/https://www.ilsoftware.it/app/uploads/2024/10/migliori-tool-online-IA.jpg "Migliori tool online basati sull'IA: come sfruttarli per potenziare produttività e creatività")
La sempre più (vorticosa) diffusione di modelli generativi al servizio delle più moderne soluzioni basate sull’intelligenza artificiale, ha portato alla nascita di un numero incalcolabile di servizi, con al centro proprio l’IA. I chatbot come ChatGPT, Gemini, Claude, Perplexity, Mistral, Phind, Cerebras Inference rappresentano solo la punta dell’iceberg di ciò che è possibile realizzare con l’intelligenza artificiale generativa.
I LLM (Large Language Models) sono alla base del funzionamento dei moderni chatbot: alcuni di essi sono proprietari mentre altri sono disponibili come prodotti open source, incoraggiando le attività degli sviluppatori indipendenti e di tante realtà commerciali. Ciò significa che gli LLM a sorgente aperto possono generalmente essere utilizzati (occhio alla licenza!) per sviluppare progetti in proprio, senza affidarsi a “ricette” preparate da altri.
Basandosi su architetture avanzate di deep learning, come i Transformer (ma anche soluzioni ancora più recenti), i LLM possono elaborare grandi quantità di testo e apprendere le complessità e le sfumature del linguaggio umano.
Quali sono i migliori tool online basati sull’IA
Se da un lato i modelli alla base dei chatbot sono diventati sempre più multimodali, ovvero in grado di elaborare non soltanto testi ma anche altre tipologie di contenuti, accanto ai LLM sono emersi strumenti avanzati per l’elaborazione e la creazione di immagini, video, audio e musica. Questi modelli utilizzano tecnologie di intelligenza artificiale per generare contenuti multimediali in modo autonomo o interattivo.
La maggior parte dei modelli per la creazione di immagini si basa su architetture di reti neurali profonde, come le Generative Adversarial Networks (GAN) e i modelli di diffusione. Le GAN consistono in due reti neurali che competono tra loro: un generatore che crea immagini e un discriminatore che cerca di distinguere le immagini generate da quelle reali.
I modelli di diffusione, invece, partono da rumore casuale e iterativamente migliorano l’immagine fino a raggiungere il risultato desiderato. Apposite tecniche di post-processing aiutano, come ultimo passo, a migliorare la qualità dell’immagine.
Nel caso della generazione di video con l’IA, i modelli possono utilizzare tecniche simili a quelle delle immagini, ma integrano anche informazioni temporali per gestire il movimento.
L’esempio di Fooocus e del modello aperto Stable Diffusion
Si pensi ad esempio al progetto Fooocus che permette di generare immagini da un testo senza scambiare un singolo byte in rete. Fooocus necessita preferibilmente di una macchina dotata di una GPU NVIDIA RTX serie 4000 e poggia il suo funzionamento su un modello aperto memorizzato in locale. Si tratta di Stable Diffusion, un modello di deep learning che appartiene alla categoria dei modelli di diffusione e usa un approccio chiamato latent diffusion model (LDM), che consente di operare in uno spazio latente compresso piuttosto che direttamente sull’immagine ad alta risoluzione e di grandi dimensioni.
Lo spazio latente è una rappresentazione semplificata e compressa dei dati originali: le caratteristiche essenziali dell’immagine sono mantenute ma in una forma più compatta e astratta. Operare in questo spazio ridotto rende il processo di generazione e manipolazione delle immagini molto più efficiente dal punto di vista computazionale, perché il modello deve gestire meno informazioni.
L’apertura del codice stimola la collaborazione tra ricercatori e sviluppatori, facilitando miglioramenti e adattamenti del modello a casi d’uso specifici.
