/https://www.ilsoftware.it/app/uploads/2023/05/img_20032.jpg "Machine learning, deep learning e reti neurali: come avvicinarsi a questo mondo")
Come può un’intelligenza artificiale o meglio la rete neurale sulla quale essa è basata riconoscere quanto è ritratto in una foto? Com’è possibile, per una macchina, “comprendere” il mondo circostante, capire cosa sta accadendo, rilevare situazioni di pericolo, reagire di conseguenza e, in generale, porre in essere determinate attività sulla base di specifici eventi?
Le nuove sfide che sono state poste in molteplici campi (non si pensi soltanto alla “guida autonoma”) prevedono lo sviluppo di interfacce innovative in tantissimi settori, con implicazioni impensabili fino ad appena qualche anno fa.
Provate un semplice esperimento: visitate la pagina di Google Teachable Machine e autorizzate l’applicazione web a usare videocamera e microfono.
Cliccate quindi su Let’s Go e scegliete tre gesti da fare con le mani o con il viso: mentre fate un gesto cliccate su Train Green. Provate ad esempio a salutare con la mano quindi fate clic su Train Green: più immagini acquisirete e meglio l’algoritmo riuscirà a “comprendere” il gesto.
Cambiando gesto, si potrà effettuare l’operazione di addestramento per gli altri due pulsanti.
Una volta memorizzati i dati, Google Teachable Machine riuscirà a interpretare i vari gesti e a riconoscerli non appena verranno riutilizzati in seguito. A seconda del gesto, a patto di aver correttamente addestrato l’algoritmo, Google Teachable Machine risponderà con le immagini, i suoni o le registrazioni corrispondenti ai tasti verde, viola e arancione.
Teachable Machine mostra molto bene come dati di input difficilmente interscambiabili e un ricco set di informazioni iniziali (in questo caso una trentina di immagini per pulsante) permettano di ottenere risultati migliori. Un’illuminazione dell’ambiente diversa rispetto a quella in cui si è addestrato il modello potrebbe causare problemi: ecco perché sarebbe importante acquisire le foto in varie condizioni (le immagini non vengono mai trasferite a Google e il sistema di machine learning funziona completamente in locale).
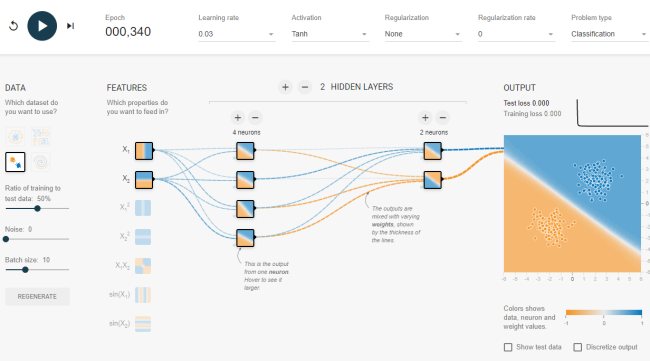
Uno strumento come il Neural Network Playground permette di approfondire i rudimenti legati all’impiego di una rete neurale artificiale con la possibilità di selezionare i singoli “neuroni”, distribuirli per singoli “strati”, addestrare il modello e ottenere un responso finale.
Una rete neurale può essere pensata come una funzione che apprende l’output atteso a fronte di un certo set di dati forniti in ingresso (input) durante la fase di addestramento.
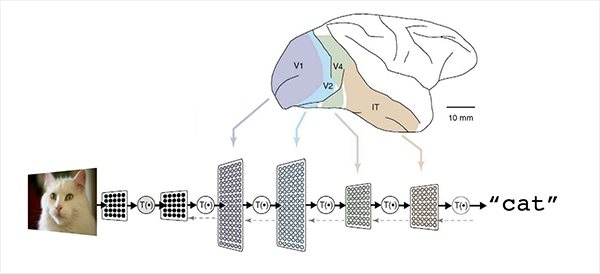
Da “Large-Scale Deep Learning for Intelligent Computer Systems”, Jeff Dean, WSDM 2016.
Per costruire una rete neurale che riconosce le immagini raffiguranti i gatti, si addestra la rete con un ampio ventaglio di immagini che raffigurano questi felini. La rete neurale così costruita sarà una funzione che prende in input un’immagine e produce l’etichetta “gatto” quando la foto contenesse effettivamente un gatto.
