/https://www.ilsoftware.it/app/uploads/2025/02/intelligenza-artificiale-spiegata-semplice.jpg "Intelligenza Artificiale (IA) spiegata facile: cos'è e come funziona")
Quando si parla di intelligenza artificiale, buona parte dell’opinione pubblica si dimostra diffidente o mette in evidenza una scarsa conoscenza dell’argomento. L’idea di molti è che dietro l’intelligenza artificiale ci sia qualcosa di magico, non se ne comprende la reale utilità, si pensa che sia qualcosa di astratto, lontano dalle necessità del singolo individuo.
In realtà l’intelligenza artificiale è protagonista di una delle più grandi rivoluzioni da qualche decennio a questa parte, non solo a livello tecnologico ma anche sociologico, economico, culturale, lavorativo.
L’era dell’intelligenza artificiale, che tutti noi stiamo vivendo, è appena iniziata.
Per dare un senso al carico innovativo che introduce l’intelligenza artificiale, potremmo paragonare il suo avvento a quello dei personal computer (anni ’70), alla presentazione del World Wide Web (agosto 1991), al primo smartphone moderno (Apple iPhone, 2007).
Queste innovazioni hanno aperto a tutti (“democratizzato“) l’accesso a nuove possibilità, ma l’intelligenza artificiale ha la capacità di integrarsi in modi molto più profondi, influenzando non solo le tecnologie che utilizziamo quotidianamente, ma anche come pensiamo, lavoriamo e interagiamo. Mentre il personal computer ha reso il calcolo accessibile, il Web e gli smartphone hanno rivoluzionato la comunicazione e l’accesso alle informazioni, l’intelligenza artificiale può influenzare praticamente ogni settore, dalla medicina all’arte, dall’industria alla scienza.
L’intelligenza artificiale ha insomma il potenziale di trasformare la società in modo profondo, cambiando non solo ciò che facciamo, ma anche come pensiamo e ci relazioniamo al mondo. E oggi siamo soltanto all’inizio. Ci troviamo dinanzi a un piccolo assaggio di ciò che sarà possibile fare nel futuro prossimo.
Cos’è l’intelligenza artificiale (IA)?
L’intelligenza artificiale (IA) si riferisce alla capacità delle macchine di imitare l’intelligenza umana, come il pensiero, l’apprendimento e la risoluzione di problemi. In altre parole, è un campo della tecnologia che sviluppa sistemi in grado di “pensare” e “agire” autonomamente, in un modo che ricorda il comportamento di un essere umano.
Ad esempio, un programma di IA può imparare dai dati che gli vengono forniti, prendere decisioni e rispondere a situazioni senza essere esplicitamente programmato per gestire ogni singola azione.
Liberiamoci dell’idea di poter accostare quanto fa una macchina (elaborazioni informatiche) ai processi propri del cervello umano.
L’intelligenza artificiale e quindi le macchine (computer, dispositivi elettronici,…) possono solamente cercare di approssimare il funzionamento del cervello: non sono in grado di riprodurlo.
Intelligenza artificiale generativa
L’idea dell’intelligenza artificiale in sé non è una novità: esiste dagli anni ’50 del secolo scorso. Lo è invece l’intelligenza artificiale generativa, che invece è la vera rivoluzione.
Spesso si parla genericamente di intelligenza artificiale quando è quella generativa che sta cambiando davvero il mondo. Permette infatti di creare contenuti ma anche ispirarsi, cercare informazioni, relazionarsi con i contenuti. L’intelligenza artificiale può essere pensata come il “copilota” di un aereo, pronto a intervenire per aiutare nel proprio lavoro, per rendere automatiche delle operazioni (e farle al posto nostro), per innovare ed essere sempre più creativi. Ed è un errore pensare che l’IA possa sostituire le persone: vedremo questo concetto più avanti.
L’intelligenza artificiale generativa permette, come suggerisce il nome, di generare dei contenuti partendo da una richiesta (prompt) fornita in ingresso (input) dall’utente. Elabora il prompt e fornisce una risposta (output) costruendola in maniera tale che sia il più possibile in linea con la richiesta.
Tutti abbiamo sentito parlare di strumenti come ChatGPT. Ma ce ne sono molti altri simili come Gemini, Claude, Perplexity, Copilot, Mistral, Phind e così via. Questi sono chatbot ossia strumenti informatici che rappresentano l’espressione dell’intelligenza artificiale generativa più accessibile per tutti.
Il chatbot si chiama così perché si può parlare con lui (“chattare“). Però non si sta parlando con una persona in carne ed ossa, anche se molte volte la distinzione sembri impercettibile, ma con un “bot” (il termine bot deriva appunto da robot), un sistema informatico.
I chatbot basano a loro volta il loro funzionamento sui cosiddetti modelli generativi: sono strumenti informatici capaci di elaborare e produrre testi, immagini, video, audio, musica.
ChatGPT e i chatbot simili sono conosciuti per la produzione di testi ma l’idea è quella di trasformarli in strumenti sempre più potenti e versatili, in grado di gestire anche contenuti visivi e sonori (abilità multimodali).
Cosa sono e come funzionano i modelli generativi
I modelli generativi sono una sottocategoria dell’intelligenza artificiale e rappresentano la principale novità degli ultimi anni.