Venice AI, intelligenza artificiale senza censure rispettosa della privacy
A differenza di molte piattaforme IA che raccolgono e memorizzano dati, Venice AI assicura che tutte le conversazioni e i contenuti generati rimangano confidenziali. La piattaforma si serve di modelli open source, permettendo agli utenti di verificare la tecnologia sottostante.
Venice AI offre agli utenti un accesso non censurato a informazioni e risposte. Gli utenti possono porre domande su una vasta gamma di argomenti, senza le azioni di filtro tipiche di altri strumenti.

Non memorizzando alcuna informazione personale o i log delle conversazioni lato server, tutte le interazioni sono conservate in locale sul dispositivo di ciascun utente.
Non è necessario creare un account per utilizzare Venice AI, rendendo l’accesso immediato e semplice. Gli utenti possono iniziare a interagire con l’IA direttamente dal browser senza download o installazioni. Per accedere gratuitamente a un più ampio spettro di caratteristiche, tuttavia, la creazione dell’account – dopo una prova iniziale – sembra pressoché indispensabile.
Not Diamond AI: combina l’uso di più LLM
Not Diamond è una piattaforma innovativa che aggrega diversi modelli di intelligenza artificiale, offrendo agli utenti un accesso centralizzato a tecnologie avanzate come GPT-4, Claude, Mistral, Perplexity e Gemini. Sulla base dell’input o prompt fornito dall’utente, Not Diamond sceglie il LLM più adatto e fornisce risposte pertinenti.
Una delle caratteristiche più innovative è la cosiddetta Arena Mode, che consente agli utenti di confrontare i risultati generati da diversi modelli in risposta allo stesso prompt. In questo modo è possibile di volta in volta valutare quale modello fornisce la risposta migliore, migliorando così l’accuratezza delle informazioni ottenute. Un bel vantaggio, ad esempio, per tutti coloro che hanno la necessità di umanizzare i testi AI.
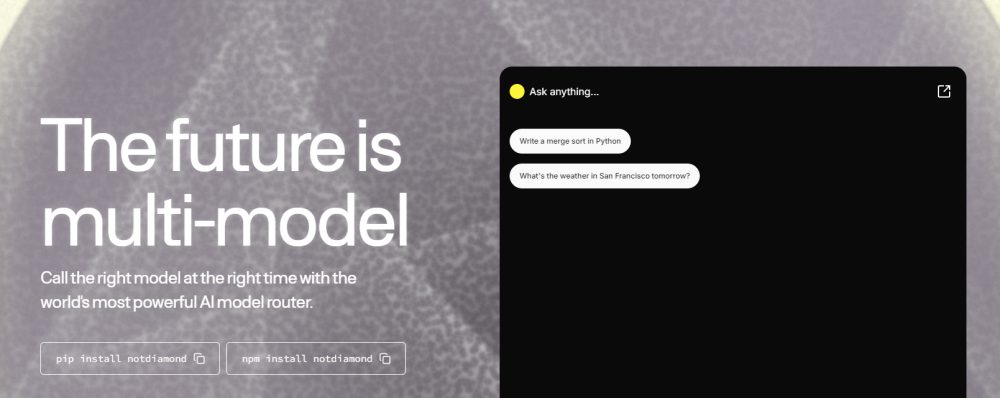
Pop AI permette di “parlare con i documenti” e creare presentazioni
Pop AI è un innovativo strumento di intelligenza artificiale progettato per semplificare l’interazione con documenti e la creazione di contenuti. Alternativa al più conosciuto Google NotebookLM, Pop AI si distingue per la sua capacità di leggere e analizzare file PDF, generare riepiloghi, creare presentazioni e facilitare la comprensione di testi complessi.
Capace di interagire con documenti in vari formati, Pop AI fornisce risposte aggiornate attingendo anche alle informazioni provenienti dal Web.
Una volta caricato un documento, Pop AI genera automaticamente un riepilogo del suo contenuto, facilitando la comprensione delle informazioni principali. Gli utenti possono poi porre domande specifiche, ricevendo risposte immediate e contestualizzate.
