/https://www.ilsoftware.it/app/uploads/2024/04/oracle-intelligenza-artificiale-futuro.jpg "Il futuro dell'intelligenza artificiale secondo Oracle: ne parliamo con Luigi Saetta")
Grazie al machine learning e all’intelligenza artificiale si può fare business intelligence come mai prima d’ora, per estrarre valore da quegli stessi dati che le imprese già posseggono e gestiscono. Ogni azienda può contare su una vera e propria ontologia di dati, un insieme di informazioni di grande valore che aiutano a compiere decisioni consapevoli e migliorare le linee di business.
Fino a poco tempo fa, estrarre informazioni utili dall’enorme mole di dati conservata on-premises oppure sul cloud da ciascuna azienda era cosa davvero complessa. Durante l’evento Oracle CloudWorld Tour svoltosi a Milano nei giorni scorsi, i portavoce dell’azienda fondata da Larry Ellison hanno posto l’accento proprio sui nuovi scenari che l’IA e le soluzioni Oracle possono aprire.
Abbiamo avuto l’opportunità di confrontarci con Luigi Saetta, Cloud Domain Specialist EMEA – ML & AI, Oracle, che ci ha fornito un quadro dettagliato sulle attuali soluzioni basate sull’IA, sui modelli generativi e su come questi strumenti possano integrarsi con i flussi di lavoro e i workload di ciascuna azienda.

Modelli generativi per estrarre valore dai dati aziendali
I modelli generativi che conosciamo e utilizziamo oggi utilizzano un approccio stocastico, basato sulle relazioni probabilistiche che sussistono fra i vari dati. A questo proposito, abbiamo chiesto a Luigi Saetta se la tendenza sarà questa, in futuro, o se veda delle soluzioni alternative realmente esplorabili (e soprattutto affidabili).
Saetta premette, innanzi tutto, che è difficile fare previsioni su ciò che avverrà domani. Soprattutto in questo campo. Stiamo vivendo un’epoca di cambiamenti sostanziali, guidati proprio dall’IA, ai quali mai avremmo pensato addirittura soltanto 2 o 3 anni fa. “Oggi, nell’ambito dell’intelligenza artificiale generativa applicata al linguaggio naturale si utilizzano reti neurali. Il primo approccio che si utilizza è una addestramento con supervisione: fornendo un input insieme con l’output atteso, si insegna al modello a trovare molteplici correlazioni. Nel caso dei modelli linguistici, si insegna a comprendere il linguaggio prevedendo le parole successive“, osserva Saetta.
È corretto dire che che siamo di fronte a un approccio di tipo probabilistico perché il modello, per ciascuna posizione nell’input, genera una distribuzione di probabilità. Con alcuni modelli è comunque possibile applicare già oggi alcune personalizzazioni profonde, ad esempio richiedendo la generazione di singole parole e non l’intera distribuzione di probabilità.
L’approccio sarà ibrido: modelli più deterministici. Ecco cosa significa
Il passo successivo, chiarisce Saetta, è insegnare al modello – attraverso il cosiddetto Extraction Fine-Tuning – a compiere delle attività in una maniera più deterministica. “È questo l’aspetto che ci interessa di più in ambito aziendale. Quello che serve alle aziende non è la risposta a una domanda aperta ma fare altre cose del tipo << Scrivi un’email che spieghi al cliente quali sono le funzionalità, le caratteristiche di questo prodotto >>. Ciò avviene sulla base di una documentazione precedentemente creata dall’azienda stessa. Il modello si innesta con la base di conoscenza a disposizione della specifica azienda, che viene fornita in ingresso, e diventa in grado di citare le fonti“.
Osserva Saetta che lato business è appunto essenziale avere a disposizione un modello che chiarisca da dove provengono le informazioni fornite in output all’utente. In questo senso, lo schema sta virando su un approccio più deterministico proprio perché il modello stesso cerca di determinare la risposta migliore correlandola con la sottostante knowledge base.
L’approccio stocastico non è comunque rinnegato: lo strumento generativo è spesso sfruttato per esplorare più possibilità. Saetta spiega che l’intento è quello di non avere un’unica e univoca risposta, preferendo dare comunque spazio alla creatività. Il senso è lasciare che l’IA fornisca N possibili risposte: tocca poi alla persona in carne ed ossa scegliere quella che considera la più adatta, pertinente e argomentata. “Nell’ambito del linguaggio ci sono N modi per esprimere lo stesso concetto: spesso è anche soggettivo sostenere che una risposta sia migliore rispetto a un’altra“.