Ma è per esempio possibile addestrare la rete neurale (costruendo un “modello”) dandogli in pasto i log di un utente estratti da un server di gioco con i risultati delle varie parti ed evidenziare i comportamenti e le strategie che portano, con maggiore probabilità, al successo.
I metodi di deep learning sono tecniche di rappresentazione-apprendimento a più livelli di rappresentazione ottenuti combinando moduli semplici ma non lineari. Questi ultimi vengono utilizzati per trasformare la rappresentazione a un livello (a partire dall’input grezzo) in una rappresentazione resa a un livello superiore, leggermente più astratto.
Neural Network Playground può sembrare complicato a prima vista, qualcosa di riservato solo agli esperti matematici. In realtà, uno strumento come quello realizzato dai tecnici di Google aiuta a capire come funzionano i “classificatori” ossia gli elementi che riescono a comprendere le immagini e, in ultima analisi, la realtà partendo dalle caratteristiche degli insiemi di dati presi in esame.
Si faccia clic su una delle prime quattro icone sotto la voce “Data“, a sinistra (tranne quella a spirale ovvero l’ultima) quindi si prema il tasto “Play“: Neural Network Playground effettuerà una classificazione dei pallini mostrati nelle immagini suddividendoli correttamente per colore.
Come si vede, c’è una linea di demarcazione netta tra l’area in cui sono presenti i pallini blu e quella in cui sono contenuti i pallini arancioni.
Si prenda però come esempio solamente il terzo esempio: per tracciare una linea di demarcazione tra i pallini blu e arancioni, all’intelligenza artificiale basterà usare un solo neurone. Come si vede nell’immagine, Neural Network Playground necessita di un solo neurone per arrivare all’obiettivo prefisso.
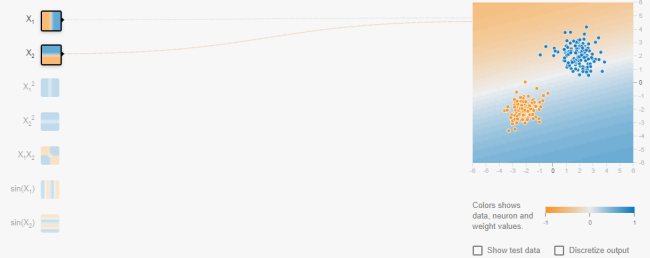
Con due ingressi, un neurone può classificare i pallini nello spazio bidimensionale in due settori separati da una linea retta. Se si disponesse di tre ingressi, un neurone può classificare i punti dati in uno spazio tridimensionale e così via arrivando a suddividere lo spazio n-dimensionale come iperpiano.
Cliccando sulla prima icona nella colonna Data si noterà come i pallini non possano essere classificati con un singolo neurone dal momento che, evidentemente, i due gruppi non possono essere suddivisi con una semplice linea retta.
Analizzando l’esempio in figura si ha insomma a che fare con un problema di classificazione non lineare.
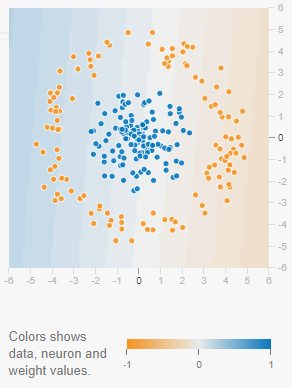
Cliccando qui ci si accorge di come l’approccio alla soluzione del problema consista nell’utilizzo di un livello intermedio nascosto posizionato tra i valori di input e l’output.
Per risolvere il problema di classificazione si usano 3 neuroni ciascuno dei quali deputato ad assolvere una specifica operazione:
1) Il primo neurone controlla se un punto dati si trova a sinistra o a destra.
2) Il secondo neurone controlla se si trova in alto a destra.
3) Il terzo controlla se si trova in basso a destra.
Il neurone posto al livello di output si occuperà di classificare i dati sulla base dei controlli effettuati dai 3 neuroni posti al livello precedente.
Si otterrà una composizione di forma diversa che riflette la classificazione effettuata; ovviamente, aggiungendo altri neuroni si verificherà come il neurone di uscita sia capace di catturare ed evidenziare forme poligonali molto più sofisticate e precise dal set di dati di partenza.
