/https://www.ilsoftware.it/app/uploads/2024/04/eseguire-llama-3-in-locale-come-fare.jpg "Eseguire Llama 3 in locale su Windows e Raspberry Pi 5")
Ad aprile 2024, Meta ha compiuto un ulteriore passo avanti proponendo quello che presenta come il Large Language Model (LLM) più evoluto al momento disponibile sulla scena. Si tratta di Llama 3, un potente modello linguistico pre-addestrato e ottimizzati con 8 miliardi (8B) e 70 miliardi (70B) di parametri, a seconda della versione. Per questo si rivela adatto a una vastissima gamma di possibili campi applicativi.
Rispetto al predecessore Llama 2, poggia il suo funzionamento su un set di dati che è sette volte più grande e che, soprattutto, include anche dati non inglesi di alta qualità in oltre 30 lingue. Una solida pipeline di filtraggio dei dati è volta a garantire la massima qualità dei dati di addestramento, che uniscono le informazioni provenienti da diverse fonti.
Diversamente rispetto ad altri modelli proprietari, Llama 3 utilizza un approccio aperto e può essere impiegato anche per sviluppare progetti commerciali, senza problemi in termini di licenza.
Mentre, come dimostriamo in questo nostro articolo, la fase di inferenza risulta piuttosto agevole, creare il modello Llama 3 ha richiesto una potenza di calcolo immensa, con gli ingegneri di Meta che hanno utilizzato una batteria di GPU NVidia H100 (oltre 24.500).
Come eseguire Llama 3 in locale con LM Studio
Per provare Llama 3 in locale da un sistema basato su Windows, suggeriamo di scaricare e installare il software open source LM Studio. Ne abbiamo parlato insieme a Ollama nell’articolo incentrato su come eseguire LLM sui propri sistemi usando un’interfaccia grafica.
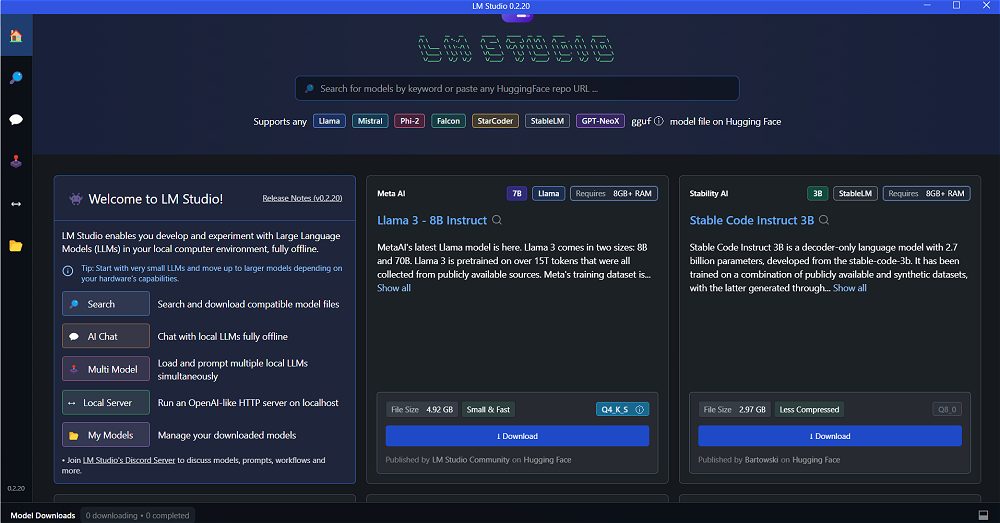
Sin dal primo avvio, LM Studio dichiara la sua compatibilità con una vasta schiera di LLM, compresi recenti Llama 3 8B e 70B. Utilizzando la casella di ricerca in alto oppure i riquadri presentati appena al di sotto di essa, si può scegliere il modello generativo (o i modelli!) dei quali ci si vuole servire. Per ridurre il peso dei dati da scaricare, proviamo ad esempio a selezionare Llama 3 – 8B Instruct autorizzando il download di quasi 5 GB di informazioni.
