/https://www.ilsoftware.it/app/uploads/2024/01/polars.jpg "Polars, cos'è e come funziona la libreria per elaborare grandi volumi di dati")
Le attività di elaborazione dei dati sono divenute un elemento cruciale per il successo e la crescita delle aziende. La capacità di raccogliere, analizzare ed estrarre informazioni di valore da grandi volumi di dati si traduce in un prezioso vantaggio competitivo. Con l’incremento esponenziale dei volumi di dati da elaborare, le realtà d’impresa si trovano di fronte a nuove sfide e complessità.
I dati, tuttavia, forniscono una solida base per prendere decisioni informate. Analizzando i dati aziendali, è possibile ottenere una visione chiara delle performance, identificare tendenze e stimare risultati futuri. Le aziende possono identificare inefficienze nei processi operativi e apportare miglioramenti mirati, con evidenti benefici sul versante dell’ottimizzazione delle risorse e della riduzione dei costi. È inoltre possibile venire incontro alle esigenze della clientela in maniera più puntuale, individuare nuove opportunità di mercato e sviluppare prodotti e servizi innovativi.
Polars è una libreria di analisi e manipolazione di dati tabulari progettata per essere veloce ed efficiente, in particolare per operazioni svolte su grandi set di dati. Grazie all’implementazione in Rust e all’uso del parallelismo, Polars può sfruttare al massimo le capacità dei moderni processori.
![]()
Molte operazioni in Polars sono lazy, il che significa che non sono immediatamente eseguite bensì pianificate per essere gestite in modo efficiente in tempi successivi. Uno schema che contribuisce a migliorare le prestazioni complessive, poiché evita di calcolare valori intermedi inutili.
La libreria offre inoltre una vasta gamma di funzionalità per manipolare dati tabulari, inclusi filtri, aggregazioni, ordinamenti e molte altre operazioni più comuni. Supporta join e merge efficienti tra set di dati, consentendo di combinare dati provenienti da più fonti in modo rapido e semplice. Può gestire dati in molteplici formati, tra cui CSV e JSON.
Le basi del funzionamento di Polars
Polars fa perno su di una struttura dati chiamata DataFrame, simile al concetto di DataFrame in pandas (Python) e in R. Questa struttura contiene colonne di dati omogenee e consente di eseguire operazioni su di esse. Presentando il funzionamento di DuckDB ci eravamo già soffermato sui DataFrame: DuckDB, infatti, permette di usare i dati memorizzati in qualunque formato per creare database “on-the-fly“, accessibili anche dalla memoria RAM al fine di massimizzare le prestazioni. Tra le varie integrazioni, DuckDB offre anche quella per Polars.
Le operazioni in Polars sono descritte mediante l’uso di apposite espressioni, che esprimono le trasformazioni da applicare sui dati in corso di elaborazione. Le espressioni possono essere lazy, come spiegato in precedenza, in modo da massimizzare l’efficienza e sfruttare le ottimizzazioni e il parallelismo offerti dalla libreria.
Sebbene implementato in Rust, Polars mette a disposizione anche un’interfaccia Python che consente agli sviluppatori di utilizzare la libreria all’interno di progetti realizzati ricorrendo a questo specifico linguaggio di programmazione.
La libreria pandas, ampiamente utilizzata per la manipolazione e l’analisi dei dati, può risultare poco efficiente su grandi dataset. Ed è proprio qui che entra in gioco Polars: ha una struttura nel complesso simile a pandas ma è spiccatamente orientato alle prestazioni.
Mentre pandas e Polars sono librerie di analisi dati, il già citato DuckDB è un database che consente anche l’esecuzione di query SQL. Ciò lo rende particolarmente utile per quei programmatori che hanno maggiore dimestichezza proprio con il linguaggio SQL. Anche DuckDB è progettato per offrire prestazioni elevate, ma in questo caso il focus è sulla gestione di dati in formato database.
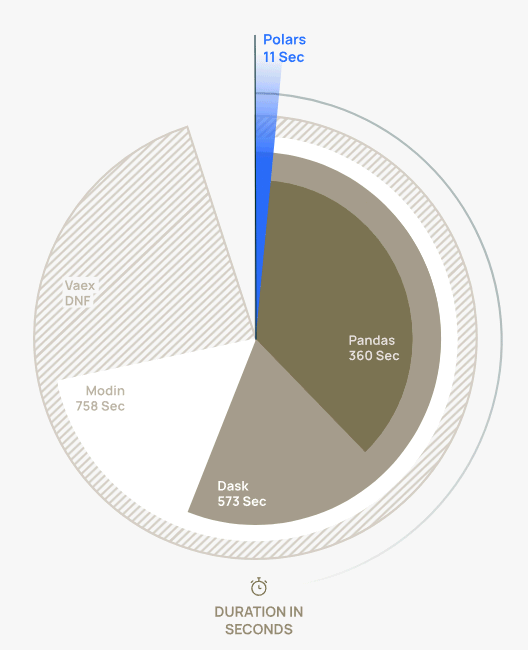
Immagine tratta dal sito ufficiale del progetto.
La filosofia di Polars
Obiettivo di Polars è quello di fornire una libreria basata su DataFrame estremamente veloce in grado di:
- Sfrutti tutti i core disponibili sulla macchina in uso.
- Ottimizzare le query per ridurre il carico di lavoro o inutili allocazioni di memoria.
