/https://www.ilsoftware.it/app/uploads/2023/05/img_5577.jpg "Rimuovere le tag html da un documento con OpenOffice.org")
Supponiamo di avere a che fare con un documento HTML, aperto in forma testuale con la suite per l’ufficio OpenOffice.org. Si desideri eliminare dal documento tutte le tag HTML in modo da ottenere un testo “pulito” da rielaborare successivamente.
La procedura è piuttosto semplice e può essere messa in pratica ricorrendo al comando Modifica, Cerca e sostituisci quindi all’utilizzo delle “regular expressions”.
Le “regular expressions” o “espressioni regolari” sono stringhe di caratteri attraverso le quali si possono descrivere insiemi più ampi di stringhe, in base a specifiche regole sintattiche.
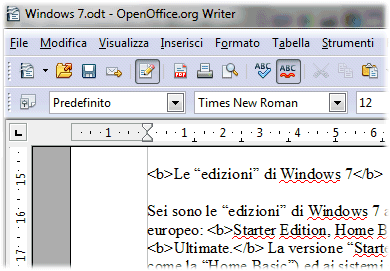
Dopo aver aperto, in OpenOffice.org, il documento contenente le tag HTML, si dovrà cliccare sul mneù Modifica, sulla voce Cerca e sostituisci, quindi cliccare sul pulsante Altre opzioni.
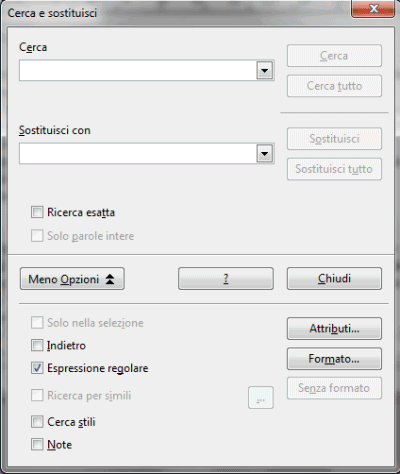
Il passo successivo consiste nello spuntare la casella Espressioni regolari e digitare, nella casella Cerca quanto segue: <([:alpha:]+)[^>]*>([^<]*)</(\1)>
Nella casella Sostituisci con, invece, si dovrà inserire semplicemente $2.

Il pulsante Cerca consentirà di rendersi conto di come le tag HTML vengano correttamente individuate ed evidenziate. Premendo il pulsante Sostituisci tutto, OpenOffice.org provvederà ad effettuare, in unico passaggio, tutte le sostituzioni.
E’ bene tuttavia osservare che le tag HTML saranno opportunamente rimosse se e solo se queste sono indicate nel modo corretto. Ad esempio, una tag HTML <b> che non è stata successivamente chiusa con </b> non verrà eliminata dal documento.
Per eliminare le altre tag che dovessero essere rimaste ancora presenti nel documento, si ricorra all’inserimento nel campo Cerca della stringa <[:alpha:]+[^>/]*/> lasciando vuota la casella Sostituisci con.
/https://www.ilsoftware.it/app/uploads/2025/04/outlook-email-spam-senza-spf-dmarc-dkim.jpg "Outlook: mail in spam da maggio 2025 senza questo requisito")
/https://www.ilsoftware.it/app/uploads/2025/03/thunderbird-lancia-thundermail-pro.jpg "Thunderbird cresce: nuovi servizi e un'email aperta per competere con Gmail e Outlook")
/https://www.ilsoftware.it/app/uploads/2025/03/european-alternatives.jpg "European Alternatives: esplode la domanda per i servizi europei amici della privacy")
/https://www.ilsoftware.it/app/uploads/2025/03/RDAP-sostituisce-WHOIS.jpg "Transizione da WHOIS a RDAP: implicazioni e vantaggi per la registrazione dei domini")