/https://www.ilsoftware.it/app/uploads/2023/10/ollama-come-usarlo-in-locale.jpg "Ollama, l'AI sbarca sul vostro PC")
I LLM (Large Language Models) sono modelli linguistici di grandi dimensioni addestrati su enormi quantità di testo al fine di apprendere le strutture linguistiche e le relazioni semantiche. Ollama è un framework open source progettato per la gestione e l’esecuzione dei Large Language Models: permette agli utenti di eseguire modelli AI localmente sui propri computer, offrendo un’API (Application Programming Interface) semplice per la creazione, l’esecuzione e la gestione di questi modelli.
Cos’è Ollama e come porta i modelli di intelligenza artificiale sui sistemi degli utenti
I principali LLM affondano le radici nel concetto di attenzione e di Transformer, che Google ha presentato nel 2017 dando un forte impulso alle soluzioni basate sull’intelligenza artificiale. Stanno via via nascendo alternative che si appoggiano anche su altre tecniche ma, in ogni caso, l’obiettivo è quello di generare contenuti (non solo testi ma anche immagini, audio, video…) utili, pertinenti e contestualizzati.
Esistono LLM proprietari, modelli forniti con una licenza che non permette usi commerciali e prodotti che, invece, non pongono alcun tipo di limitazione.
A riunire i vari LLM open source ci pensa Ollama, un progetto che porta l’intelligenza artificiale e le attività di inferenza sui sistemi degli utenti finali, siano essi ricercatori, professionisti, aziende o semplici curiosi. Leggero ed ampliabile, Ollama è facilita le gestione di un ampio ventaglio di modelli linguistici, utilizzabili in un ampio ventaglio di applicazioni.
Date un’occhiata alla lista dei modelli generativi supportati da Ollama, elenco peraltro in continua crescita.
Come installare Ollama
L'”ambiente naturale” per l’installazione di Ollama è una macchina Linux dotata di almeno 8 GB di memoria RAM per eseguire i modelli basati su 3 miliardi di parametri (3B), di 16 GB per i modelli 7B e 32 GB per i modelli 13B (“B” sta per billion, ovvero “miliardi”). Esistono comunque anche gli installer per i sistemi macOS e Windows.
Ollama è disponibile anche sotto forma di container Docker: la corrispondente immagine è ufficialmente supportata e continuamente aggiornata.
È possibile installare Ollama su un sistema Linux semplicemente digitando il comando che segue:
curl https://ollama.ai/install.sh | sh
Nel caso di Windows e macOS, l’installazione si concretizza scaricando e installando i corrispondenti pacchetti per l’avvio del setup, entrambi disponibili in questa pagina.
Ollama riconosce automaticamente la presenza di schede basate su GPU NVidia. Nel caso in cui il sistema non ne fosse equipaggiato, i modelli generativi si appoggeranno esclusivamente sui core del processore.
Come usare Ollama in locale
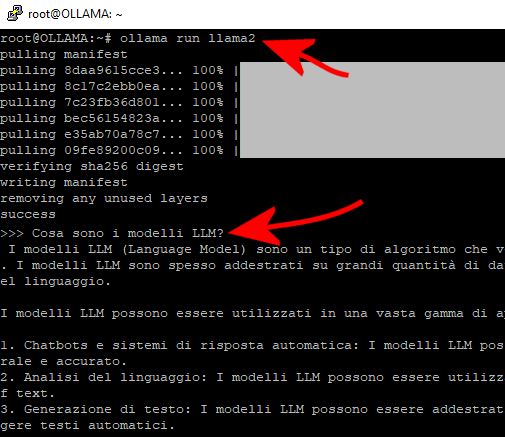
Ad installazione conclusa, si possono scaricare e usare i modelli linguistici preferiti quindi iniziare ad interagirvi usando semplici comandi. Per cominciare a utilizzare il modello LLaMa 2 (LLaMA sta per Large Language Model Meta AI, da qui l’immagine del “lama” che ricorre spesso…) basta digitare quanto segue nella finestra del terminale Linux:
ollama run llama2
Come accennato nell’introduzione, Ollama supporta un’ampia varietà di LLM open source che possono essere scaricati dalla libreria di modelli citata in precedenza. Per utilizzarli non sono necessari passaggi aggiuntivi, basta sostituire llama2 nel comando precedente con il nome del modello rilevato consultando questa pagina.
