/https://www.ilsoftware.it/app/uploads/2023/05/img_25875.jpg "Dawn AI, cos'è e quali alternative usare per generare avatar con l'intelligenza artificiale")
I modelli basati sull’intelligenza artificiale utilizzabili per creare contenuti nuovi hanno fatto registrare una crescita esponenziale nell’ultimo periodo. I modelli generativi che permettono di creare immagini a partire da un testo in linguaggio naturale sono una classe di modelli di deep learning che utilizzano tecniche di generazione di immagini basate su testo (text-to-image generation) per creare immagini realistiche da descrizioni testuali.
Si tratta di modelli generativi che sfruttano una rete neurale generativa avversaria (GAN) o una rete neurale convoluzionale (CNN) per generare le immagini. Nello specifico, il modello riceve in input una descrizione testuale e genera un’immagine che corrisponde alla descrizione. La rete generativa produce l’immagine a partire dalla descrizione testuale mentre una rete discriminativa valuta la qualità dell’immagine prodotta: le due reti lavorano in modo avversario, cercando di migliorarsi a vicenda.
Ad oggi esistono diversi approcci per la generazione di immagini basati su testo. In un caso, ad esempio, una GAN produce immagini sempre più dettagliate a partire da una descrizione testuale di basso livello; in un altro il modello sfrutta il ben noto meccanismo di attenzione, emerso nel 2017 con la pubblicazione del documento Attention is all you need e utilizzato ad esempio anche dal chatbot ChatGPT; in un altro ancora, ed è il caso ad esempio di DALL-E, il modello presentato da OpenAI a settembre 2022 per la generazione di immagini a partire da testo, viene usata una una combinazione di GAN e transformer per produrre immagini a partire da descrizioni testuali. La GAN viene utilizzata per generare immagini realistiche, mentre il transformer (ne abbiamo parlato anche nell’articolo dedicato alla scheda Jetson Orin Nano) per associare la descrizione testuale all’immagine prodotta.
Cos’è e come funziona Dawn AI
Dawn AI è uno strumento che utilizza l’intelligenza artificiale per creare immagini. Con la funzione text-to-image alla base di Dawn AI, l’applicazione diventa un generatore di avatar installabile e utilizzabile sui dispositivi Android e iOS.
Dawn AI si concentra su avatar e immagini raffiguranti persone: utilizza il deep learning per creare bellissime opere d’arte digitale.
Dawn AI è scaricabile gratis ma rispetto a quanto permetteva di fare in passato, le abilità accessibili dagli utenti “non a pagamento” sono state significativamente ridotte.
Con Dawn AI l’utente è chiamato a caricare da 8 a 12 selfie: l’app analizza le immagini e crea un’opera d’arte “unica” ispirata allo stile artistico selezionato. L’applicazione offre inoltre opzioni per regolare aspetti come colore, dimensione del pennello e saturazione.
Alternative a Dawn AI
Esistono oggi numerose alternative a Dawn AI e c’è anche la possibilità (ne parliamo più avanti), di eseguire in proprio il modello generativo che prende in input un insieme di foto e genera avatar o immagini artistiche di qualità.
Il già citato DALL-E è uno strumento generativo sviluppato da OpenAI che consente di creare da zero opere d’arte uniche piuttosto che modificare contenuti preesistenti. Come generatore di immagini senza particolari limitazioni, consigliamo di usare Bing Image Creator che è stato sviluppato dai tecnici Microsoft proprio appoggiandosi a DALL-E.
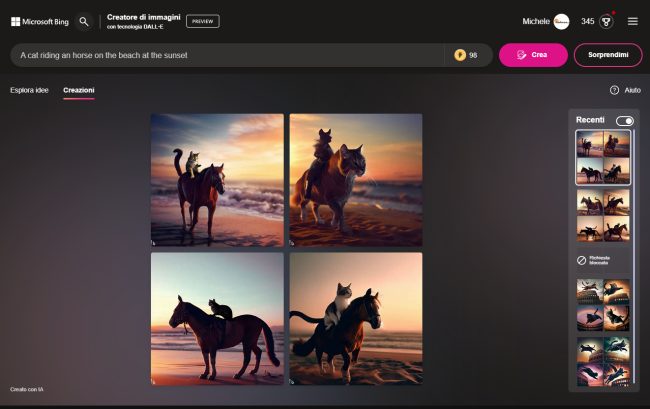
Midjourney è invece un’alternativa che è stata sviluppata da un laboratorio di ricerca indipendente: anche in questo caso è possibile trasformare prompt testuali in accattivanti immagini di grande bellezza.