Oracle Vector Search: cosa sono e perché sono vera rivoluzione
Le Vector Search di Oracle sono una funzionalità “inedita”, di recentissima presentazione, che affonda le sue radici su un nuovo tipo di dati vettoriali, su indici vettoriali e operatori SQL. La forza di Oracle è da sempre la fornitura di soluzioni avanzate per la gestione dei dati.
Ecco, l’intelligenza artificiale sta rivoluzionando sin dalle fondamenta l’approccio alla gestione del dato. Con le Vector Search, Oracle permette ai suoi clienti di memorizzare e trattare il contenuto di dati non strutturati e immagini in formato vettoriale, consentendo di eseguire rapidamente ricerche semantiche.

“Integrando le Vector Search è possibile cercare nell’ontologia di dati aziendali, nella base di conoscenza dell’impresa, le porzioni di documenti che possono essere utili per rispondere a ciascuna specifica richiesta“, spiega Saetta. “In questo modo si chiede al modello di rispondere non più in maniera libera ma attenendosi alle fonti interne dell’azienda. Per la prima volta abbiamo chiuso il cerchio: il modello stesso indica la porzione di testo, presa dall’ontologia aziendale, che è stata utilizzata per generare la risposta“. Come accennato in precedenza, quindi, Oracle è in grado di consegnare nelle mani degli utenti soluzioni che sfruttano un approccio decisamente più deterministico, con la possibilità di personalizzare gli output restituiti.
Utilizzando appositi Command, è possibile istruire il modello con richieste del tipo “usa un tono formale” oppure “usa un tono familiare“: in questo modo si può ancor più condizionare e determinare l’output del modello.
Le salvaguardie per assicurarsi che le informazioni in output siano di qualità e non si basino su bias
“Oracle sta svolgendo un attento lavoro di controllo sugli output generati dal modello, per evitare risposte inaccettabili. Ad esempio evitare bias ovvero discriminazioni e comportamenti indesiderati“, sottolinea Saetta. “Non prendiamo un modello generativo << as-is >> dalle aziende con le quali collaboriamo, ma aggiungiamo una serie di salvaguardie con un approccio serio e responsabile“.
Con le Vector Search, insomma, Oracle supporta anche la cosiddetta Retrieval Augmented Generation (RAG), una tecnica innovativa di IA generativa che combina Large Language Models (LLM) e dati del business aziendale per fornire risposte alle domande poste usando il linguaggio naturale. Questa funzione offre maggiore precisione ed evita di esporre all’esterno dati aziendali.
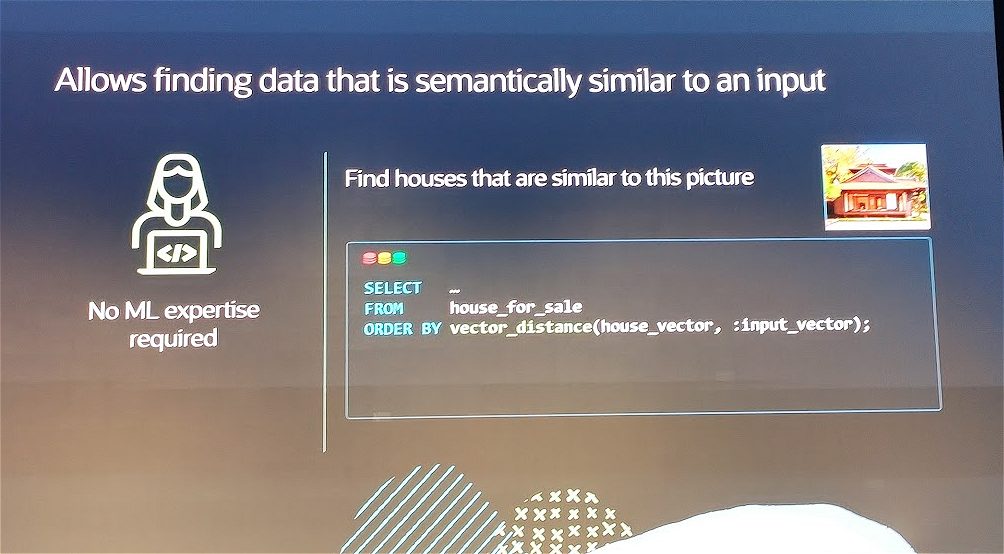
L’utilizzo di Oracle AI Vector Search non richiede competenze specifiche sul versante del machine learning, e tutti gli utenti, compresi sviluppatori e amministratori, possono imparare a usarlo in meno di 30 minuti.