Per semplicità limitiamoci per adesso all’elaborazione dei testi. Come fa un chatbot come ChatGPT a “comprendere” la richiesta dell’utente e fornire una risposta su qualunque tipo di quesito? Come fa ad essere preparato per rispondere alle domande di un ragazzo di 10 anni e al contempo soddisfare le esigenze degli studi superiori, quelle accademiche o da dottorato di ricerca?
Quella che sembra una magia ha inizio con una prima fase chiamata processo di addestramento. In questa fase si passano al modello generativo miliardi di documenti e il contenuto di interi libri.
Pensiamo a tutto il contenuto della Biblioteca Nazionale Centrale di Roma, di Firenze, alla Biblioteca Ambrosiana di Milano, alla British Library, alla Biblioteca del Congresso degli Stati Uniti. Pensiamo, ancora, a tutte le pagine pubblicate sul Web e pubblicamente accessibili.
Stabilire le relazioni tra le parole
Tutto lo scibile umano è “dato in pasto” al modello generativo che, attraverso apposite tecnologie, legge i contenuti e riesce a stabilire le relazioni tra le parole, le frasi e, in ultima analisi, derivare anche i concetti.
Va sottolineato che per un modello generativo (nel caso di testi si parla di modelli di linguaggio di grandi dimensioni ossia LLM, Large Language Models), non c’è alcuna comprensione del significato (semantica) delle parole.
Questo è un aspetto essenziale. I legami tra parole, frasi e concetti, di cui parlavamo prima, sono costruiti dal LLM utilizzando esclusivamente concetti matematico-statistici.
In altre parole, ogni LLM cerca di stabilire la migliore risposta da fornire al prompt dell’utente sulla base delle informazioni contenute nel prompt stesso. Il LLM cerca di stabilire quali parole hanno maggiore probabilità di seguire l’input fornito dall’utente sotto forma di prompt.
Il principale meccanismo alla base di questo tipo di elaborazione è chiamato self-attention e poggia sul concetto di Transformer. (“Attention Is All You Need“, Vaswani et al., 2017).
Il calcolo delle probabilità per la generazione dei testi
Semplificando al massimo, immaginiamo di insegnare a un bambino a completare frasi leggendo tanti libri. Se legge spesso la frase:
Il sole splende nel cielo
quando chiediamo di completare “Il sole splende…”, egli saprà che “nel cielo” è una buona continuazione.
I LLM “imparano” leggendo milioni di testi e memorizzando le parole più probabili in ogni contesto. Le parole e i legami tra le stesse sono registrati in forma numerica.
Il modello non sceglie parole a caso, ma usa le probabilità per capire quale parola è più adatta. Ad esempio, se gli diamo la frase:
Vorrei un caffè con…
Il nostro LLM “basilare” potrebbe calcolarsi le seguenti probabilità:
“latte” → 60% di probabilità
“zucchero” → 30% di probabilità
“sale” → 1% di probabilità
“un drago” → 0,01% di probabilità
Poiché “latte” è la parola con la probabilità più alta, sarà la scelta più probabile per continuare la frase.
Se addestriamo un modello con una selezione di libri che parlano della vita e delle abitudini dei gatti, il LLM potrebbe “imparare” che, tra le tante, una delle frasi più comuni è:
Il gatto dorme sul tetto
Se in un momento successivo, chiedessimo al LLM di completare una frase che inizia con “Il gatto dorme…”, il modello potrebbe completarla con “sul tetto” ma anche scrivere “nella cesta” oppure “davanti al caminetto” o, ancora, “sul letto“.
Certamente non continuerà la frase con “sull’acqua” oppure “nel forno” o, ancora, “su Marte” perché le probabilità che queste parole possano seguire nella frase sono ridottissime.
Il tutto, comunque, a seconda del contenuto dei testi che il modello o LLM ha letto e che abbiamo fornito nella fase di addestramento.
La finestra di contesto
I moderni LLM non prendono in esame soltanto l’ultima o le ultime parole contenute nel prompt, ovvero nella richiesta fornita in ingresso. Sono invece in grado di considerare tutte le parole fornite in input. Il LLM può quindi stabilire una serie di complesse relazioni matematico-probabilistiche tra le parole nel prompt dell’utente e la sua “base di conoscenza” costruita durante la fase di addestramento.
La finestra di contesto è il numero massimo di parole che un modello di linguaggio può considerare mentre genera una risposta. In pratica, è come la “memoria a breve termine” del modello: più è grande, più informazioni può ricordare mentre elabora la risposta.
Oggi i LLM hanno dimensioni della finestra di contesto pari a decine di migliaia di parole. Questo significa che, pur non comprendendo la semantica ovvero il significato delle parole, delle frasi, di paragrafi e di interi testi, hanno il potenziale di derivarlo in modo matematico-probabilistico. Possono così costruire nuovi testi attingendo alle informazioni acquisite in fase di addestramento ed elaborare contenuti nuovi, mai visti prima.
Agendo su alcuni parametri (ad esempio la cosiddetta “temperatura“), è addirittura possibile regolare la “creatività” del modello.
