/https://www.ilsoftware.it/app/uploads/2024/06/intelligenza-artificiale-supera-intelligenza-umana.jpg "Quando l'intelligenza artificiale supererà quella umana: c'è una data?")
Nel panorama tecnologico attuale, l’intelligenza artificiale sta guadagnando sempre più rilevanza. I migliori chatbot fanno a gara per fornire risposte più accurate, argomentate e pertinenti ma, come abbiamo spesso rilevato, è il sottostante modello generativo a guidarne il comportamento. Di fronte a miglioramenti tangibili nella qualità delle risposte, come quelle fornite da GPT-4o (“omni“) di OpenAI oppure da Claude 3.5 Sonnet di Athropic, con i suoi Artifacts, una delle domande che ci viene rivolta più spesso è quando l’intelligenza artificiale supererà quella umana.
Spesso non si usa neppure il “se” ipotetico. Chi ci pone la domanda si limita a chiedere quando ci sarà il superamento delle abilità del cervello umano, non “se” ciò avverrà. Un qualcosa che tanti, dinanzi ai progressi registrati nel giro di pochi mesi, danno praticamente per scontato.
Nell’era dell’intelligenza artificiale e dei Large Language Models (LLM), è facile lasciarsi trasportare dall’entusiasmo. Il cervello umano rimane tuttavia un prodigio di efficienza e complessità, superando di gran lunga anche i più avanzati sistemi basati sull’intelligenza artificiale generativa come come GPT-4 e GPT-4o.
Insomma, prima di dare credito a chi dice che tra “n” anni l’intelligenza artificiale supererà di “k” volte quella umana, facciamo qualche riflessione. E muoviamoci con i proverbiali piedi di piombo.
Dai bit ai vettori: un cambiamento epocale
Per comprendere appieno il funzionamento delle rappresentazioni vettoriali, fondamentali nei modelli generativi, dobbiamo partire dalle fondamenta. Il codice binario, alla base di qualunque elaborazione informatica, si basa su lunghe sequenze di 0 e 1. Il numero decimale 4, ad esempio, è rappresentato come “100” in binario (0 * 20 + 0 * 21 + 1 * 22 = 4). I computer convertono i numeri binari nel sistema decimale che noi umani usiamo quotidianamente.
Il passo successivo è la trasformazione di questi numeri in qualcosa di comprensibile per gli esseri umani. La codifica ASCII permette ad esempio di associare numeri a lettere. Ad esempio, il numero 65 rappresenta la lettera “A”. Combinando queste rappresentazioni numeriche di lettere, i computer possono formare parole e frasi.
La semplice rappresentazione numerica delle parole ci restituisce tuttavia un problema fondamentale. C’è la totale mancanza di contesto. Si prenda ad esempio la parola “torre” in italiano: essa ha sempre la stessa rappresentazione numerica in ambito informatico, indipendentemente dal contesto in cui essa è usata. Ovviamente, questo non riflette la complessità e le sfumature del linguaggio umano.
Cosa sono gli embedding contestualizzati e i vettori nel campo dell’intelligenza artificiale
Per superare il limite descritto in precedenza, sono stati sviluppati gli embedding contestualizzati al fine della rappresentazione delle parole. Si tratta di un approccio che permette di generare rappresentazioni numeriche uniche per le parole, basate sul loro contesto e significato semantico. Ecco quindi che il termine “torre” avrà una rappresentazione numerica quando affiancata da “Eiffel” o “di Pisa” o, ancora, “spagnola” o “costiera” o “di cubi“. Parole con significati simili in contesti simili hanno rappresentazioni numeriche più vicine tra loro.
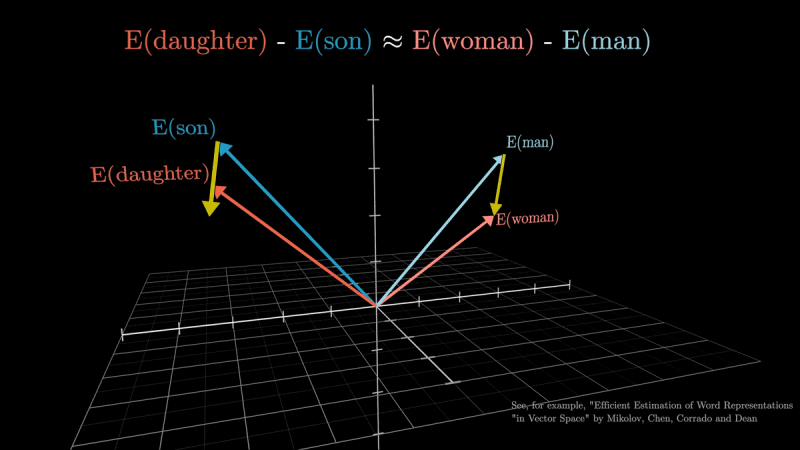
L’immagine è tratta dal video YouTube di 3Blue1Brown.