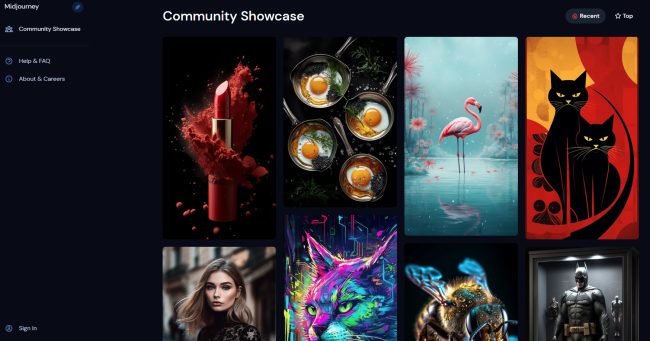
Aiby Arta per Android e per iOS acquisisce le immagini dell’utente e le utilizza come base per la generazione degli avatar. Il potente generatore di immagini trasforma le idee in arte in pochi secondi.
Molto valido è anche Hotpot.ai che consente di creare grafica e immagini professionali senza alcuna abilità di progettazione. Questo strumento mette a disposizione degli utenti un ampio ventaglio di modelli e stili tra cui scegliere. Può anche ripristinare, migliorare e riparare le foto danneggiate. Alcuni tool sono a pagamento previo acquisto di crediti mentre altri sono completamente gratuiti (seppur con un limite variabile sul numero di creatività generabili).
Merita sicuramente una menzione speciale anche Artbreeder: basato sul Web, permette la creazione di immagini digitali “uniche”. Artbreeder utilizza il machine learning per generare nuove immagini basate su quelle caricate dall’utente facilitando la creazione di mashup.
Anche Wonder AI per Android e per iOS permette sia di trasformare le foto in elaborazioni artistiche, sia di generare elaborate realizzazioni grafiche a partire da descrizioni testuali.
Wombo Dream trasforma le idee in dipinti basati sfruttando l’intelligenza artificiale, il tutto in pochi secondi. Il servizio, accessibile via Web o tramite app installabile sui dispositivi mobili, offre una varietà di stili e colori per fare esperimenti.
Come creare avatar e immagini artistiche con Stable Diffusion e Dreambooth
Finora ci siamo concentrati solamente su alcuni dei tanti strumenti oggi disponibili per la generazione di contenuti a partire da foto e testi. Gli utenti possono tuttavia servirsi in proprio di strumenti “aperti” che consentono di raggiungere gli stessi risultati, senza neppure versare importi variabili o canoni di abbonamento: bastano solo un po’ di pazienza e di volontà.
Dreambooth è un modello di generazione utilizzato per mettere a punto i modelli text-to-image esistenti: sviluppato dai ricercatori di Google Research e della Boston University nel 2022, permette di affinare il comportamento di un altro strumento (ad esempio di Stable Diffusion) per produrre immagini affidabili e coerenti a seconda degli stili e dei soggetti.
Stable Diffusion è un modello generativo che è stato sviluppato dalla start-up Stability AI in collaborazione con numerosi ricercatori accademici e organizzazioni no-profit. Stable Diffusion viene utilizzato principalmente per generare immagini dettagliate a partire da descrizioni testuali, sebbene possa essere sfruttato anche per attività di inpainting, outpainting e trasformazioni da immagine a immagine.
L’inpainting si riferisce alla tecnica di riempimento di un’area mancante o danneggiata di un’immagine con una nuova porzione che si integra in modo realistico con il resto dell’immagine. Questa tecnica viene spesso utilizzata per riparare immagini danneggiate o per rimuovere elementi indesiderati dalle immagini.
Si chiama outpainting, invece, quella tecnica che si concentra sulla generazione di nuove parti di un’immagine oltre i suoi limiti originali: vengono in questo caso generate porzioni dell’immagine che non sono presenti nell’originale.
Questa tecnica può essere utilizzata per ridimensionare un’immagine in modo creativo, senza ricorrere l’upscaling, ad esempio aggiungendo elementi di sfondo o creando di sana pianta degli elementi.