A una temperatura più alta, il modello è più propenso a produrre risultati creativi e sorprendenti, poiché distribuisce la probabilità in modo più uniforme tra le diverse parole nel suo vocabolario. Al contrario, a una temperatura più bassa, il modello genera risultati più conservativi, prudenti e coerenti, poiché si affida alle parole più probabili in assoluto.
Tokenizzazione e generazione del testo
Quando un utente fornisce il suo prompt, il modello segue un processo strutturato per arrivare alla generazione della risposta.
- Tokenizzazione: il testo è suddiviso in unità chiamate token (parole, parti di parole o caratteri), a loro volta convertite in formato numerico.
- Elaborazione: i token sono fatti passare attraverso la rete del Transformer, citata in precedenza, che utilizza i pesi appresi per calcolare la probabilità dei token successivi in base al contesto fornito.
- Sampling e decodifica: il modello seleziona i token più probabili per generare la risposta, utilizzando varie possibili strategie.
Nel contesto di una rete basata su Transformer, ogni connessione ha un valore numerico chiamato peso. Questi pesi determinano l’intensità e la direzione dell’influenza che una determinata informazione ha su un’altra. Durante l’addestramento, il modello cerca di ottimizzare questi pesi in modo che la rete possa fare previsioni accurate.
Quando si dice che un modello “utilizza i pesi appresi per calcolare le probabilità dei token successivi“, si intende che il modello sta facendo affidamento su questi pesi ottimizzati per effettuare previsioni e generare risposte coerenti con il prompt. Questi pesi sono ciò che consente al modello di riconoscere schemi nel testo, mantenere la coerenza nel discorso e produrre “risposte plausibili” basate sul materiale raccolto nella precedente fase di addestramento.
L’IA impara dai dati
Come abbiamo visto poco fa, l’intelligenza artificiale generativa “impara” dai dati, dalla fase di addestramento. Più informazioni riceve, più diventa “intelligente”.
Conta però tantissimo la qualità delle informazioni che si forniscono per addestrare il LLM. Se ci sono informazioni non verificate o peggio “fasulle”, ovviamente il LLM restituirà output mediocri.
Il concetto di ragionamento nelle IA
Fino all’incirca all’estate 2024, i LLM avevano grosse difficoltà nel gestire problemi di logica e di matematica. Andavano in crisi anche con semplici calcoli aritmetici da scuola primaria.
Questo accade perché, come abbiamo spiegato in precedenza, i LLM lavorano utilizzando un approccio probabilistico. Le prime versioni dei chatbot furono definite “pappagalli stocastici“. Non è un’”offesa”: la generazione di testo si basa, come abbiamo visto, sul calcolo delle probabilità, per cercare di stabilire quali parole possono seguire altre in una sequenza.
Ogni parola è scelta in base alla distribuzione statistica delle parole nei dati di addestramento, senza alcuna reale consapevolezza.
Il termine “stocastico” si riferisce a un fenomeno o a un processo che presenta casualità o probabilità. Il lancio di un dado è un processo stocastico.
Le parole “comprendere” e “ragionare” nel caso dell’intelligenza artificiale generativa vanno quindi preferibilmente messe tra virgolette perché l’IA è lontana dai processi propri del cervello umano.
Ciononostante, in meno di un anno, sono stati presentati una serie di modelli generativi con abilità di reasoning/thinking. Ma non abbiamo detto che un modello generativo non può, a stretto rigore, “pensare” come un essere umano proprio perché lavora calcolando le probabilità?
Vero. Tuttavia, con una serie di studi approfonditi, si è introdotto il concetto di chain-of-thought (“catena di pensiero”, in italiano). Ciò che fa un modello dotato di abilità di reasoning è quello di scomporre in più passaggi il problema fornito sotto forma di prompt, usando quello stesso schema a cui siamo abituati quando studiamo e svolgiamo i nostri compiti. Il documento di riferimento in questo campo è “Large Language Models are Zero-Shot Reasoners“, Kojima et al., gennaio 2023.
La scomposizione dei problemi complessi
Scomponendo un problema complesso in passaggi più semplici, il modello può così migliorare le prestazioni (ossia la qualità degli output forniti) su compiti di ragionamento complesso, come aritmetica, matematica e logica.
Prendete questo quesito:
Sono andato a una festa. Sono arrivato prima di Giovanni. Davide è arrivato prima di Giuseppe. Giuseppe è arrivato prima di me. Giovanni è arrivato dopo Davide. Chi è arrivato per primo?
Fino all’estate 2024, ChatGPT e molti degli altri LLM non riuscivano a fornire la risposta corretta. Questo perché quesiti del genere, che presuppongono abilità logiche, non erano e non sono presenti nei dati di addestramento.
Anche un semplice quesito aritmetico portava a risultati assolutamente scorretti:
Fai questa moltiplicazione e comunicami il risultato:
16 * 38 * 42 * 22 * 20 * 19
Il modello cercava sempre relazioni probabilistiche tra le parole. Ma quando si ha a che fare con problemi logici e matematici non è evidentemente possibile usare questo approccio.
Utilizzo della catena di pensiero
Aprite oggi ChatGPT, cliccate sul pulsante “Avvia il ragionamento” (che attiva le abilità di reasoning) e provate a sottoporre problemi complessi: il modello vi fornirà tutti i passaggi intermedi elaborati prima di giungere alla soluzione finale.