Le rappresentazioni numeriche sono trasformate in vettori all’interno di spazi multidimensionali. OpenAI, ad esempio, utilizza uno spazio a 1536 dimensioni per i suoi modelli, un valore estremamente elevato. Quest’elevata dimensionalità permette di catturare sfumature incredibilmente sottili di significato e contesto.
Con spazi vettoriali così vasti, emerge quello che in matematica e in informatica è noto come “maledizione della dimensionalità“. L’espressione riflette il fenomeno per cui diventa estremamente difficile e computazionalmente costoso trovare punti simili in spazi ad alta dimensionalità.
Per affrontare questo problema, sono state sviluppate tecniche sofisticate: tra le più “gettonate” ci sono ANNS (Approximate Nearest Neighbour Search) e HNSW (Hierarchical Navigable Small World). La prima aiuta a individuare vettori simili in modo efficiente, sacrificando un po’ di precisione per guadagnare in velocità; la seconda si ispira al “piccolo mondo” delle reti sociali (la maggior parte dei punti può essere raggiunta seguendo pochi passaggi).
La complessità matematica dei vettori usati da OpenAI e da altri competitor
La dimensionalità di uno spazio vettoriale è il numero di coordinate necessarie per specificare univocamente un punto in quello spazio. Nel caso di OpenAI, questo numero è appunto 1536. Sono un’infinità se si pensa, come semplice confronto, a un classico vettore di uno spazio fisico a tre dimensioni x, y, z.
Partendo dall’assunto che ogni dimensione possa assumere, per semplicità, 256 valori distinti (8 bit), il numero totale di possibili vettori unici in questo spazio è:
2561536 ≈ 1,3 * 103710
Questo numero è incredibilmente grande e supera di gran lunga il numero stimato di atomi nell’universo osservabile (circa 1080).
Assumendo una precisione a 32 bit per ogni dimensione, ogni vettore richiede 1536 * 32 bit = 49.152 bit = 6.144 byte. Questo significa che anche solo un milione di vettori richiederebbe circa 6 GB di memoria.
Rappresentazioni vettoriali nell’intelligenza artificiale: applicazioni pratiche e sfide
I concetti di embedding e di spazi vettoriali sono essenziali per memorizzare e recuperare informazioni in modo efficiente nell’era dell’intelligenza artificiale.
Come abbiamo visto in altri approfondimenti, la vettorizzazione permette di trasformare il testo (ma anche altri elementi, come immagini e audio) in vettori numerici. I vettori sono incorportati in spazi ad alta dimensionalità. Apposite tecniche di ricerca approssimata facilitano l’individuazione di informazioni simili.
Nell’articolo sui segreti del meccanismo di attenzione, fondamentale per il funzionamento delle intelligenze artificiale e, in particolare, dei modelli basati su Transformer, abbiamo visto che l’embedding è il primo passo nell’elaborazione di un token (ovvero di una parola o di parte di essa, parlando di modelli che gestiscono il linguaggio naturale).
L’embedding, come abbiamo visto, abbina a ciascun token un vettore multidimensionale: questi vettori riflettono le associazioni semantiche, consentendo al modello di “comprendere” (o meglio ancora stimare, derivare) le relazioni tra le parole. Date un’occhiata alle Vector Search Oracle per approfondire l’argomento e comprendere come le informazioni vettoriali rappresentino un tesoro prezioso anche in ambito business.
L’intelligenza artificiale “non pensa”: una chiarificazione importante
Un punto cruciale da tenere a mente è che sistemi come GPT-4 e GPT-4o, nonostante le loro capacità impressionanti, non “pensano” nel senso umano del termine. Questi sistemi operano attraverso complesse associazioni di numeri e approssimazioni basate su vasti set di dati.
Non c’è una vera “comprensione” del testo o del contesto, ma piuttosto una sofisticata manipolazione di rappresentazioni numeriche. Quando un modello generativo produce una risposta a valle di una richiesta (prompt) dell’utente, sta essenzialmente selezionando token (unità di testo) basandosi su probabilità calcolate. Non sta affatto “ragionando” nel modo in cui farebbe un essere umano.
La “ricetta” matematico-probabilistica alla base del funzionamento dei moderni modelli generativi, mette ben in evidenza perché i chatbot e in generale le intelligenze artificiali possano a volte produrre risposte incoerenti o palesemente false, pur dimostrando – almeno apparentemente – una grande autorevolezza e proprietà di linguaggio.
Con buona pace di Elon Musk, i punti sin qui posti sul tavolo ci aiutano a capire quanto siamo ancora lontani da una vera Intelligenza Artificiale Generale (AGI) che possa “pensare” in modo simile agli umani.
Proprio ad aprile 2024 parlavamo di questo tema con i portavoce Oracle, confrontandoci sul futuro dell’intelligenza artificiale.