Le opportunità consegnate agli utenti dalle Vector Search, rappresentano un punto di svolta nell’ambito dello sviluppo: i programmatori possono creare applicazioni e generare query con SQL senza codice, utilizzando semplici richieste in linguaggio naturale.

Il percorso da seguire per un’azienda che vuole provare i benefici dell’IA sui suoi dati usando la piattaforma Oracle
Abbiamo chiesto a Luigi Saetta quale percorso suggerirebbe di intraprendere a un’azienda che desidera iniziare a toccare con mano i benefici offerti dalla piattaforma Oracle per l’elaborazione dei suoi dati e l’estrazione di valore dagli stessi.
“Oggi c’è un certo << hype >> legato alle tecnologie che hanno a che fare con l’intelligenza artificiale. Ma cosa è possibile farci nel concreto? Oracle parte dalle reali esigenze delle aziende“, dice Saetta spiegando che l’obiettivo deve essere quello di ottenere un vantaggio tangibile. Ad esempio, il miglioramento delle informazioni e del servizio resi alla clientela, anche in maniera misurabile: “quello che si misura si riesce anche a valorizzare e migliorare“.
Per Saetta si deve partire da una specifica esigenza di business, non dal livello tecnico, e su quella iniziare a costruire valore grazie alle nuove tecnologie imperniate sui modelli generativi e sulle soluzioni Oracle.
Puntare sul concetto di MVP, quindi su un insieme di funzionalità minime per poi aggiungere moduli
L’ideale sarebbe ipotizzare le funzionalità minime che si vorrebbero ottenere: l’approccio MVP (Minimum Viable Product) funziona non soltanto nel campo dell’IA ma per qualunque altro prodotto o servizio che voglia davvero essere innovativo.
L’obiettivo è concentrarsi sulle funzionalità chiave che forniranno valore agli utenti: così facendo si possono ridurre i costi di sviluppo e accelerare il tempo di lancio sul mercato (il cosiddetto time-to-market), consentendo alle aziende di testare le loro ipotesi e adattare il prodotto alle esigenze e alle preferenze dei clienti in modo più flessibile.
La sfida della gestione della ricerca documentale in azienda
“Se un’azienda intende approcciarsi per passi all’IA generativa ma è un po’ preoccupata della parte di generazione, che può apparire ostica, è possibile sfruttare le tecnologie di ricerca vettoriale per migliorare la ricerca nella documentazione all’interno dell’impresa“, racconta Saetta. “Molte aziende ancora oggi si avvalgono di strumenti di ricerca che sono quasi preistorici: accade spesso che si debbano letteralmente indovinare le parole chiave giuste per trovare uno specifico documento“.
Per questa necessità, ci sono aziende specializzate che offrono servizi di ricerca evoluti. Ma di solito sono scarsamente personalizzabili, costano veramente tanto e, soprattutto, l’azienda rischia di concedere a un soggetto terzo l’accesso alla propria proprietà intellettuale, venendo meno ai principi di sovranità del dato sui quali il legislatore europeo sta spingendo tanto.
“Grazie al database basato su ricerca vettoriale Oracle è possibile caricare in breve tempo la documentazione dell’azienda, ad esempio il risultato della ricerca e sviluppo di 10 anni di attività e disporre di una ricerca semantica, quindi incentrata sui contenuti anziché sulle singole parole chiave“, mette in evidenza Saetta. “In questo modo i decisori aziendali, i manager, i dipendenti, i collaboratori, possono effettuare ricerche usando il linguaggio naturale“.
Recuperare le informazioni aziendali, costruire valore e migliorare la produttività
Oracle spazza via la necessità di imparare lo strumento perché è quest’ultimo che si adatta alle specifiche e mutevoli esigenze di ogni utilizzatore. “Tante aziende dispongono di un vastissimo patrimonio di conoscenza, soprattutto quelle largamente impegnate in ricerca e sviluppo. Si pensi alle aziende farmaceutiche, alle organizzazioni governative, a tutte quelle che servono la loro clientela“.