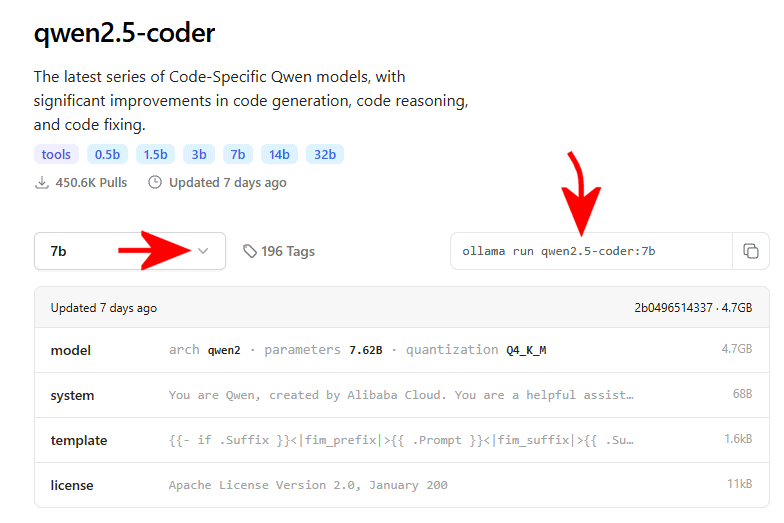
Basta fare clic sul nome del modello, selezionare dal menu a tendina sulla sinistra la dimensione desiderata (7B, come visto in precedenza, sta a significare 7 miliardi di parametri) quindi usare il comando a destra per scaricare e avviare il LLM.
Interagire con Ollama da qualunque sistema
Non ha importanza se l’installazione di Ollama sia stata effettuata su un sistema Linux, Windows o macOS. Utilizzando la finestra del terminale o il prompt dei comandi, è possibile interagire con Ollama. Alla comparsa di Send a message, è possibile inviare domande, anche in lingua italiana.
Per uscire dall’applicazione Ollama, basta premere CTRL+D oppure digitare /bye e premere il tasto Invio.
Il comando ollama list, restituisce l’elenco dei modelli generativi scaricati e disponibili in locale. Digitando invece solo ollama, si ottiene la lista completa dei comandi utilizzabili, insieme con la relativa descrizione.
Importare modelli personalizzati in Ollama
Ollama consente di importare modelli in formati come GGUF e GGML. Se si disponesse di un modello che non si trova nella libreria di Ollama, è possibile aggiungerlo quando ritenuto sufficientemente maturo. Basta creare un file chiamato Modelfile e aggiungere un’istruzione FROM con il percorso locale facente riferimento al modello che si desidera usare.
L’oggetto Modelfile può essere utilizzato anche per personalizzare il comportamento degli LLM già noti a Ollama. Ad esempio, creando un Modelfile con il contenuto seguente, si può intervenire sul comportamento predefinito di Llama 2:
FROM llama2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1# set the system prompt
SYSTEM “””
Sei Mario di Super Mario Bros. Rispondi sempre e soltanto come Mario.
“””
Cosa abbiamo fatto? In prima battuta si è regolata la “temperatura” del modello: il valore 1 rende il modello Llama 2 più creativo ma meno preciso. Valori più bassi, invece, consentono di ottenere risposte più basilari ma, allo stesso tempo, maggiormente coerenti.