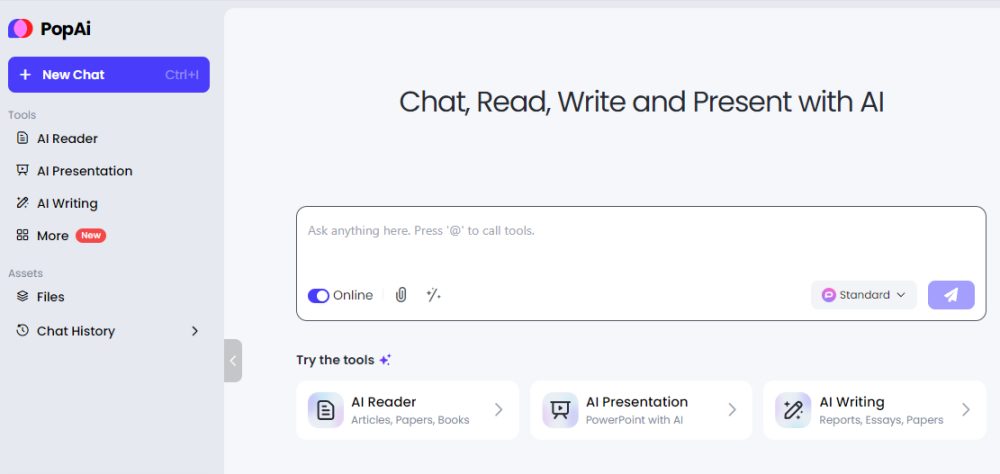
Tra le caratteristiche peculiari di Pop AI, spesso mancanti nei tool concorrenti, vi è la possibilità di generare presentazioni PowerPoint. Basandosi sul contenuto del documento caricato, Pop AI suggerisce una struttura per le diapositive, rendendo il processo di creazione molto più veloce. È comunque sempre possibile personalizzare le scelte proposte e modificare i contenuti generati.
Hedra AI, per creare video di persone e avatar
Hedra AI è una piattaforma online basata sull’intelligenza artificiale focalizzata sulla generazione di contenuti video, progettata per semplificare e accelerare il processo di creazione di contenuti per il marketing, i social media e l’e-learning.
Fondata da ex dipendenti di NVidia, Google e Meta, Hedra utilizza modelli IA per generare video a partire da input testuali. Gli utenti possono inserire descrizioni o sceneggiature, e il sistema crea automaticamente video che rispecchiano le indicazioni fornite.
Con un clic su Create, Hedra può creare avatar digitali personalizzabili: si può ad esempio inviare la foto di una persona e specificare le parole che deve pronunciare. L’IA creerà un video in cui la foto di partenza “si anima” e il soggetto raffigurato pronuncia i testi specificati in fase di composizione. Sebbene tra le voci non ci siano ancora quelle con un accento italiano, abbiamo ottenuto buoni risultati anche nella nostra lingua.