Saetta consiglia insomma di cominciare con la parte di recupero delle informazioni (information retrieval), anche e soprattutto da enormi moli di dati non strutturati, per poi – in un secondo momento – aggiungere la parte che genera la risposta finale. Quest’ultima dovrebbe essere letta dalla persona in azienda deputata a decidere se quella risposta debba essere fornita direttamente al cliente o ulteriormente raffinata.
“L’adozione di modelli generativi e delle tecnologie Oracle è imprescindibile in tutti quei contesti in cui si possono generare contenuti a partire dalla conoscenza dell’azienda. Non dico che è banale, ma è ormai alla portata di tutti“, continua Saetta. In ogni caso, l’obiettivo è quello di fornire la risposta ottimale partendo da un corpus di dati aziendali che in alcuni casi può essere davvero voluminoso e impossibile da gestire con un approccio manuale. I vantaggi in termini di produttività sono incalcolabili.
In Italia siamo ancora un po’ troppo cauti
Saetta cerca di spronare le aziende italiane: “in generale, siamo un po’ troppo cauti nell’esplorare nuove soluzioni“. L’esperienza di Oracle in altri mercati, continua Saetta, rappresenta la conferma di come in Italia si possa fare di più e meglio, sia nel settore pubblico che nel privato.
Da un lato è bene essersi posti delle domande e chiedersi dei limiti da porre sulla tecnologia ma dall’altro, probabilmente, ci preoccupiamo troppo ad esempio dell’AI Act. L’AI Act è il primo regolamento europeo sull’intelligenza artificiale che mira a promuovere lo sviluppo responsabile e sostenibile dell’IA nell’Unione Europea. Il regolamento si basa sul principio che l’IA deve essere utilizzata in modo sicuro, etico e rispettoso dei diritti fondamentali e dei valori europei.
“L’unico obbligo reale che discende dall’AI Act è quello della trasparenza. Le aziende di solito non si occupano certo di sistemi di sorveglianza, di biometrica o di altre tematiche del genere“, afferma Saetta che ripete quanto invece sia cruciale investire su sistemi che permettano di migliorare i flussi di lavoro, massimizzare la produttività e la redditività.
Il tema della sovranità del dato al centro dell’approccio Oracle
Il concetto di sovranità del dato è sempre più caro al legislatore europeo e, ovviamente, sempre più stella polare per le aziende italiane. In che modo le soluzioni Oracle guardano in questa direzione e quali garanzie offrono in termini di conformità per le singole imprese?
Saetta ci spiega che Oracle è molto attenta alla questione, delicata e meritevole di essere soppesata con la massima attenzione. Primo punto cruciale: “Oracle non usa i dati dei clienti per migliorare le performance dei modelli. Lo possono fare altre realtà, che devono comunque chiedere esplicita autorizzazione ai clienti e farlo in maniera chiara, ma Oracle non esamina, non modifica né riutilizza in alcun modo il dato“, evidenzia Saetta. “Il cliente sceglie in quale regione Oracle conservare i suoi dati, quando e come accedervi, decidere se effettuare un eventuale fine-tuning del modello. Quello che Oracle ha fatto è semplificare l’operazione, in modo da migliorare le prestazioni del modello foundation“.
I dati del cliente, insomma, stanno dove il cliente vuole metterli, ad esempio all’interno dell’Unione Europea. Quei dati sono accessibili solo dal cliente stesso e non sono copiati o spostati altrove.
Emblematico l’esempio del Polo Strategico Nazionale (PSN) che può condividere tecnologie di computing di alto livello tra un gran numero di Pubbliche Amministrazioni, facilitandone l’accesso anche da parte delle realtà medio-piccole.
Come coniugare sostenibilità e innovazione nel campo dell’intelligenza artificiale?
Abbiamo osservato in tanti nostri articoli come la fase di inferenza sia, alla fine, quella computazionalmente meno esigente quando si parla di modelli generativi e di intelligenza artificiale in generale. È però la parte legata all’addestramento che non può prescindere dall’utilizzo di risorse di calcolo estremamente impegnative, probabilmente oggi appannaggio degli hyperscaler e di poche altre realtà.