- Gestire set di dati molto più grandi della RAM disponibile sul sistema.
- Offrire un’API coerente e prevedibile.
- Utilizzare uno schema rigoroso: i tipi di dati dovrebbero essere noti prima dell’esecuzione della query.
Il software si impegna a ridurre copie ridondanti dei dati, usare la cache in maniera efficiente, minimizzare la concorrenza durante la gestione delle attività parallelizzate, elaborare i dati a blocchi e riutilizzare in modo intelligente le assegnazioni di memoria.
Come installare e usare Polars
Per iniziare a usare Polars, è necessario installare la libreria e poi importarla nel proprio ambiente di sviluppo. Per servirsi di Polars all’interno di un progetto Python basta digitare il comando che segue nella finestra del terminale:
pip install polars
Il codice Python seguente non fa altro che creare un semplicissimo DataFrame di esempio per poi estrarre, mediante Polars, i dati delle righe che presentano il valore della colonna “Età” superiore a 40:
import polars as pl
# Creare un DataFrame
data = {'Name': ['Matteo', 'Michele', 'Luca', 'Giordano'],
'Eta': [44, 45, 35, 22],
'Citta': ['Roma', 'Firenze', 'Milano', 'Trieste']}
df = pl.DataFrame(data)
# Visualizzare il DataFrame
print("DataFrame originale:")
print(df)
# Filtrare i dati (es. selezionare le righe con età indicata superiore a 40 anni)
filtered_df = df.filter(df['Eta'] > 40)
# Visualizzare i dati filtrati
print("\nDati filtrati:")
print(filtered_df)
Ovviamente, Polars può essere utilizzato anche con altri linguaggi di programmazione. La scelta più ovvia è Rust, essendo la libreria sviluppata proprio su di esso. È comunque possibile invocare semplicemente la libreria da codice JavaScript, installandola mediante il popolare runtime Node.js.
Espressioni: le fondamenta della libreria per l’elaborazione dati
L’abbiamo anticipato poco fa: le espressioni sono il punto cardine si Polars e ne costituiscono l’ossatura. La libreria, infatti, offre una struttura versatile che approccia facilmente le query più semplici e può essere utilizzata anche per affrontare situazioni più complesse. Le seguenti possono essere considerate direttive fondamentali per tutte le interrogazioni elaborate ricorrendo a Polars:
selectfilterwith_columnsgroup_by
Per selezionare una colonna, basta definire il DataFrame dal quale estrarre dati e, in secondo luogo, selezionare i dati di proprio interesse. L’opzione di filtro consente di creare un sottoinsieme del DataFrame, come abbiamo visto nell’esempio precedente. Ovviamente è possibile creare filtri complessi che coinvolgono più colonne.
Con with_columns si ha modo di creare nuove colonne per le analisi in corso. Ricorrendo a group_by, invece, si può sfruttare una funzione che raggruppa il contenuto di un DataFrame in base ai valori presenti in una o più colonne. Quest’operazione è utile quando si desidera eseguire analisi o calcoli specifici su sottoinsiemi di dati che condividono gli stessi valori in una o più colonne.
Combinare più DataFrame, l’altro grande vantaggio di Polars
Una delle caratteristiche distintive di Polars, come abbiamo accennato, è la capacità di combinare DataFrame. Questa possibilità è davvero utile, soprattutto quando si lavora con dataset di grandi dimensioni.
Con la concatenazione orizzontale, si possono unire due DataFrame in base alle colonne. Ad esempio, se si dovessero gestire due DataFrame contenenti colonne diverse, è possibile combinarli orizzontalmente per ottenere un unico DataFrame che abbracci tutte le colonne. Viceversa, la concatenazione verticale consente di unire due DataFrame in base alle righe: utile quando si volesse popolare un Dataframe a partire dalle righe contenute in un altro.
Un po’ come avviene con i join SQL, le operazioni merge e join di Polars consentono di combinare DataFrame in base a colonne specifiche. Nello specifico, con il merging si possono accoppiare DataFrame a partire dalle colonne indicate usando vari tipi di join come “inner”, “left”, “outer” e “right”. Il metodo join in Polars è una forma semplificata di merge.
A valle della combinazione di DataFrame, è possibile eseguire operazioni di raggruppamento e aggregazione sui dati risultanti per poi svolgere ulteriori elaborazioni. Il tutto contando sui significativi miglioramenti prestazionali, diretta conseguenza dell’elaborazione parallela. Il tempo di esecuzione delle operazioni risulterà così minimo se confrontato con gli approcci di tipo tradizionale.
Per approfondire, suggeriamo di fare riferimento alla guida utente ufficiale, ospitata sul sito Web di Polars.
Credit immagine in apertura: iStock.com – champpixs
/https://www.ilsoftware.it/app/uploads/2025/04/codex-cli-openai-cos-e-come-funziona.jpg "Codex CLI: cos'è l'agente AI di OpenAI che scrive e interpreta codice dal terminale")
/https://www.ilsoftware.it/app/uploads/2025/04/compleanno-git-20-anni-linus-torvalds.jpg "Git compie 20 anni e Linus Torvalds parla della sua creatura")
/https://www.ilsoftware.it/app/uploads/2025/04/sorgente-altair-basic.jpg "Microsoft rilascia il suo codice sorgente! Per festeggiare 50 anni di attività")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")