/https://www.ilsoftware.it/app/uploads/2023/05/img_4529-1.jpg "Riconoscimento ottico dei caratteri con Free OCR e Tesseract")
Di software OCR (sistema di riconoscimento ottico dei caratteri) freeware od opensource non ne esistono molti. Il mercato sino ad oggi è stato dominato, prevalentemente, dai prodotti di tipo commerciale.
Lo scenario potrebbe essere destinato a mutare, ancora una volta sotto l’azione di Google.
C’era una volta un progetto, nato – in collaborazione con HP – presso l’Università del Nevada. Correva l’anno 1985.
L’obiettivo consisteva nello sviluppare un OCR che operasse correttamente con tutti i generi di testo stampato.
Tesseract OCR, questo il nome del progetto, con la diffusione del web cominciò paradossalmente a perdere terreno, probabilmente soprattutto a causa della riorganizzazione di HP.
A circa vent’anni di distanza è arrivato Google. Il colosso di Mountain View nel 2005 decise di programmare la “rinascita” del progetto Tesseract OCR contribuendovi con aggiornamenti ed interventi correttivi tanto che ad Agosto 2006 l’azienda pose le basi per il rilascio di una nuova versione del software.
Tesseract è considerato come l’OCR più performante mai sviluppato sino ad oggi ma, almeno fino a queste tempo fa, presentava diverse lacune nell’interpretare correttamente caratteri speciali, non standard o comunque non facenti parte dell’alfabeto inglese.
Con un annuncio pubblicato da Google ad Aprile 2007, la società manifestò pubblicamente la sua intenzione di “sponsorizzare” il progetto OCRopus, sviluppato presso l’IUPR (“Image Pattern and Image Recognition”), un gruppo di ricerca istituito presso l’Università di Kaiserslautern, in Germania. Il motore di OCRopus poggia su un sistema di riconoscimento caratteri piuttosto avanzato sviluppato a metà degli anni ’90 e su innovative metodologie per l’analisi del layout di pagina messe a punto di recente.
Google ha già reso disponibile una prima versione di anteprima del prodotto che però opera per il momento soltanto su sistemi Linux e sfrutta direttamente “Tesseract OCR”. In questa pagina gli interessati possono documentarsi sulla procedura d’installazione.
OCRopus è stato inizialmente sviluppato su piattaforma Linux Ubuntu 6.10 in C++ e Python: come già evidenziato, è proprio Linux il sistema di riferimento scelto; il software verrà poi successivamente portato sugli altri sistemi.
Chi invece volesse saggiare le abilità di riconoscimento ottico dei caratteri di Tesseract OCR in ambiente Windows, può orientarsi su FreeOCR. Si tratta di un programma gratuito che poggia pressoché interamente sull’utilizzo del motore di Tesseract OCR.
Requisito indispensabile per poter utilizzare FreeOCR, è l’installazione del framework .NET 2.0 di Microsoft (qualora non aveste ancora provveduto ad installarlo sul vostro sistema, è possibile scaricare il file di setup “stand alone” da questa pagina; ad installazione avvenuta, ricordate di applicare le patch di sicurezza rilasciate da Microsoft).
Dopo aver scaricato FreeOCR e concluso l’installazione del programma, verrà presentata la finestra principale del software. Non aspettatevi un prodotto ugualmente ricco, nelle funzionalità, come i software commerciali più blasonati: dalla finestra principale di FreeOCR è possibile, semplicemente, avviare la scansione di un documento (Scan), aprire un’immagine precedentemente salvata (Open) e lanciare il riconoscimento dei caratteri (OCR).
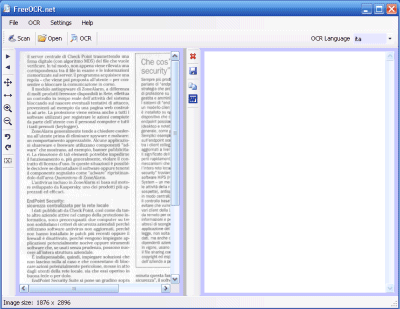
I piccoli pulsanti visualizzati nella barra degli strumenti verticale di FreeOCR permettono di effettuare alcune modifiche di base sull’immagine acquisita tramite scanner e che verrà successivamente sottoposta all’OCR.
Ricorrendo al menù OCR, Adjust image contrast, è possibile modificare parametri quali luminosità e contrasto con lo scopo di migliorare, eventualmente, i risultati ottenuti dopo l’effettuazione del riconoscimento ottico dei caratteri.
Tenendo premuto il tasto sinistro del mouse sull’immagine che riproduce il documento “scannerizzato” (riquadro di sinistra della finestra principale di FreeOCR), quindi trascinando il puntatore, si potrà selezionare un’area specifica da sottoporre al motore OCR.
Per ottenere migliori risultati, è bene provvedere a caricare subito i file della lingua italiana. E’ possibile scaricare la versione più aggiornata dal sito web del progetto Tesseract OCR (file tesseract-X.XX.ita.tar.gz). Il file compresso .tar.gz può essere aperto e gestito anche con un software qual è IzArc.
A questo punto, dopo aver chiuso FreeOCR, si dovranno copiare tutti i file con prefisso ita. nella sottocartella \tesseract\tessdata (presente nella directory ove si è installato FreeOCR). Nella medesima cartella si noterà la presenza di un gruppo di file analoghi con prefisso eng.
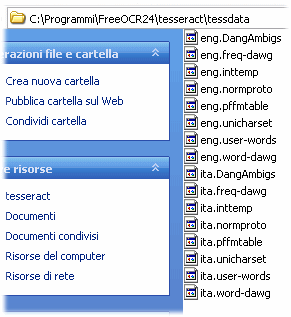
Avviando nuovamente FreeOCR, si dovrà selezionare la voce ita dal menù a tendina OCR Language, in alto a destra.
A questo punto è possibile avviare, dapprima, la scansione del documento da sottoporre ad OCR (Scan), selezionare eventualmente l’area d’interesse quindi premere il pulsante OCR.

Il risultato, con diverse tipologie di testo, è notevole. Gli errori commessi dal motore OCR possono essere corretti direttamente agendo sul riquadro di destra: il testo potrà quindi essere copiato in un word processor (ad esempio Word od OpenOffice) o salvato sotto forma di file .txt.
Complessivamente, FreeOCR è un ottimo software che porta in casa Windows “i servigi” di Tesseract OCR. Ogniqualvolta si acquisisce un testo tramite lo scanner per poi passarlo al motore OCR, è bene orientarsi sempre su una risoluzione di almeno 200 DPI in modo tale da ridurre il numero degli errori.
(3,9 MB circa).
/https://www.ilsoftware.it/app/uploads/2025/04/recall-windows-11-seconda-versione.jpg "Il ritorno di Microsoft Recall in Windows 11: memoria fotografica o incubo digitale?")
/https://www.ilsoftware.it/app/uploads/2025/04/wp_drafter_475972.jpg "Windows 11: con l'ultima build nuove funzioni AI e accessibilità")
/https://www.ilsoftware.it/app/uploads/2024/10/flyby11-forza-aggiornamento-windows-11.jpg "Flyby11 forza l'aggiornamento a Windows 11: cosa ne pensiamo noi ad aprile 2025")
/https://www.ilsoftware.it/app/uploads/2025/04/enclavi-vbs-windows.jpg "Microsoft abbandona le enclavi VBS in Windows 11 e in Windows Server: in quali versioni")