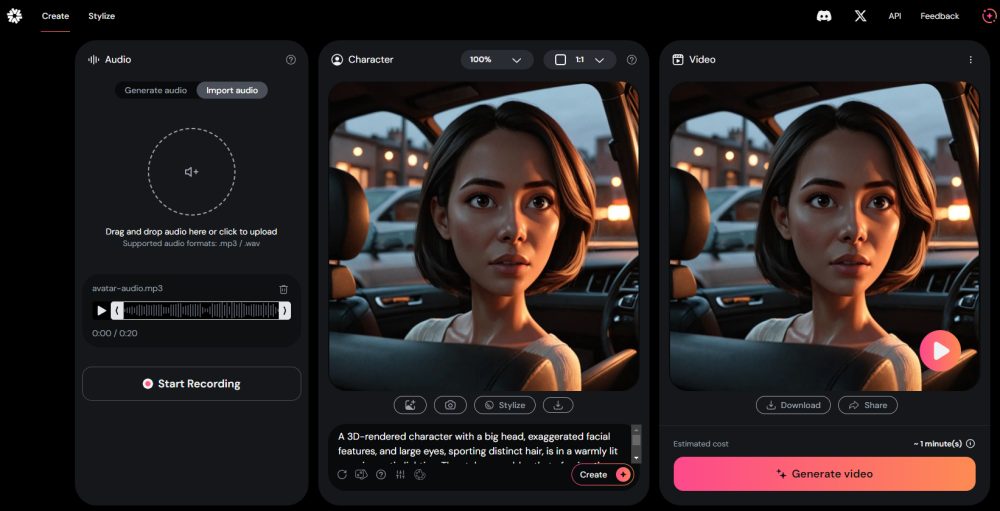
La sezione Stylize di Hedra consente di produrre “gemelli digitali” che amplificano alcune caratteristiche dell’immagine condivisa oppure che applicano degli stili particolarmente accattivanti.
Le aziende possono utilizzare Hedra per creare video promozionali accattivanti senza dover investire in costose produzioni. Gli educatori possono generare contenuti didattici interattivi, migliorando l’esperienza di apprendimento degli studenti. I “creativi” possono produrre rapidamente contenuti destinati alle piattaforme social.
Vidu AI, per generare video accattivanti in pochi secondi
Vidu AI è una piattaforma avanzata di creazione video alimentata dall’intelligenza artificiale, in grado di trasformare testi e immagini in video di alta qualità. Sfrutta un’architettura chiamata Universal Vision Transformer (U-ViT) che combina modelli di diffusione e transformer.
Gli utenti possono inserire descrizioni testuali o caricare immagini per guidare la creazione del video. L’intelligenza artificiale analizza queste informazioni e produce un video che riflette il contenuto fornito.
La piattaforma è in grado di produrre clip video di 16 secondi in risoluzione 1080p, è intuitiva e riduce significativamente i costi e i tempi di produzione video, eliminando la necessità di attrezzature costose o team professionali.

Pika Art, crea video a partire da immagini e modifica filmati preesistenti
Anche Pika Art offre la concreta possibilità di creare video a partire da descrizioni testuali, set di immagini e sequenze filmate preregistrate. “Confezionando” il prompt testuale, gli utenti possono anche specificare parametri come la durata del video e il tipo di movimento della camera.
Oltre alla generazione di video, Pika Art consente di animare immagini caricate. La piattaforma offre anche strumenti per modificare video già esistenti, consentendo agli utenti di applicare effetti speciali o modifiche visive ai filmati già disponibili.
Il piano gratuito è in questo caso piuttosto limitato ma consente di sondare le funzionalità di Pika Art e valutare le sue potenzialità.

Hailuo AI, per creare brevi clip di qualche secondo da usare nei montaggi video
Applicazione cinese, Hailuo AI è uno strumento di produttività alimentato dall’intelligenza artificiale sviluppato da MiniMax capace di generare video sorprendenti.
Di base, Hailuo crea brevi clip da semplici prompt testuali: è quindi ideale per chi ha bisogno di contenuti accattivanti da utilizzare nei montaggi video. L’ideale sarebbe usare Hailuo per creare contenuti di brevissima durata: dopo pochi secondi, infatti, la qualità tende a degradare.
Synthesia AI, supporto per la lingua italiana nella creazione di video accattivanti
Synthesia AI è una piattaforma all’avanguardia che rivoluziona il modo con cui creare i video. Il funzionamento di Synthesia semplice e intuitivo: gli utenti iniziano predispongono il testo o il copione che desiderano trasformare in video, quindi possono scegliere tra una vasta gamma di avatar virtuali, ognuno dei quali può essere personalizzato per adattarsi alle esigenze specifiche del progetto.