Provate, a far ragionare il modello generativo con quesiti di logica tratti da un testo che raccoglie tanti quiz stimolanti. Vedrete che giungerà alla soluzione corretta dopo un tempo variabile (potrebbero volerci anche più di 30 secondi, in alcuni casi anche minuti…).
La catena di pensiero nei modelli AI funziona addestrando i LLM a generare catene di pensiero analoghe a quelle umane. Ad esempio, se si chiede ai nuovi modelli di tipo reasoning/thinking di risolvere un problema matematico del tipo “Un oggetto costa inizialmente 100 €. Nel primo mese il prezzo aumenta del 20% e nel mese successivo viene diminuito del 20%. Qual è il prezzo finale dell’oggetto?”, fino a poco tempo fa il sistema sarebbe andato in crisi.
Oggi, invece, si ottiene la seguente catena logica che porta alla soluzione corretta:
Calcolo dell’aumento del 20%:
Partiamo dal prezzo iniziale di 100 €.Un aumento del 20% significa aggiungere il 20% di 100 €, cioè:
100×0,20=20€Quindi, il nuovo prezzo dopo l’aumento è:
100+20=120€Calcolo della diminuzione del 20% sul nuovo prezzo:
Ora, a partire dai 120 €, applichiamo una diminuzione del 20%.
Il 20% di 120 € è:
120×0,20=24€Riducendo 120 € di 24 €, il prezzo diventa:
120−24=96 €.Conclusione:
Il prezzo finale dell’oggetto, dopo l’aumento e la successiva diminuzione, è 96 €.
Ovviamente, quello presentato è volutamente un esempio banale ma lo stesso schema è utilizzato per gestire qualunque problema, anche i più complessi. Anche quelli universitari e scientifici.
Il ruolo del tempo nel “ragionamento” dei LLM
Lasciando il tempo al modello di provare a confutare le sue stesse risposte, è possibile ottenere output ancora più precisi e circostanziati, frutto di un’elaborazione che approssima da vicino la scomposizione dei problemi svolta da un essere umano.
Provate ad esempio questo rompicapo:
Val, Lynn e Chris sono imparentati tra loro. 1. Tra i tre ci sono il padre di Val, l’unica figlia di Lynn e il fratello di Chris. 2. Il fratello di Chris non è né il padre di Val né la figlia di Lynn. Chi è di sesso diverso dagli altri due?
Abilitando il pulsante Attiva il ragionamento in ChatGPT, ad esempio, il modello generativo giungerà alla risposta corretta dopo una serie di passaggi che impiegano, tipicamente, poco meno di 30 secondi.
Come funzionano i modelli generativi per le immagini, i video e la musica
Esistono molteplici modelli in grado di generare immagini, video e musica. Si pensi a DALL-E, Stable Diffusion, Midjourney, Leonardo.ai, DreamStudio.ai e tanti altri, ma anche gli stessi ChatGPT, Copilot e Mistral che a loro volta integrano la possibilità di creare immagini. Per i video c’è Sora, dagli stessi sviluppatori di ChatGPT (OpenAI); per la generazione di musica Suno e Udio.
Per poter generare immagini e musica (i video sono insiemi di immagini – frame – in rapida successione…) il modello generativo è anche in questo caso addestrato utilizzando miliardi di immagini. Si pensi a un’ipotetica IA progettata per riconoscere gli animali: vede migliaia di immagini di cani e gatti finché riesce a distinguerli.
Come funziona un modello che produce immagini e video
Un modello che genera immagini funziona come un pittore che parte da uno schizzo confuso e lo raffina progressivamente.
Quando chiediamo “Disegna un gatto spaziale con un casco trasparente“, il modello inizia con un’immagine fatta di rumore casuale (come un foglio pieno di scarabocchi).
Poi, con ogni passaggio, rimuove il “rumore” e affina i dettagli per far apparire il gatto spaziale. Questo processo si chiama modello di diffusione, perché lavora al contrario del rumore: da una macchia indistinta si passa a un’immagine chiara, in linea con il prompt ovvero la richiesta dell’utente.
Se invece si vuole generare un video, il modello deve fare lo stesso lavoro per ogni fotogramma (frame), ma anche assicurarsi che le immagini siano fluide e coerenti tra loro, proprio come un animatore che disegna una scena in movimento.
Creazione di musica con l’AI
Per l’audio, il modello lavora come un musicista che compone una melodia nota dopo nota o un doppiatore che imita una voce con lo stesso tono ed espressione:
- Se gli chiedi di creare una canzone in stile jazz, il modello analizza esempi esistenti e prova a prevedere quali suoni o strumenti dovrebbero venire dopo.
- Se invece vuoi una voce artificiale, il modello scompone il parlato in piccoli suoni (come le sillabe) e li ricompone in una frase fluida.
Il modello non capisce nel senso umano del termine
Ancora una volta, anche nel caso dei contenuti multimediali (immagini, video, musica…) il modello non “capisce” nel senso umano del termine, ma ha imparato a riconoscere cosa assomiglia a un gatto spaziale con un casco trasparente grazie alla fase di addestramento svolta su un numero enorme di immagini etichettate (“questo è un gatto“, “questo è un cane“, “questa è una bottiglia“, “questo è un pallone” e così via…).
