/https://www.ilsoftware.it/app/uploads/2023/11/openchat-modello-generativo-open-source.jpg "OpenChat, il modello generativo open source che supera ChatGPT")
Tra i molteplici LLM (modelli linguistici di grandi dimensioni) presentati nell’ultimo periodo, tra quelli che si pongono in maggiore evidenza c’è sicuramente OpenChat. Si tratta di uno strumento presentato a novembre 2023 che conta “soltanto” 7 miliardi di parametri (7B) ma che riesce a superare le performance di ChatGPT (OpenAI) in molteplici benchmark di riferimento.
Cos’è e come funziona OpenChat
OpenChat è un’innovativa libreria che integra modelli linguistici open source, sottoposti a un’attenta attività di ottimizzazione (fine tuning).
C-RLFT (Conditioned Reinforcement Learning Fine-tuning) è una strategia utilizzata da OpenChat nel processo di addestramento dei modelli linguistici che si ispira all’apprendimento rinforzato offline. L’apprendimento rinforzato è una tecnica sfruttata per addestrare le intelligenze artificiali attraverso l’interazione con l’ambiente, ricevendo feedback sotto forma di ricompense o “punizioni”. L’indicazione offline fa riferimento al fatto che l’addestramento non avviene in tempo reale, ma utilizza dati raccolti in precedenza.
Nel caso di OpenChat, l’apprendimento rinforzato offline è utilizzato per per migliorare le risposte attraverso la valutazione delle conversazioni passate e il conseguente aggiornamento del modello.
Utilizzando OpenChat è possibile ottenere prestazioni paragonabili con quelle di ChatGPT, persino utilizzando una GPU “consumer” (ad esempio una NVidia Geforce RTX 3090).
Principali caratteristiche del modello
- Dimensioni del modello e prestazioni: il modello da 7 miliardi di parametri (OpenChat-3.5-7B) che ha ottenuto risultati comparabili con ChatGPT su diversi benchmark. OpenChat-3.5 ha ottenuto punteggi impressionanti su vari benchmark, superando altri modelli open source, come OpenHermes 2.5 e OpenOrca Mistral, su metriche come MT-Bench, AGIEval, BBH MC, TruthfulQA, MMLU, HumanEval, BBH CoT e GSM8K.
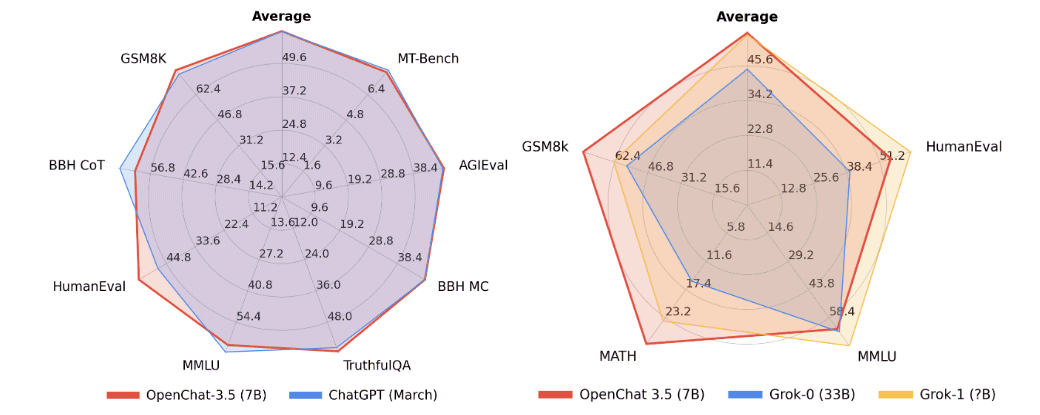
- Aggiornamenti frequenti: OpenChat rilascia regolarmente nuove versioni e aggiornamenti. Ad esempio, la pubblicazione del modello OpenChat-3.5-7B è recente e risale al 1° novembre 2023.
- Licenza e accessibilità: uno strumento come OpenChat è distribuito sotto la licenza Apache-2.0, rendendolo open source e accessibile. Gli utenti possono installarlo utilizzando
pipoconda. - API server: OpenChat offre un’API pronta da usare in ambienti di produzione che, tra l’altro, risulta pienamente compatibile con il protocollo OpenAI API. L’architettura software consente, tra le altre cose, di elaborare dinamicamente a blocchi (batch) le richieste in ingresso.
- Interfaccia utente Web (Web UI): Accanto alle API per facilitare il dialogo con i dispositivi client, OpenChat fornisce un’interfaccia utente Web che semplifica l’interazione con il modello.
Come provare OpenChat
Gli sviluppatori di OpenChat hanno messo a disposizione una demo online gratuita che consente di inviare una serie di prompt al modello generativo e valutare le risposte fornite.
Nella pagina principale del chatbot open source, si possono creare conversazioni e prompt. Il sistema è in grado di tenere traccia delle informazioni trasferitegli durante una stessa conversazione.
È inoltre possibile modificare i valori di Temperatura in modo da rendere l’output più casuale e “creativo” (valori più elevati) oppure, viceversa, più focalizzato e preciso (valori più bassi).