E come si risolve il problema dell’ultimo esempio raffigurante una spirale?
L’approccio sin qui presentato non permette di classificare correttamente i pallini colorati.
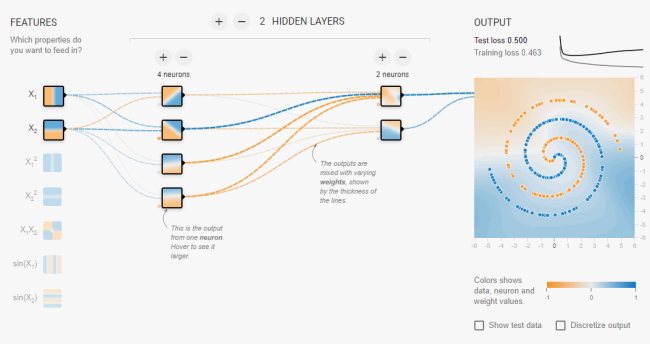
Una soluzione può essere quella di aumentare, oltre che i neuroni, anche gli ingressi. Un approccio (feature engineering) che però potrebbe non portare ai risultati sperati con esempi meno banali.
Usando il deep learning non si manipolano gli ingressi ma si aggiungono più layer di neuroni.
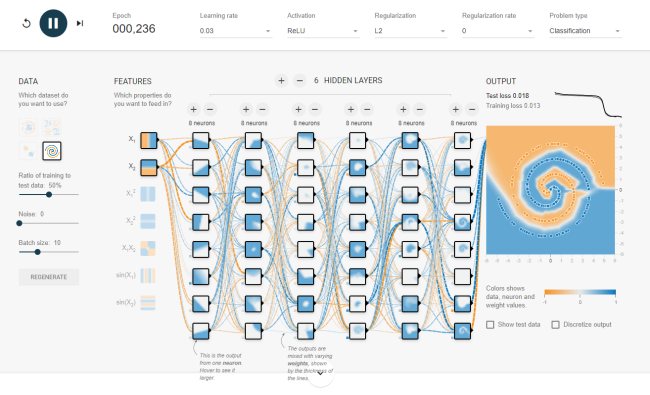
Normalmente non si può guardare a una rete neurale come nell’applicazione Neural Network Playground: buona parte delle reti neurali artificiali sono “black box” molto più complesse. Il fatto che alcune decisioni assunte non possano essere comprese con la stessa facilità vista in Neural Network Playground rappresenta un problema per molte applicazioni. Si pensi alle diagnosi mediche: qui si vuole sapere perché l’intelligenza artificiale ha preso una certa decisione.
I ricercatori sono continuamente alla ricerca di modi per rendere trasparenti i percorsi decisionali dell’intelligenza artificiale. Un metodo si chiama Layer-Wise Relevance Propagation: esso passa in rassegna a ritroso i processi decisionali nelle reti neurali ed estrapola le informazioni più rilevanti.
Ciò rende comprensibile quale input ha una certa influenza sul risultato e l’influenza di ogni ingresso può essere visualizzata, ad esempio, utilizzando le cosiddette heatmap (mappe termiche). Questo metodo può essere messo alla prova con foto, testi e scritti a mano usando l’applicazione web dell’istituto Fraunhofer HHI (maggiori informazioni a questo indirizzo).
L’ebook Neural Networks and Deep Learning è completamente gratuito e prende per mano il lettore illustrando i concetti sia dal punto di vista matematico-teorico che spiccatamente pratico.
Molto interessante è il corso online (gratuito) di Andrew Ng, docente presso l’Università di Stanford e pioniere nel campo dell’intelligenza artificiale.
/https://www.ilsoftware.it/app/uploads/2025/04/codex-cli-openai-cos-e-come-funziona.jpg "Codex CLI: cos'è l'agente AI di OpenAI che scrive e interpreta codice dal terminale")
/https://www.ilsoftware.it/app/uploads/2025/04/compleanno-git-20-anni-linus-torvalds.jpg "Git compie 20 anni e Linus Torvalds parla della sua creatura")
/https://www.ilsoftware.it/app/uploads/2025/04/sorgente-altair-basic.jpg "Microsoft rilascia il suo codice sorgente! Per festeggiare 50 anni di attività")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")