Quando si chiede la generazione di “un gatto spaziale con un casco trasparente“, il modello non pesca un’immagine esistente, ma cerca nel suo spazio latente, che è un modo matematico per rappresentare concetti visivi.
Lo spazio latente è come un gigantesco archivio di idee e somiglianze: qui, le informazioni su come appare un gatto sono memorizzate in un formato numerico, esattamente quello che accade per i testi. Il modello mescola le informazioni su come appare un gatto con quelle di un casco spaziale trasparente, per costruire qualcosa di coerente con il prompt:
- A partire dall’immagine completamente casuale, passo dopo passo, il modello rimuove il rumore e aggiunge dettagli coerenti con la descrizione, usando ciò che ha imparato durante l’addestramento.
- Ad ogni passaggio il modello valuta se l’immagine assomiglia di più o di meno a un gatto spaziale rispetto alla descrizione data.
- Se in un passaggio il modello ha creato qualcosa che non sembra un gatto, il sistema corregge il tiro e si avvicina a un risultato più plausibile.
Abbiamo detto che il modello non “comprende” direttamente cos’è un gatto o un casco spaziale. A partire dalla fase di addestramento, però, può costruirsi delle similitudini.
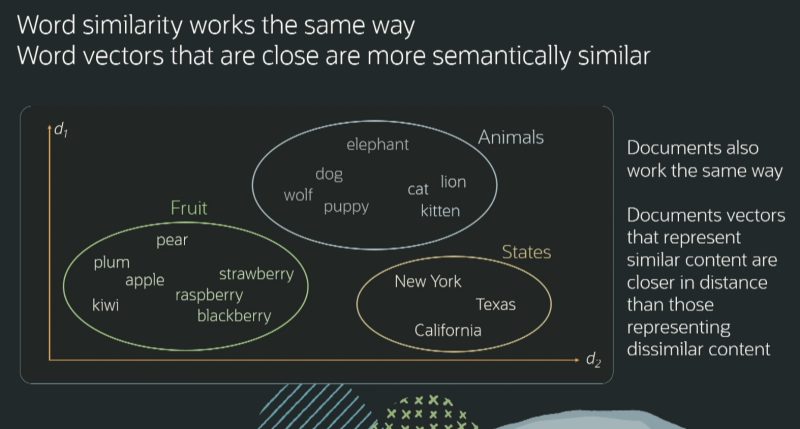
Nell’immagine (fonte: Oracle) si vedono, ad esempio, nomi di frutti, animali e stati, separati tra loro in modo chiaro e netto. All’interno dei vari insiemi, gatto e leone (entrambi felini) sono più vicini rispetto a cane e lupo (a loro volta affini). Allo stesso modo fragole, lampone e mora sono più simili rispetto, per esempio, a kiwi, mela, pera e così via.
IA generativa come strumento per crescere
La tecnologia è solo tecnologia. Così, uno strumento tecnologico qual è l’intelligenza artificiale generativa è un mezzo attraverso il quale possiamo innovare e crescere tutti insieme.
Come abbiamo visto in precedenza, bisogna fare sempre le domande giuste per avere le risposte giuste: non c’è nulla di miracoloso.
Poiché l’IA generativa si basa largamente sul prompt dell’utente e usa uno studio delle probabilità per continuare l’input e produrre la sua risposta, il prompt stesso deve essere chiaro, ben strutturato e argomentato. Un prompt di qualità permette generalmente di ricevere risposte di qualità.
Se non c’è un processo di riflessione, non si è creata una strategia, l’IA generativa non serve a nulla. Il suo ruolo è quello di “copilota” perché fornisce strumenti per migliorare e velocizzare il lavoro e in alcuni casi anche lo studio.
Acquisire consapevolezza sui limiti delle IA generative
L’importante è essere consapevoli che i modelli generativi, in forza della loro stessa natura, possono commettere errori e offrire rappresentazioni fattuali che non corrispondono al vero.
Chi utilizza il modello generativo, a qualsiasi livello, deve quindi “accendere il cervello”, esaminare i contenuti con spirito critico e disporre di un bagaglio culturale ed esperienziale sufficienti.
Ciò compreso, l’IA sta davvero cambiando il mondo del lavoro, come certifica anche Anthropic. Può contribuire a migliorare la società perché, ad esempio, permette di avere accesso a contenuti che diversamente sarebbero complessi da recuperare usando approcci tradizionali.
Usare l’IA per estrarre valore e far emergere dettagli ai quali nessuno aveva pensato prima
L’IA aiuta ad estrarre valore dall’intero scibile umano così come dai dati di una singola impresa od organizzazione raccolti in decenni di attività. Quale essere umano riuscirebbe a “scartabellare” quei contenuti, comprendere relazioni, collegamenti e ottenere punti di vista innovativi? Nessuno. I modelli generativi permettono invece di farlo riuscendo a stabilire connessioni che nessuno si sarebbe mai sognato di cercare.
Pensate anche che si possono realizzare IA generative specializzate in settori specifici. “Dando in pasto”, nella fase di addestramento, risorse relative a documenti medici e scientifici, è possibile estrarre valore e idee alle quali nessuno aveva pensato prima.