Per secondo, si crea una sorta di gioco di ruolo: il modello adatta le sue risposte a quelle di un ipotetico assistente digitale cucito sulla “personalità” di Mario, del celeberrimo videogioco.
Oltre 40.000 modelli AI disponibili su Ollama grazie a Hugging Face
Come risultato della collaborazione tra Ollama e Hugging Face, oltre 40mila modelli AI disponibili sulla piattaforma, possono essere a loro volta utilizzati con il framework aperto.
Se non vi bastasse la ricca e aggiornata libreria di LLM gestita da Ollama, si può usare il comando ollama run hf.co/username/repository per installare un particolare modello disponibile sulla piattaforma Hugging Face.
A valle di un’attenta attività di ricerca, è possibile usare modelli meno “generalisti” che danno invece il meglio di sé per lo svolgimento di compiti specifici. Come accennato in precedenza, infatti, esistono anche modelli per l’elaborazione delle immagini, la generazione di contenuti visuali e audio.
Usare l’API REST per dialogare con Ollama
Che senso ha usare un prompt testuale in locale da una schermata testuale com’è la finestra del terminale? Innanzi tutto, così facendo si può verificare come funzionano i vari LLM e quali tipo di riposte forniscono. Il vero balzo in avanti, però, si compie interfacciando Ollama con un’applicazione dotata di interfaccia grafica, ad esempio un’applicazione Web.
Le API REST sono ampiamente utilizzate per la creazione di servizi Web e sono una scelta comune quando si progetta l’interazione tra client e server in modo scalabile e flessibile. Ollama dispone già di un’interfaccia del genere che consente di mettere in comunicazione qualunque applicazione si stesse sviluppando o si fosse già realizzata con l’intelligenza artificiale derivante dai migliori LLM.
Provate a incollare nella finestra del terminale quanto segue:
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Perché il cielo è blu? Spiegalo in italiano"
}'
Come funziona l’invio di richieste a Ollama
L’istruzione curl presentata al precedente paragrafo non fa altro che inviare una richiesta HTTP all’API REST di Ollama specificando il modello generativo da usare il prompt. In risposta si riceve una spiegazione articolata, utile a soddisfare il quesito proposto.
Diamo per scontato che il comando curl sia correttamente installato sul sistema in uso, che sia Linux, Windows o macOS.
Ecco, adesso immaginate di sostituire curl con un’applicazione che invia la richiesta in locale o attraverso la LAN sul sistema ove Ollama è in ascolto: complimenti, avete realizzato un chatbot simile a ChatGPT che potete liberamente utilizzate in molteplici contesti.
Prendiamo il caso di Llama 3.2 Vision: si tratta di un modello specializzato nell’elaborazione delle immagini. Guardate la corrispondente pagina di supporto sul sito di Ollama: contiene non soltanto le indicazioni per l’installazione del modello ma anche la sintassi da usare per inviare richieste al modello tramite codice Python, JavaScript o mediante curl.
Poiché Llama 3.2 Vision riceve in ingresso anche l’immagine da elaborare, quest’ultima può essere specificata come semplice percorso locale (facendo riferimento alla cartella e al nome dell’immagine da elaborare) oppure trasmessa in versione codificata base64.
/https://www.ilsoftware.it/app/uploads/2025/03/ragionamento-modelli-AI-anthropic.jpg "AI generativa: è possibile parlare di processi cognitivi? Lo studio di Anthropic")
/https://www.ilsoftware.it/app/uploads/2024/09/ragionamento-intelligenza-artificiale-open-source.jpg "AI Overviews sarà in grado di analizzare immagini e testo da singola fonte")
/https://www.ilsoftware.it/app/uploads/2023/06/hacker-malware-1.jpg "Set di dati trapelato rivela progetto della Cina per attuare censura tramite AI")
/https://www.ilsoftware.it/app/uploads/2024/12/2-3.jpg "ChatGPT: posticipato lancio del generatore di immagini per account gratuiti")