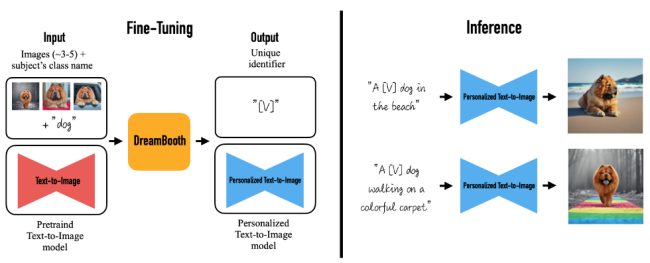
Nell’immagine (fonte GitHub Dreambooth, Google Research) il funzionamento di Dreambooth con una vista panoramica ad alto livello.
Per usare il modello Dreambooth è necessario dotarsi di un insieme di foto di alta qualità, anche se poi all’atto pratico si ottengono buoni risultati anche con immagini a risoluzione inferiore. La pratica comune consiste nel selezionare diverse immagini del soggetto in una varietà di pose, ambienti e condizioni di illuminazione: nel documento tecnico che illustra come funziona Dreambooth vengono usate 3-5 foto: l’ideale, tuttavia, sarebbe servirsi certamente di più di 15-20 immagini.
Jake Dahn ha pubblicato una guida passo-passo per l’addestramento di Dreambooth a partire dal proprio set di immagini. Spiega di essersi avvalso di Replicate, una piattaforma che permette di eseguire modelli per il machine learning con poche righe di codice, sul cloud, senza quindi doversi attrezzare in locale.
Replicate accetta in ingresso script bash (.sh): in questo modo, come ha fatto Dahn, è possibile indicare quali operazioni devono essere svolte. La sintassi da utilizzare per la creazione dello script è contenuta in questo post che spiega come integrare Replicate con Dreambooth.
Come parametro instance_data è possibile fornire un archivio compresso (raggiungibile via HTTP/HTTPS) contenente le immagini da usare per l’attività di addestramento.
Gli altri parametri rilevanti sono i seguenti:
Una descrizione che si utilizzerebbe per descrivere l’immagine del soggetto raffigurato nelle immagini di esempio (chi o cosa è rappresentato nell’archivio di foto creato in precedenza).
Una descrizione più ampia e articolata di ciò che si desidera ottenere.
Il numero di passi di addestramento che il modello deve eseguire. Un numero sensato è prevedere 100 passaggi per ogni immagine fornita in input. Ad esempio, se nell’archivio compresso si fossero inserite 20 immagini, il valore da specificare può essere 2000.
Lunga stringa alfanumerica che indica quale versione del modello generativo si vuole utilizzare (ad esempio Stable Diffusion 1.5 o 2.1).
L’addestramento di un modello Dreambooth richiede tempo (spesso decine e decine di minuti): è quindi utile ricevere una notifica non appena il lavoro viene completato. Allo scopo è possibile utilizzare un webhook specificando l’URL corrispondente.
L’indirizzo al quale viene aggiunto il modello Dreambooth: corrisponde all’account Replicate dell’utente.
Dahn ha poi utilizzato un semplice script Python che ripete per 10 volte 10 prompt facendo così generare all’intelligenza artificiale un totale di 100 immagini. Ciascun prompt corrisponde a una particolareggiata descrizione delle immagini che si desiderano ottenere a partire dal set di foto già fornito per l’addestramento.
In questo modo si otterranno immagini di scarso interesse ma anche realizzazioni artistiche di grande valore e con impatto visivo incredibile!
/https://www.ilsoftware.it/app/uploads/2024/11/generico-streaming-tv.jpg "Streaming: un'altra piattaforma introduce il Membro Extra")
/https://www.ilsoftware.it/app/uploads/2024/06/YouTube-Music.jpg "YouTube Music introduce nuova funzione per normalizzare il volume")
/https://www.ilsoftware.it/app/uploads/2025/04/pinta-editor-immagini-open-source.jpg "Arriva Pinta 3.0, alternativa leggera a Paint.NET e GIMP")
/https://www.ilsoftware.it/app/uploads/2025/04/formato-RAW-fotocamera-digitale.jpg "RAW: perché i produttori di fotocamere usano formati differenti?")