Iniziare a chattare con il modello scaricato in locale
Una volta conclusa la procedura di download del modello, il pulsante AI Chat posto all’interno della colonna di sinistra, consente di avviare una conversazione in maniera molto simile a quanto avviene con ChatGPT. La differenza è che, in questo caso, nessun dato è trasferito su server remoti e tutte le informazioni restano sempre e comunque custodite in ambito locale.
Nel caso in cui si fossero scaricati in locale più LLM, LM Studio permette di scegliere quello che si vuole di volta in volta usare per avviare una sessione di chat.
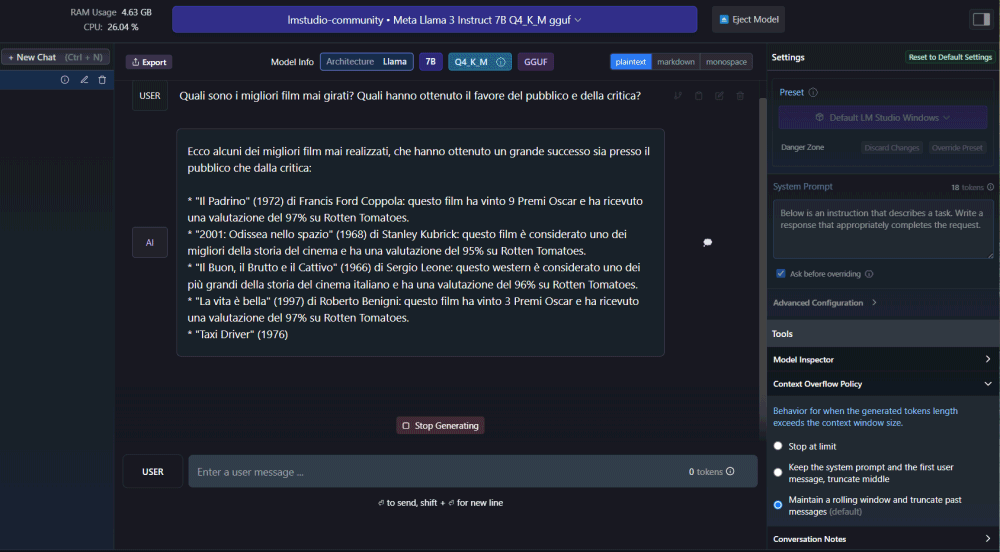
A questo punto, utilizzando il campo Enter a user message in basso, è possibile iniziare a chattare con Llama 3 (così come con altri modelli) per verificare la qualità delle risposte offerte a seconda degli input (prompt) passati al sistema.
Usare le API per dialogare con LM Studio
Una delle migliori caratteristiche di LM Studio è il supporto per le API (Application Programming Interface). Si tratta di una caratteristica che, evidentemente, strizza l’occhio agli sviluppatori consentendo loro di interagire con i vari modelli scaricati in locale dalle proprie applicazioni.
Il procedimento è molto semplice: basta cliccare su Local Server, pulsante posto nella colonna di sinistra, specificare il LLM da utilizzare e lasciare che LM Studio avvii un componente server dedicato, cliccando sul pulsante Start Server.
Per impostazione predefinita, è possibile dialogare con il server di LM Studio utilizzando il protocollo HTTP sulla porta 1234. È comunque possibile personalizzare il comportamento del server come meglio si crede.