A fronte di una domanda che continuerà a crescere, già nel prossimo futuro, abbiamo chiesto a Saetta come si possano davvero coniugare sostenibilità e innovazione nel campo dell’intelligenza artificiale.
“Innanzi tutto, Oracle è impegnata nell’avvicinarsi sempre più al traguardo del 100% in termini di utilizzo di energie rinnovabili“, è la considerazione di carattere generale restituitaci da Saetta. “C’è però un aspetto cruciale che riguarda Oracle. L’azienda non ha scelto la strada di abbracciare i modelli generativi di più grandi dimensioni, ad esempio GPT-4. Il CEO di NVIDIA ha rivelato che GPT-4 utilizza 1,4 trillion in termini di parametri: richiede una quantità di memoria impressionante“.
La soluzione giusta è investire sui modelli più leggeri ed efficienti
L’obiettivo di Oracle, invece, è quello di selezionare modelli più leggeri, più facili da gestire e maggiormente adatti alle esigenze delle singole aziende. Spesso bastano modelli da 30-34 miliardi di parametri o modelli molto più piccoli: questi ultimi ben si adattano alle aziende che devono affrontare un insieme di attività ben definite, all’interno di un dominio specifico. Così possono sviluppare un fine-tuning sui propri dati usando un modello di taglia media (ad esempio da 7 miliardi di parametri), piuttosto che abbracciare (inutilmente) modelli di più grandi dimensioni.
Proporre l’uso di modelli più efficienti significa mettere nelle mani degli utenti modelli che costano meno e sono quindi molto più “comodi” da ottimizzare quando si deve farvi fine-tuning usando i propri dati.
“La chiave è insomma da un lato cercare di usare modelli della dimensione giusta; dall’altro selezionare modelli che sono innovativi in termini di architettura interna. In questo modo è possibile spingere l’acceleratore sull’aspetto dell’efficienza. Bisogna sviluppare un meccanismo premiante che privilegia l’azienda che non fornisce il modello più grande bensì quella che offre il modello delle giuste dimensioni e che consuma meno energia“. E conclude Saetta rifacendosi a una considerazione di Bill Gates: “fintanto che non si faranno pagare le emissioni di CO2, non si faranno dei passi avanti significativi; si continuerà a scaricare un debito sulle generazioni future, sui nostri figli e sui loro figli“.
Automazione e ottimizzazione dei flussi di lavoro
Ogni volta che si desidera introdurre innovazione è necessario cercare un partner o comunque studiare per raggiungere l’obiettivo prefisso, racconta Saetta, a cui abbiamo portato l’esempio di un foglio elettronico Excel composto da 400 “sotto-fogli” governati da complesse macro VBA. Sembra impossibile, eppure tante aziende ancora oggi lavorano così.
Il foglio Excel in questione è talmente complicato, la persona che l’ha realizzato se n’è andata o è andata in pensione, che quanto fatto in passato – da cui dipendono letteralmente i flussi di lavoro dell’impresa – non può essere modificato.
In questo caso l’azienda è cristallizzata, è bloccata, e non ha più margini di miglioramento. “Se le aziende non si dotano dei migliori strumenti, abbinando investimenti a un’attenta attività di formazione, non riusciremo più ad avere la forza lavoro sulla quale potevamo contare in precedenza. Il divario tra il numero di soggetti che escono dal mondo del lavoro e quanti vi entrano è davvero impressionante“, tiene a sottolineare Saetta. “Una produttività basata solo sugli esseri umani, che non abbraccia l’uso delle tecnologie basate sull’IA non può crescere“.
Credit immagine in apertura: Oracle.
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475760_1744976324.jpeg "Meglio essere educati con l'AI: non si sa mai")
/https://www.ilsoftware.it/app/uploads/2024/07/chip-IA-openai.jpg "OpenAI lancia Flex Processing: rivoluzione dei costi API per modelli AI")
/https://www.ilsoftware.it/app/uploads/2025/04/grok-lg-ai-emotiva-pubblicita.jpg "LG lancia l'AI emotiva sulle Smart TV: pubblicità su misura per i tuoi sentimenti")
/https://www.ilsoftware.it/app/uploads/2025/01/chatgpt-impatto-ambientale-consumo-acqua.jpg "ChatGPT o3: la rivoluzione nella geolocalizzazione tramite immagini")