Già oggi l’IA ha aiutato e continua ad aiutare i ricercatori nella scoperta di nuovi materiali, nello studio dei meccanismi biologici, nell’individuazione di cure efficaci per le malattie e molto altro ancora.
L’IA nel mondo del lavoro
In quali settori del mercato si registra il maggior utilizzo delle soluzioni basate sull’IA? Lo sviluppo software e le attività di scrittura tecnica dominano con il 37,2%.
Il comparto “arti, media ed editoria” (10,3%) e quello di istruzione e biblioteche (9,3%) seguono a distanza. L’IA conferma invece di avere ad oggi un impatto marginale nei settori a forte componente fisica, come agricoltura e trasporti.
Secondo Anthropic, il 57% delle interazioni è classificato come augmentative: l’IA affianca cioè il lavoratore per migliorare la produttività. Il 43% delle attività rientrano nel novero dell’automazione diretta: in questo caso l’IA svolge autonomamente i compiti assegnati.
Ancora, l’uso dell’AI risulta più radicato nei lavori a salario medio-alto: Anthropic fa riferimento, per esempio, alle figure del programmatore e dell’analista di dati.
Solo il 4% delle professioni utilizza l’AI per gestire oltre il 75% delle attività lavorative; il 36% si serve dell’intelligenza artificiale in almeno il 25% delle mansioni. Ciò indica che l’AI non sta completamente automatizzando le professioni, ma sta trasformando il modo con cui sono svolti i compiti.
Problemi e rischi dell’IA
L’uso dell’intelligenza artificiale porta con sé numerosi vantaggi, ma anche una serie di problemi e rischi che devono essere considerati. Questi problemi possono essere suddivisi in diverse categorie: etici, sociali, economici, tecnici e di sicurezza.
Utilizzo dello scraping e modalità di addestramento
I modelli generativi sono addestrati su grandi quantità di dati, che spesso contengono pregiudizi già esistenti nella società. Se i dati di addestramento sono distorti, l’IA può amplificare discriminazioni legate a razza, genere, religione o status socio-economico.
L’uso indiscriminato di meccanismi di scraping del Web (scansione automatizzata delle pagine pubblicate online) o di altre fonti può comportare l’acquisizione di dati personali che invece non dovrebbero essere utilizzati per formare le “conoscenze di base” del modello.
Modelli generativi chiusi e aperti
Nel caso dei modelli generativi commerciali, a meno che l’utente non esprima il suo diniego, le informazioni condivise con il LLM sotto forma di prompt sono raccolte e utilizzate per migliorare il comportamento del modello stesso (addestramento continuo). Esiste quindi anche un problema di privacy (riservatezza dei dati).
Per questo motivo è importante disporre di modelli generativi aperti, slegati da qualunque interesse commerciale (ne parliamo nei punti seguenti).
Ruolo di copilota e accesso alle risorse per l’IA
L’intelligenza artificiale deve essere sempre una sorta di “copilota” e non sostituire l’uomo nello svolgimento delle sue mansioni.
L’accesso alle risorse per addestrare modelli avanzati non può essere limitato a pochi soggetti con ingenti risorse economiche. È necessario da un lato promuovere l’accesso alle risorse per addestrare i modelli in maniera indipendente, dall’altro promuovere modelli aperti, ai quali tutti gli interessati possano accedere. In modo da far circolare le conoscenze e promuovere lo sviluppo di progetti derivati e innovativi.
Non è possibile pensare che il progresso della società possa dipendere quasi esclusivamente dagli avanzamenti in campo AI promossi da una manciata di colossi tecnologici, con finalità prettamente commerciali.
Generazione di contenuti errati o inventati
I modelli generativi possono produrre informazioni errate o completamente inventate (le cosiddette “allucinazioni”), generando contenuti non affidabili.
I modelli generativi sono fatti per restare tra noi e ormai è impensabile non ritenere che gli studenti possano farne uso. Ancora una volta, però, gli studenti devono essere informati sui limiti dell’IA generativa, sul fatto che possa commettere errori e che il suo utilizzo senza disporre di sufficienti competenze può essere soltanto controproducente. In ogni caso, in fase di verifica si è chiamati in proprio a dare prova delle conoscenze acquisite.
Il ruolo del legislatore
Le leggi non stanno al passo con lo sviluppo dell’AI. Per evitare un vuoto normativo sono comunque necessari provvedimenti che garantiscono un uso etico dell’IA senza porre freni all’innovazione responsabile. In ottica futura, inoltre, se un’IA prendesse una decisione errata o dannosa, chi ne è responsabile?
Allo stesso tempo, comunque, il legislatore deve trovare sempre il giusto equilibrio per evitare di soffocare tecnologie, come quelle su cui si basa l’IA, con un fortissimo carico di innovazione.
Il futuro dell’intelligenza artificiale
Il futuro dell’intelligenza artificiale sarà segnato da un’evoluzione sempre più multimodale, in cui le IA non si limiteranno più alla sola elaborazione del testo, ma integreranno in modo avanzato immagini, video, audio e altri tipi di dati.
Grazie alla computer vision (visione artificiale, in italiano), le macchine potranno “comprendere” (sempre tra virgolette) e analizzare gli spazi circostanti con una precisione crescente, migliorando applicazioni come il riconoscimento facciale, la guida autonoma e la diagnostica medica.