Gli utenti possono selezionare la lingua (tra le 140 disponibili) e l’accento desiderati, permettendo così la creazione di contenuti multilingue che possono raggiungere un pubblico globale. Questo è particolarmente utile per le aziende che operano in mercati internazionali e desiderano comunicare efficacemente con i propri clienti.
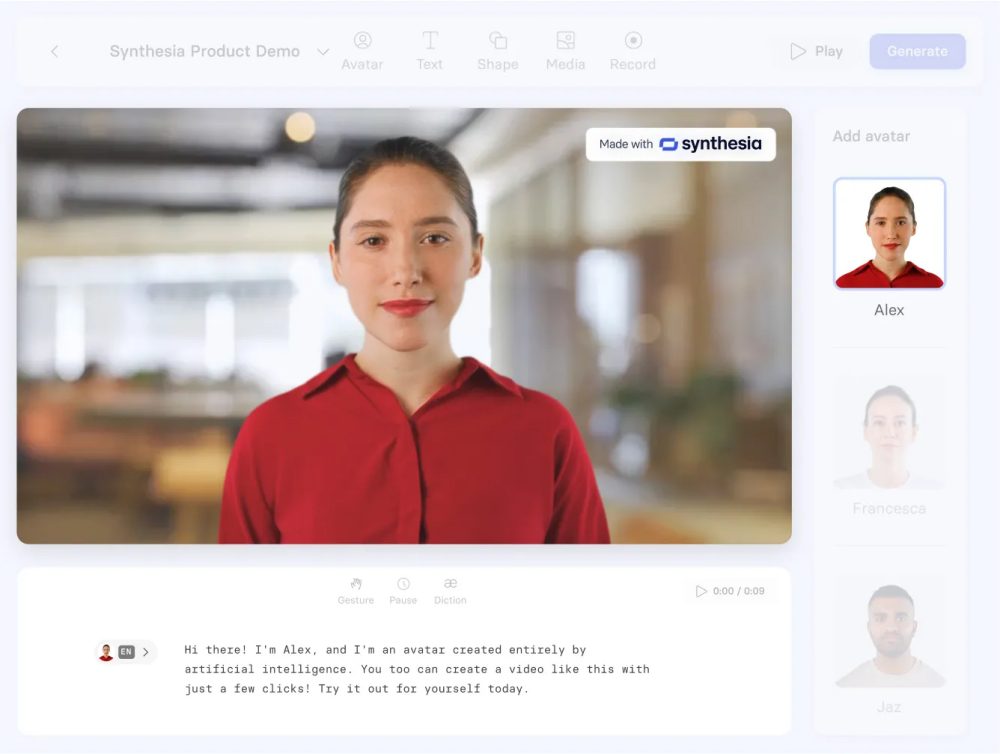
Dopo aver inserito il testo e selezionato l’avatar, gli utenti possono visualizzare in tempo reale come apparirà il video mentre viene generato. La funzione di anteprima consente di apportare modifiche immediate, garantendo che il risultato finale soddisfi le aspettative. Synthesia offre anche strumenti di editing utili per personalizzare ulteriormente i video, cambiare gli sfondi, colori e la musica di sottofondo.
Heygen AI, personalizza anche video già esistenti traducendoli in più lingue
Heygen AI è una piattaforma di intelligenza artificiale generativa che consente la creazione di contenuti multimediali, tra cui testi, immagini e video, in modo semplice e intuitivo. Sviluppata per democratizzare l’accesso alla produzione di contenuti, Heygen sfrutta tecnologie avanzate per generare risultati sorprendenti e realistici, rendendo la creazione di video e altre forme di comunicazione visiva accessibile anche a chi non ha competenze tecniche. La tecnologia alla base di Heygen si basa su reti neurali profonde, addestrate su enormi set di dati.
