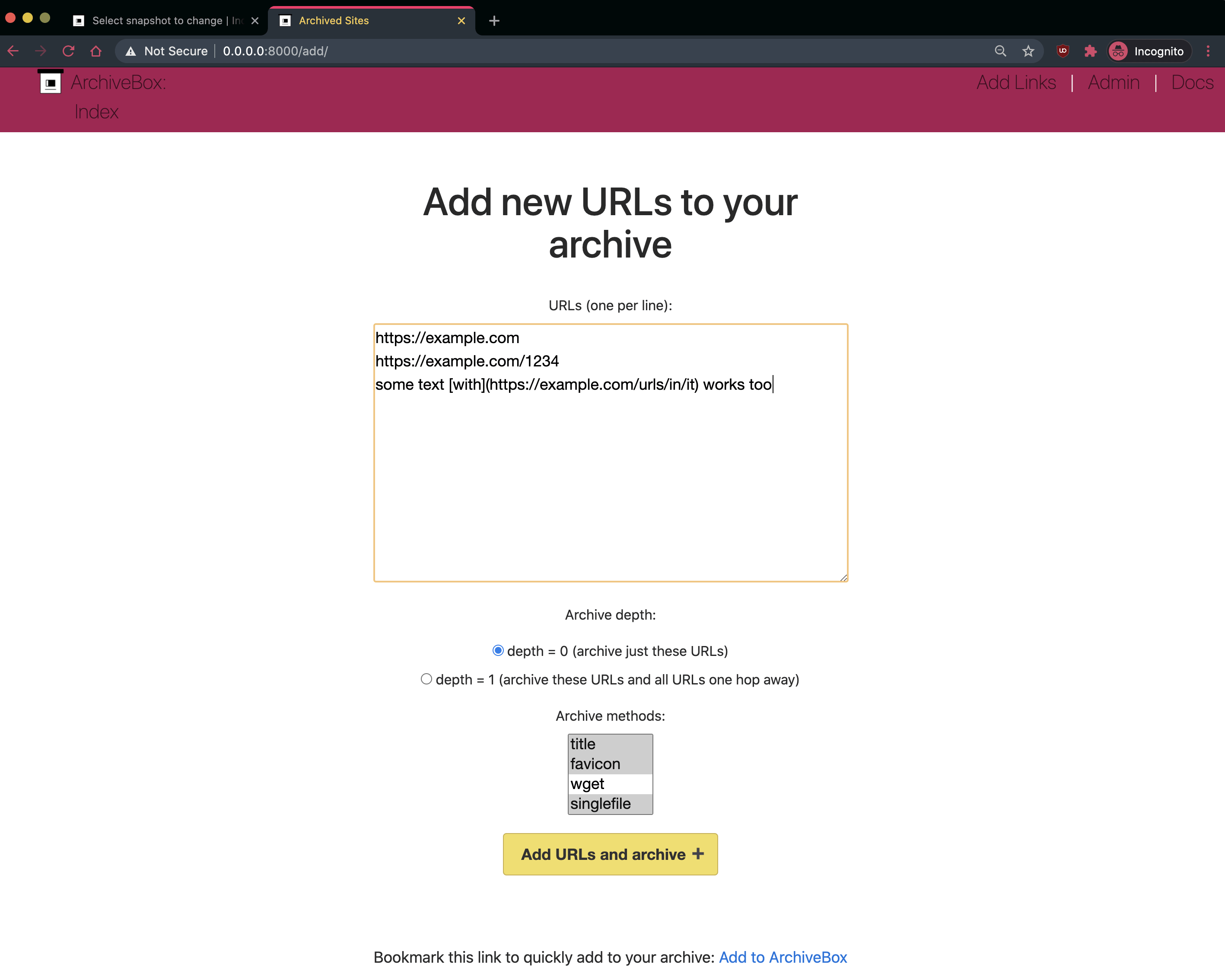
Per ciascun URL, ArchiveBox scarica tutto il contenuto della pagina e consente di accedere – con un semplice clic – alla copia conservata in locale. Le informazioni sono accessibili nel formato originale, in PDF, è possibile ottenere soltanto l’elenco dei file multimediali o, ancora, accedere al sorgente della pagina senza ulteriori riferimenti. C’è anche lo screenshot in formato PNG di ciascuna pagina.