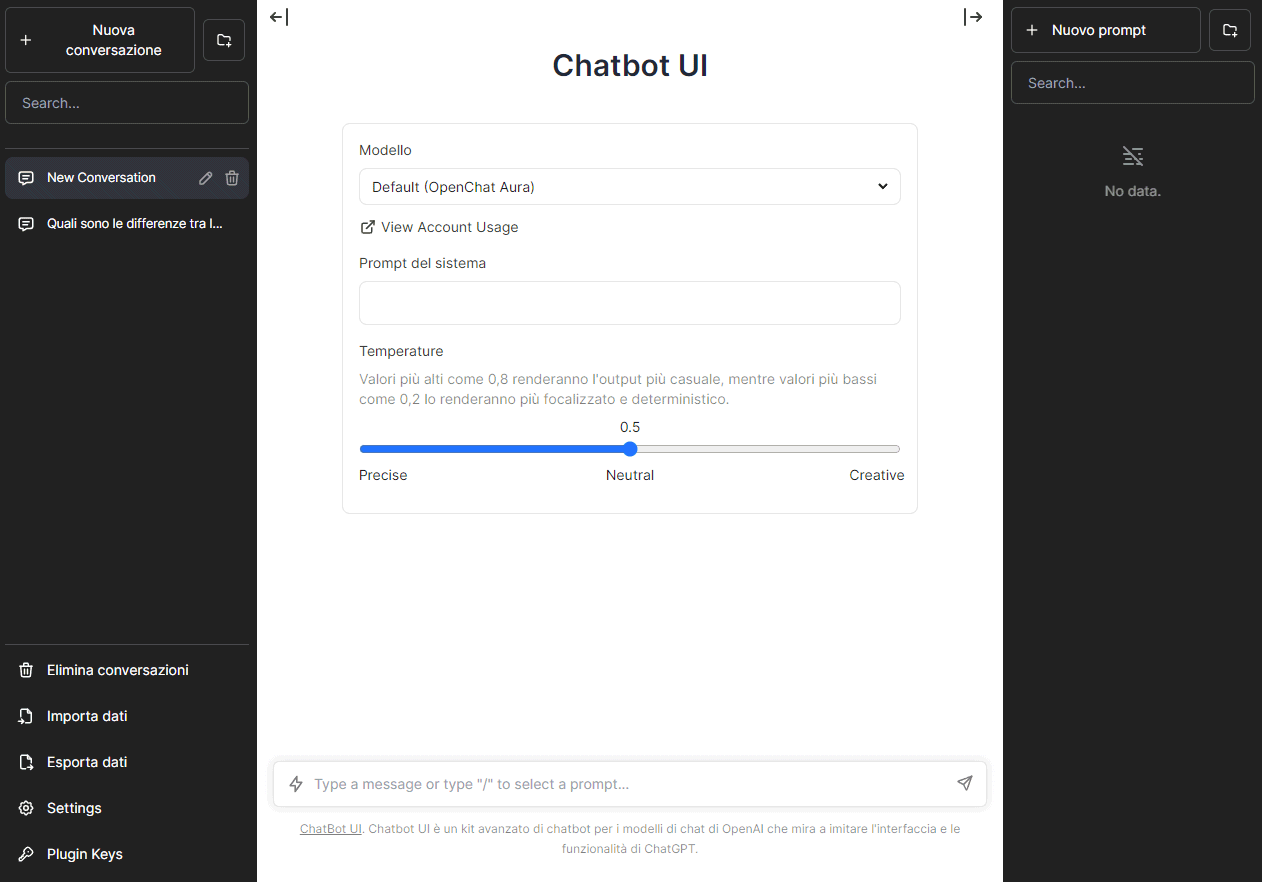
Cliccando su Settings, nella colonna di sinistra, si può anche specificare un tema diverso e optare per quello a sfondo chiaro.
Le conversazioni possono essere esportate e importate, cancellate e gestite come meglio si ritiene opportuno.
Per installare e usare OpenChat in locale, la soluzione più semplice consiste nel servirsi di Ollama caricando il framework all’interno di un container Docker:
docker exec -it ollama ollama run openchat
Maggiori informazioni sono disponibili sul repository ufficiale GitHub di OpenChat.
Addestramento e personalizzazione
Il modello linguistico alla base del funzionamento di OpenChat può anche apprendere dalle conversazioni fornite in input adattando il suo comportamento e le risposte ai dati messi a disposizione. Successive attività di addestramento (training) permettono di adattare il modello alle specifiche esigenze dell’utente e del contesto.
Prima di iniziare l’addestramento, è necessario selezionare un modello di base su cui effettuare il fine tuning. OpenChat supporta modelli come Llama 2 e Mistral, ciascuno con dimensioni e caratteristiche specifiche.
I dati di addestramento sono ovviamente essenziali. In OpenChat, le conversazioni sono rappresentate sotto forma di oggetti JSON: ogni linea corrisponde a un oggetto “Conversation” contenente messaggi di “user” e “assistant” con relative etichette e pesi.
Il dataset che si desidera “dare in pasto” a OpenChat deve essere pre-tokenizzato. Questo processo prevede la conversione dei dati in un formato tokenizzato utilizzando uno specifico modello. Si tratta di un passaggio importante per velocizzare la fase di addestramento.
L’addestramento vero e proprio coinvolge l’ottimizzazione dei parametri del modello: OpenChat utilizza DeepSpeed, variante di PyTorch per l’addestramento distribuito su hardware accelerato mediante GPU. Durante l’addestramento, vengono generati checkpoint del modello a intervalli regolari. Si tratta di differenti “stati” del modello generativo: alla fine dell’addestramento, è possibile valutare i checkpoint per scegliere la versione del modello che si considera migliore.
Credit immagine in apertura: iStock.com/Shutthiphong Chandaeng
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")
/https://www.ilsoftware.it/app/uploads/2025/04/leccare-un-tasso-due-volte.jpg "Ecco perché non puoi leccare un tasso due volte")