Nei prossimi anni, vedremo IA capaci di interagire con l’ambiente in modo più naturale, interpretando simultaneamente testo, immagini e suoni per offrire risposte più ricche e contestualizzate.
Questo porterà a innovazioni in settori chiave come la robotica, l’assistenza a distanza, la didattica, il Web, gli assistenti digitali, l’automotive (veicoli guidati dall’IA, in grado ad esempio di frenare per evitare un incidente, di rilevare automaticamente situazioni di pericolo, di preservare la sicurezza dei passeggeri, dei pedoni e dei ciclisti…), la sicurezza (non sono informatica, ma anche quella sul lavoro), l’analisi delle informazioni e molto altro ancora, creando esperienze sempre più immersive e personalizzate.
Gli agenti AI stanno emergendo come una delle innovazioni più rivoluzionarie nel campo dell’intelligenza artificiale. A differenza dei chatbot e dei sistemi di automazione tradizionali, questi agenti saranno in grado di eseguire compiti complessi in modo autonomo, prendere decisioni in base a dati in tempo reale e interagire con gli utenti e altri sistemi in modo avanzato.
E secondo voi? Combinando tutto quello che abbiamo realizzato fino ad oggi con i modelli generativi, come potrebbe cambiare il mondo nei prossimi anni? Cosa potrebbero diventare le IA in futuro?
Perché i Governi stanno investendo sull’IA?
Diversi Paesi stanno investendo massicciamente nell’intelligenza artificiale perché riconoscono il suo enorme potenziale strategico ed economico.
L’IA è vista come un motore di innovazione capace di migliorare la produttività, ottimizzare i servizi pubblici e rafforzare la sicurezza nazionale. Inoltre, i Paesi che guidano lo sviluppo dell’IA possono acquisire un vantaggio competitivo nei settori tecnologici, industriali, scientifico e medico, della ricerca, della sicurezza informatica e della gestione dei dati.
Un altro aspetto chiave è la sovranità digitale: affidarsi esclusivamente a tecnologie sviluppate da aziende o nazioni straniere può creare dipendenze critiche. Per questo, molti Governi stanno promuovendo lo sviluppo di infrastrutture AI nazionali, regolamentazioni specifiche e investimenti nella ricerca per garantire indipendenza tecnologica e sicurezza dei dati.
L’IA è cruciale per affrontare sfide globali come il cambiamento climatico, la sanità, la mobilità e la gestione delle città intelligenti. Un’IA ben regolata e sviluppata in modo etico può diventare un alleato fenomenale per il progresso sociale ed economico.
Note finali e qualche suggerimento pratico
Al di sopra dell’impalcatura sin qui descritta, tanti fornitori di soluzioni di intelligenza artificiale generativa hanno costruito chatbot che integrano funzionalità evolute.
In alcuni casi, il reasoning/thinking va attivato su richiesta dell’utente, ad esempio premendo un pulsante o scegliendo manualmente un modello generativo.
La memoria è una caratteristica che permette al chatbot di ricordare informazioni sull’utente, sui suoi interessi, sul lavoro che svolge e così via. È uno strumento utile per ottenere risposte ancora più pertinenti.
Si può ad esempio scrivere al chatbot: “ricordati che quando scrivo RIASSUNTO devi creare un riassunto del testo che ti fornisco; quando scrivo ESTENDI devi ampliare il testo che ti incollo; quando scrivo TRADUCI devi tradurre il testo in italiano creandone una versione ben argomentata e approfondita“.
Funzione Canvas
La funzione Canvas di ChatGPT, ad esempio, apre un riquadro separato all’interno del chatbot che consente una collaborazione più profonda, non limitata alla conversazione, ma basata sulla creazione e il perfezionamento delle idee.
Canvas arricchisce l’esperienza di scrittura con funzionalità avanzate come i suggerimenti inline (“in linea”) per migliorare il testo, regolarne la lunghezza (permette di accorciare od estendere i contenuti) e il livello di leggibilità. A seconda delle competenze del lettore, si possono creare testi adatti alla scuola primaria fino ad arrivare al livello accademico avanzato.
Grazie a Canvas, ChatGPT è in grado di svolgere un’operazione di polishing finale migliorando grammatica, chiarezza e coerenza. Si possono inoltre aggiungere emoji per enfatizzare o colorare il contenuto.
Sviluppo software assistito dall’IA
Anche chi sviluppa software per far funzionare computer e dispositivi può usare Canvas come “copilota”: il sistema semplifica il processo iterativo che guida l’utente fino al raggiungimento del traguardo prefissato. Canvas aiuta con i suggerimenti in linea per migliorare il codice, può aggiungere istruzioni per il debug (“correzione degli errori”) e commenti che rendono più comprensibile ciascuna routine di programmazione.
Questo significa che un chatbot diventa utilizzabile in ambito STEM (Science, Technology, Engineering e Mathematics) con un’infinità di possibili campi applicativi. Basti pensare che, sempre con un ruolo di “copilota”, chatbot come ChatGPT, Claude, Mistral, Copilot e Phind possono creare programmi per computer. Aiutano chi comincia a programmare ma anche chi ha competenze avanzate!