Una delle funzionalità più interessanti di Heygen è la sua capacità di tradurre video in diverse lingue (lo strumento ne supporta ben 175). Gli utenti possono caricare un video e scegliere la lingua in cui desiderano tradurlo. La piattaforma utilizza tecniche di doppiaggio avanzate, mantenendo il timbro della voce originale e modificando il labiale per rendere il risultato finale il più realistico possibile. Questo è particolarmente utile per creator e aziende che desiderano raggiungere un pubblico più ampio senza dover registrare nuovamente i contenuti.
Heygen non si limita solo alla traduzione: offre anche la possibilità di creare avatar digitali che possono replicare l’aspetto e il timbro vocale delle persone reali. Il processo inizia con la raccolta dei dati facciali da foto o video, poi elaborati per creare una rappresentazione virtuale dell’utente. Una volta creato l’avatar, è possibile farlo parlare semplicemente inserendo un testo, rendendo l’interazione ancora più coinvolgente.
Fotor AI, generazione testo-immagine e immagine-immagine: cosa significa
Fotor è una piattaforma online di editing fotografico online che offre una vasta gamma di strumenti per la modifica e la creazione di immagini. Progettata per essere user-friendly, Fotor consente agli utenti di migliorare le proprie foto con facilità, grazie a funzionalità come filtri, effetti speciali, ritaglio, ridimensionamento e regolazione dei colori.
Una delle caratteristiche distintive di Fotor è il suo editor di foto basato su intelligenza artificiale, che permette di applicare modifiche automatiche per migliorare la qualità delle immagini in modo rapido ed efficace. Gli utenti possono anche creare collage, design grafici e contenuti per i social media utilizzando modelli predefiniti e strumenti drag-and-drop.
Fotor AI mette a disposizione due principali modalità di generazione delle immagini: Testo-immagine e Immagine-immagine. La prima consente agli utenti di inserire descrizioni testuali e di trasformarle in immagini che spaziano dall’arte digitale ai paesaggi realistici. La modalità Immagine-immagine, invece, permette di caricare un’immagine di riferimento, selezionare uno stile artistico e ottenere una versione migliorata o stilizzata dell’originale.
Che si tratti di creare avatar, design di prodotto, sfondi digitali o loghi aziendali, Fotor si distingue per la sua versatilità. Gli utenti possono generare opere in 3D, dipinti ad olio, cartoni animati, immagini cyberpunk e perfino NFT. Gli strumenti avanzati danno modo di personalizzare dettagli come lo stile artistico, il rapporto d’aspetto, la qualità dell’immagine e persino inserire prompt negativi per escludere elementi indesiderati.
Prome AI, generare immagini e video da semplici schizzi e disegni
PromeAI apporta un pesante carico di innovazione nell’arte e nel design, sfruttando la potenza dell’intelligenza artificiale per trasformare schizzi e disegni approssimativi in immagini realistiche e video di alta qualità. Grazie a un’ampia gamma di strumenti, PromeAI offre un’esperienza innovativa per artisti, architetti, designer di interni, sviluppatori di videogiochi e professionisti della moda.
Attraverso la tecnologia proposta da PromeAI, è possibile generare opere d’arte sorprendenti, manipolare immagini per creare varianti e persino trasformarle in video che infondono movimento e vita ai concetti statici.
Cuore pulsante di PromeAI è la tecnologia C-AIGC (Controllable AI-Generated Content), che garantisce una produzione artistica altamente personalizzabile e controllabile. Con un’ampia libreria di stili e modelli, l’intelligenza artificiale di PromeAI si adatta a diversi tipi di progetti, dal disegno architettonico all’animazione.

Skybox AI: per generare paesaggi, scenari e ambienti 3D
Tra i progetti più interessanti apparsi di recente sul Web c’è sicuramente Skybox AI, un’applicazione che permette agli utenti di generare scenari complessi e dettagliati senza la necessità di competenze avanzate in modellazione 3D.