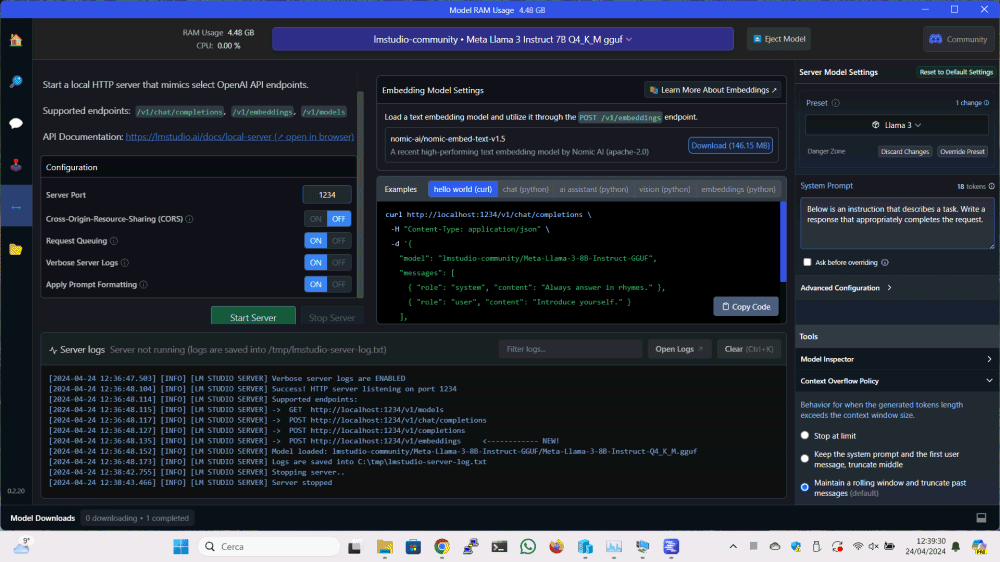
Nel riquadro Examples, il programma fornisce alcuni esempi di codice di programmazione pronto per l’uso, da usare nei propri progetti per inviare un prompt al modello prescelto e ottenere in risposta un output ovvero un’argomentazione pertinente e precisa.
Senza scomodare lo sviluppo, si possono anche effettuare dei semplici test usando l’utilità da riga di comando curl. Ad esempio, con il comando seguente si può ottenere la lista dei modelli installati attraverso LM Studio:
curl http://localhost:1234/v1/models
Nell’esempio si fa riferimento alla macchina locale localhost ma, ovviamente, modificando opportunamente la configurazione del firewall di Windows, si può interrogare LM Studio anche da altri sistemi in rete locale. Maggiori informazioni sono disponibili nell’articolo di supporto LM Studio Server.
Come eseguire Llama 3 su una scheda Raspberry Pi 5
Nell’articolo citato in apertura, abbiamo presentato Ollama WebUI ovvero la versione dotata di interfaccia grafica di un apprezzato tool basato su CLI (command-line interface) che permette di interagire con qualsiasi modello generativo open source oggi disponibile.
Di Ollama e della possibilità di portare l’IA sui propri sistemi abbiamo abbondantemente parlato in passato. Dal momento che Ollama è compatibile con Llama 3 e che l’applicazione è distribuita anche in versione per Linux, si può pensare di usarla ad esempio su una scheda Raspberry Pi 5.
Basta semplicemente accedere alla finestra del terminale del sistema operativo installato su Raspberry Pi 5 quindi digitare i comandi seguenti:
curl -fsSL https://ollama.com/install.sh | sh
ollama run llama3
Il secondo comando, quando eseguito per la prima volta, provvede a richiedere il download in locale del modello Llama 3, predisponendone poi l’utilizzo con Ollama. Nelle fasi seguenti, lo stesso comando indica semplicemente a Ollama la volontà di usare il modello Llama 3. Il prompt successivamente presentato resta in attesa della domanda da passare al LLM.
Per maggiori informazioni, è possibile fare riferimento al nostro approfondimento su Ollama: chi volesse utilizzare una più accattivante e pratica interfaccia Web, può infine installare Ollama WebUI.
Anche in questo caso l’API REST dedicata permette di dialogare con Ollama e con il sottostante LLM Llama 3 da altre applicazioni in esecuzione sullo stesso sistema o su altri dispositivi. Per default, l’API di Ollama è in ascolto sulla porta 11434: questo significa che si può lasciare la scheda Raspberry Pi 5 collegata alla LAN e interagire con la base di conoscenze di Llama 3 in modalità client-server da altri device.
Credit immagine in apertura: Copilot Designer.
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "Test matematici USAMO 2025: tutti i modelli AI deludono le aspettative")
/https://www.ilsoftware.it/app/uploads/2025/04/SoC-intel-automotive.jpg "Intel rilancia anche con i nuovi SoC Panther Lake e Nova Lake per i veicoli")
/https://www.ilsoftware.it/app/uploads/2025/04/rayban-meta-occhiali-smart.jpg "Gli occhiali smart di Ray-Ban Meta iniziano a diventare davvero utili")