Prendete Claude e digitate ad esempio quanto segue:
Crea il gioco Snake. Utilizza icone spiritose e permetti l’utilizzo della tastiera per muovere il serpente. Fai in modo che quando il serpente batte sui bordi il gioco finisca (game over). Le icone che scegli devono essere chiare e ben visibili.
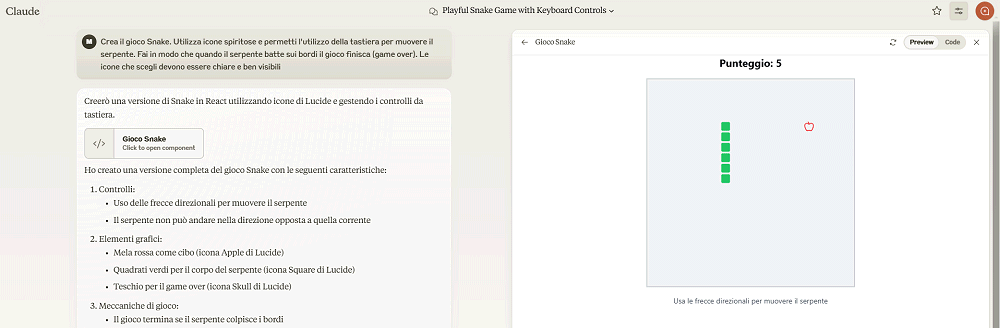
Claude crea il codice di programmazione per far muovere il serpente sullo schermo e mostra un’anteprima giocabile del gioco che può essere scaricata e utilizzata liberamente.
Funzioni di ricerca sul Web e contenuti aggiornati
Tanti chabot integrano inoltre la funzionalità Search o Cerca. Questo significa che possono produrre contenuti anche abbinando l’utilizzo di informazioni “fresche” pubblicate sul Web.
Il problema di fondo dei LLM, infatti, è che la loro data di addestramento è ferma nel tempo. Di fatto, le “conoscenze” del modello sono bloccate a una certa data. Tutto quello che è avvenuto dopo resta del tutto sconosciuto al modello.
Per colmare anche questa lacuna è stata introdotta la generazione “aumentata” dai contenuti Web: in questo modo è possibile ottenere risposte che spiegano fatti e accadimenti recenti (anche quelli in corso!…). Il bello è che in questo caso il chatbot fornisce anche i riferimenti alle fonti, ossia i link alle pagine Web dalle quali ha tratto le informazioni.
Perplexity, ad esempio, ha sempre usato questo approccio mentre con altri chatbot è necessario richiedere esplicitamente l’utilizzo della ricerca sul Web per ottenere informazioni utilizzando fonti aggiornate.
Chattare con il contenuto dei documenti
Alcuni tra i principali chatbot sono in grado di estendere la “base di conoscenza” dei sottostanti LLM accettando in input veri e propri documenti, come ad esempio file PDF. L’applicazione basata sull’intelligenza artificiale generativa, è in grado di leggere l’intero contenuto del documento, riassumerlo e restare in attesa di richieste specifiche da parte dell’utente.
Ricevendo uno o più documenti in ingresso, quindi, il chatbot e il corrispondente LLM possono istantaneamente estendere le proprie abilità e trasformarsi in un “copilota” specializzato sui contenuti trattati proprio nei documenti inviati dall’utente.
Chatbot come ChatGPT, Perplexity (funzione Spazi) e l’eccellente Google NotebookLM, consentono anche di creare veri e propri spazi di lavoro all’interno dei quali salvare documenti, ma anche video, immagini, pagine Web e molto altro ancora. Tutte le informazioni presenti nel materiale conferito all’interno del proprio spazio di lavoro contribuiscono a formare immediatamente una “base di conoscenze” utile per le necessità dell’utente.
Ponendo domande semplici o complesse, l’utente può interfacciarsi con le informazioni caricate e ricevere risposte pertinenti e ben argomentate.
Conclusioni
In un mondo sempre più interconnesso e digitale, l’intelligenza artificiale rappresenta una rivoluzione senza precedenti, capace di trasformare il nostro modo di lavorare, comunicare e vivere.
Comprendere il funzionamento dell’IA, i suoi benefici e i suoi limiti è essenziale per utilizzarla in modo consapevole e responsabile.
Il futuro dell’IA dipenderà da come sceglieremo di svilupparla e regolamentarla: sarà uno strumento straordinario per migliorare la nostra quotidianità, a patto di garantire trasparenza, equità e accessibilità.
La sfida è aperta, e sta a noi coglierne le opportunità senza perdere di vista i valori che contano davvero.
/https://www.ilsoftware.it/app/uploads/2023/09/GPT-4V-modello-openai.jpg "OpenAI si prepara al lancio di GPT-4.1?")
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_474959_1744385645.jpeg "Ecco perché Apple è così indietro con l'AI")
/https://www.ilsoftware.it/app/uploads/2025/03/windows-11-aggiornamento-KB5053656.jpg "Microsoft rilancia la funzione AI Recall su Windows 11")
/https://www.ilsoftware.it/app/uploads/2025/03/ILSOFTWARE-7-2.jpg "OpenAI lancia BrowseComp: il nuovo benchmark per valutare le ricerche online dell'AI")