Skybox AI è eccellente per tutti coloro, sviluppatori, artisti e creatori di contenuti, che desiderano creare ambienti virtuali immersivi in modo rapido ed efficace.
Gli ambienti tridimensionali possono essere esplorati, una volta generati, a 360 gradi. L’input di partenza può essere una descrizione testuale (dovrebbe essere il più possibile accurata) oppure un’immagine.
Una volta creato lo skybox, ossia l’ambiente virtuale in 3D, gli utenti possono esportarlo in vari formati, come FBX, per l’uso in software di animazione e sviluppo come Blender o Animotive.
Mymap AI, per creare diagrammi e schemi con l’intelligenza artificiale
MyMap AI rappresenta una rivoluzione nel campo della creazione di diagrammi e presentazioni visive, utilizzando un approccio completamente basato sull’intelligenza artificiale. A differenza di altri strumenti tradizionali, questa piattaforma permette di trasformare semplici conversazioni in mappe mentali, diagrammi di flusso e altri formati visuali con estrema facilità, rendendo accessibile a tutti la creazione di contenuti visivi senza la necessità di competenze tecniche o di design.
Basta descrivere il proprio progetto o inserire appunti, e MyMap si occupa di generare la rappresentazione visiva. Dialogano con i motori di ricerca come Google Search e Bing, MyMap utilizza i risultati più recenti per arricchire il contesto dei diagrammi, assicurando che le informazioni siano aggiornate.
Incollando un URL, l’AI di MyMap estrae automaticamente le informazioni rilevanti, utilizzandole per generare mappe dettagliate e precise. Inoltre, le funzionalità di collaborazione permettono a più utenti di cooperare sul medesimo progetto.
Suno AI, strumento numero uno per creare musica con l’IA
Suno AI è una piattaforma innovativa che utilizza l’intelligenza artificiale per generare musica a partire da descrizioni testuali. In un altro articolo abbiamo visto come funziona Suno per creare musica e leggere qualunque testo.
Dopo una fase di preprocessing del testo, questo viene convertito in una rappresentazione numerica utilizzando tecniche come le Word Embeddings (utilizzo di modelli come Word2Vec o GloVe per rappresentare le parole come vettori) e l’estrazione delle caratteristiche significative dal testo, permettendo a Suno di comprendere il contesto emotivo e tematico.
Una volta che il testo è elaborato, Suno AI genera la musica basandosi sull’input dell’utente, sulla scelta dello stile musicale e sulle eventuali impostazioni personalizzate.
Cursor AI assiste gli sviluppatori nella scrittura del codice di programmazione
In un altro articolo abbiamo visto come programmare con i chatbot basati sull’IA. Tra gli strumenti online più utili per gli sviluppatori non è possibile non menzionare Cursor AI, un editor di codice avanzato che migliora la produttività e l’efficienza degli sviluppatori attraverso l’integrazione dell’intelligenza artificiale. Sfruttando i migliori LLM oggi disponibili, Cursor offre una serie di funzionalità che semplificano la scrittura, la modifica e il debug del codice di qualunque linguaggio di programmazione.
Cursor può interagire con i principali IDE e con strumenti apprezzati come Visual Studio Code; può però integrarsi con la finestra del terminale e fornire suggerimenti, correzioni di bug e codice funzionante in qualunque ambiente.
Il sistema utilizza un sistema di completamento automatico che non solo predice il codice da scrivere, ma tiene anche conto delle modifiche recenti apportate dall’utente. L’editor resta sempre attivo e suggerisce modifiche pertinenti su più righe, risparmiando tempo prezioso durante lo sviluppo.
Una delle caratteristiche distintive di Cursor è la sua funzione di chat. Gli utenti possono porre domande direttamente all’IA riguardo al loro codice, come ad esempio “C’è un bug qui?”. L’IA di Cursor analizza il contesto del codice corrente e fornisce risposte utili e contestualizzate.
Credit immagine in apertura: iStock.com – Supatman
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")