Inoltre, è possibile beneficiare del formato HTML a file singolo: si tratta di un pacchetto che conserva tutti gli elementi della pagina in un unico contenitore (HTML, CSS, JavaScript, file multimediali,…). Le immagini sono automaticamente codificate in Base64 in modo da essere appunto gestibili all’interno del medesimo file.
ArchiveBox integra anche tutto il necessario per salvare i video insieme con le rispettive descrizioni e i dati salienti. Laddove altre applicazioni falliscono, quindi, ArchiveBox si propone come un archivista particolarmente efficace.
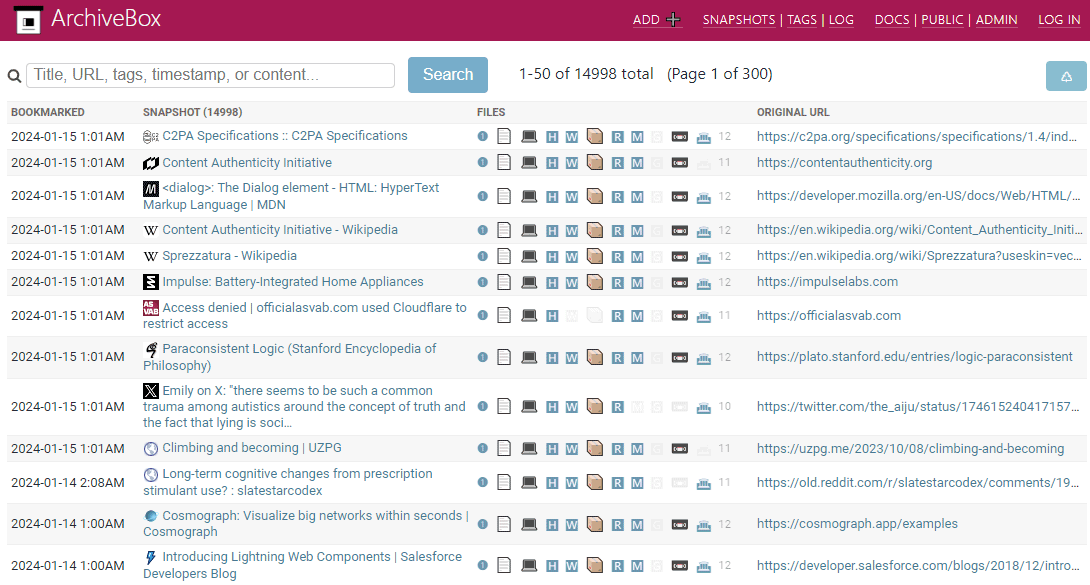
Sempre utilizzando l’interfaccia Web, ArchiveBox consente agli utenti di cercare informazioni in archivio e individuare i contenuti che servono. È inoltre possibile esportare gli archivi così da condividerli e renderli accessibili su altri dispositivi.
Inutile dire che l’applicazione offre anche una CLI (command line interface) che permette di gestire le informazioni in archivio ed aggiungerne di nuove utilizzando la riga di comando.
Credit immagine in apertura: iStock.com – D3Damon
/https://www.ilsoftware.it/app/uploads/2025/04/router.jpg "Aruba Fibra da 17,69€ al mese per 6 mesi: la promo scade oggi")
/https://www.ilsoftware.it/app/uploads/2025/04/addio-google.jpg "Addio a Google.it: c'è l'annuncio ufficiale")
/https://www.ilsoftware.it/app/uploads/2025/04/https-certificati-digitali-tls-durata-ridotta.jpg "Rivoluzione certificati SSL/TLS: durata ridotta a 47 giorni entro il 2029")
/https://www.ilsoftware.it/app/uploads/2025/04/google-discover-desktop.jpg "Google Discover arriva sui PC e cambia tutto")