La sorprendente efficienza del cervello umano e le sue caratteristiche
Nonostante la complessità, la potenza e la versatilità dei modelli generativi di oggi, il cervello umano rimane incredibilmente superiore in termini di efficienza. Rene Haas, CEO di ARM, ha recentemente calcolato quanta energia consumano le intelligenze artificiali odierno, spronando tutti a rivedere gli standard attuali e gli obiettivi futuri.
Vi lasciamo un dato “secco”: il cervello umano impegna l’equivalente di 24 Watt di potenza all’ora; GPT-4 necessita di circa 7,5 MW all’ora. Il confronto è impietoso: il modello generativo di OpenAI consuma più di 312.500 volte l’energia di cui necessita il cervello di un uomo.
Considerando che solo il 5% dell’attività cognitiva umana è cosciente, l’efficienza del cervello potrebbe essere fino a 3 milioni di volte superiore a GPT-4.
Il cervello umano, con i suoi 86 miliardi di neuroni, rappresenta il punto di riferimento per lo sviluppo delle intelligenze artificiali. Tuttavia, è fondamentale comprendere che:
- Il cervello non utilizza algoritmi nel senso tradizionale del termine.
- La sua complessità supera di gran lunga quella dei sistemi di IA attuali.
- Il cervello è un “contenitore” di intelligenza, non l’intelligenza stessa.
L’intelligenza umana si distingue per la sua capacità di risolvere problemi in modo flessibile e adattativo, caratteristica che l’intelligenza artificiale cerca di emulare.
L’intelligenza artificiale si ispira alle caratteristiche del cervello
Le intelligenze artificiali generative non sono e non possono essere una copia del cervello umano. Sono piuttosto modelli semplificati che cercano di replicarne alcune funzionalità. Questa distinzione è cruciale per comprendere i punti di forza e i limiti di entrambi.
Qualunque modello generativo eccelle in compiti specifici ma fa fatica con il “buon senso” e le situazioni impreviste. L’AGI, inoltre, è un obiettivo ancora distante da perseguire. Gli esseri umani acquisiscono e migliorano le loro abilità attraverso le esperienze di vita, l’apprendimento versatile, l’osservazione e il ragionamento indipendente. Al contrario, le intelligenze artificiali seguono percorsi di apprendimento più rigidi e faticano ad adattarsi a situazioni impreviste o “casi limite”.
Il dibattito sulla coscienza
La questione della coscienza nell’ambito delle intelligenze artificiali è particolarmente complessa. Alcuni studiosi sottolineano che la nostra comprensione della base fisica della coscienza umana è già di per sé ancora limitata, rendendo difficile prevedere se e come le intelligenze artificiali possano in futuro sviluppare una forma di coscienza.
Un gruppo di scienziati ritiene che la coscienza richieda un’esperienza corporea e la necessità di affrontare problemi di sopravvivenza e riproduzione (da qui gli studi sulla bioinformatica in corso di sviluppo; vedere più avanti). Altri teorizzano che la coscienza possa emergere come proprietà di sistemi sufficientemente complessi, suggerendo che l’intelligenza artificiale possa eventualmente sviluppare forme di coscienza diverse da quella umana.
Tuttavia, la generazione di idee veramente originali e il pensiero astratto rimangono sfide significative per l’intelligenza artificiale. Soprattutto se si considerano gli aspetti energetici.
La sfida per il futuro sarà quella di sviluppare sistemi artificiali che possano complementare e potenziare l’intelligenza umana, piuttosto che sostituirla.
La frontiera rappresentata dalla bioinformatica
Parallelamente, la nuova frontiera è quella del biocomputing, disciplina che unisce biologia, elettronica e informatica. Organoidi cerebrali cresciuti in laboratorio possono esse fatti diventare intelligenze organoidi vere e proprie. I computer bioibridi sono già una realtà, almeno sotto forma di prototipi.
Gli attuali organoidi cerebrali sono però troppo piccoli: ognuno di essi contiene circa 50.000 celle; per arrivare a un’intelligenza organoide ne servono 10 milioni secondo Thomas Hartung, docente presso la Johns Hopkins University.
Credit immagine in apertura: iStock.com – BlackJack3D
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")
/https://www.ilsoftware.it/app/uploads/2024/07/chip-IA-openai.jpg "OpenAI lancia Flex Processing: rivoluzione dei costi API per modelli AI")
/https://www.ilsoftware.it/app/uploads/2025/04/grok-lg-ai-emotiva-pubblicita.jpg "LG lancia l'AI emotiva sulle Smart TV: pubblicità su misura per i tuoi sentimenti")
/https://www.ilsoftware.it/app/uploads/2025/01/chatgpt-impatto-ambientale-consumo-acqua.jpg "ChatGPT o3: la rivoluzione nella geolocalizzazione tramite immagini")