/https://www.ilsoftware.it/app/uploads/2023/09/CSV-analisi-dati-database.jpg "File CSV, cos'è e come e trasformarlo in un database")
I file CSV, acronimo di Comma-Separated Values (in italiano “valori separati da virgole”), sono un formato comunemente utilizzato per archiviare dati tabellari in modo strutturato e leggibile sia dagli umani che dai computer. Questi file sono ampiamente utilizzati in una vasta gamma di applicazioni, tra cui fogli di calcolo, software di analisi dati, ai fini dell’importazione all’interno di database e molto altro ancora.
I dati sono suddivisi in righe e colonne: tracciando un’analogia con un database, in un file CSV ogni riga rappresenta di fatto un record mentre le colonne contengono i vari campi. Un CSV è un file di testo in cui i dati sono separati da un delimitatore, che è spesso una virgola, ma può anche essere un punto e virgola, una tabulazione o un altro carattere. Questo delimitatore segnala il confine tra il contenuto delle varie colonne di dati. È ovviamente opportuno scegliere bene il delimitatore per evitare che il suo utilizzo all’interno del CSV possa essere erroneamente interpretato.
Questi tipi di file sono ampiamente utilizzati perché hanno il vantaggio di essere universalmente compatibili: sono supportati da una vasta gamma di applicazioni, inclusi fogli di calcolo come Microsoft Excel e LibreOffice Calc, Office Online, Google Workspace, Microsoft 365, ONLYOFFICE, software di analisi dati come Python con la libreria pandas e via dicendo.
Imparare a elaborare CSV con un file della Banca Centrale Europea
La Banca Centrale Europea (BCE) pubblica e aggiorna quotidianamente un file con i tassi di cambio dell’euro (EUR) rispetto ad altre valute. Questi dati sono resi disponibili proprio come file CSV contenuto all’interno di un archivio compresso in formato Zip.
Un semplice file Zip contenente un file CSV, sembra all’apparenza quasi insignificante: in realtà una enorme quantità di applicazioni finanziarie utilizza il file della BCE ogni singolo giorno.
Gli ideatori del progetto csvbase, hanno pubblicato un interessantissimo post in cui spiegano come il loro strumento e semplici comandi impartiti dalla finestra del terminale Linux, consentano di trasformare i file CSV in un database e di estrarre informazioni utili per le proprie attività da una serie di dati in partenza difficili da interpretare e gestire.
Ponendo di aver installato curl, SQLite e Python (eventualmente anche gnupilot e DuckDB, vedere più avanti) nella distribuzione Linux che si utilizza abitualmente (in Windows si può usare l’interfaccia bash di WSL, Windows Subsystem for Linux), gli sviluppatori di csvbase invitano a impartire i comandi che seguono:
curl -s https://www.ecb.europa.eu/stats/eurofxref/eurofxref-hist.zip \ | gunzip \ | sqlite3 -csv ':memory:' '.import /dev/stdin stdin' \ "select Date from stdin order by USD asc limit 1;"
Il simbolo della pipe (|) consente di concatenare più comandi ed eseguirli uno dopo l’altro.

Il primo comando curl scarica i dati dai server della BCE con l’archivio compresso che è poi successivamente “unzippato“. Infine, il comando sqlite3 interroga il file CSV contenuto in memoria, per poi caricarne il contenuto in una tabella chiamata stdin. La stringa finale corrisponde a una query SQL SELECT che estrae la data in cui, al cambio, il dollaro era più forte rispetto all’euro.
Il bello è che il file CSV della BCE contiene più di 6.300 valori: in un attimo è possibile estrarre quello che interessa attingendo direttamente al contenuto della memoria.
Pulizia e melting di un file CSV: cosa significa
Quando si lavora con un file in formato CSV, può accadere che i dati non abbiano la struttura che serve per sviluppare il proprio progetto. Da csvbase si spiega che con semplici interventi dalla riga di comando, si può facilmente ottenere ciò che si vuole.
Il file CSV pubblicato e quotidianamente aggiornato dalla BCE, è probabilmente uno dei più puliti e meglio strutturati che si possono oggi trovare in giro. Eppure c’è un’imperfezione: in fondo a ogni riga c’è un delimitatore superfluo (virgola) che non dovrebbe esserci. Gli sviluppatori di csvbase presentano quindi il codice seguente:
curl -s https://www.ecb.europa.eu/stats/eurofxref/eurofxref-hist.zip | \
gunzip | \
python3 -c 'import sys, pandas as pd
pd.read_csv(sys.stdin).iloc[:, :-1].melt("Date")\
.to_csv(sys.stdout, index=False)'
I comandi forniti effettuano una serie di operazioni per scaricare, decomprimere e manipolare il CSV contenente i dati storici sui tassi di cambio delle varie valute.
Nell’esempio, il comando python3 avvia un’istanza di Python ed esegue un breve script che innanzi tutto importa il modulo sys per l’accesso alle funzionalità del sistema e pandas per la manipolazione dei dati.
Con pd.read_csv(sys.stdin) si leggono i dati CSV dallo standard input (l’output del comando gunzip contenente i dati decompressi) per poi passarli a un DataFrame pandas.
Per eliminare la virgola finale presente in ogni riga, lo script Python usa .iloc[:, :-1] che appunto forza la rimozione dell’ultima colonna del DataFrame.
Richiedere il melting dei dati: cos’è
Lo script Python fornito da csvbase effettua anche un’altra importante operazione, ovvero il melting dei dati CSV. Si tratta di un concetto ampiamente utilizzato nell’ambito dell’analisi dei dati.
È una tecnica che consente di trasformare una struttura di dati da una forma “wide” (larga) a una forma “long” (lunga) così da rendere più agevole l’analisi e la visualizzazione dei dati stessi.
Supponiamo di avere un set di dati in forma “wide” che rappresenta le temperature medie mensili di tre città nei diversi anni:
| Anno | Città_A | Città_B | Città_C |
|---|---|---|---|
| 2020 | 22.5 | 23.0 | 21.2 |
| 2021 | 23.1 | 24.5 | 22.9 |
| 2022 | 22.7 | 23.8 | 21.5 |
Il melting può essere in questo caso utilizzato per ottenere una serie storica dei dati in formato long:
| Anno | Città | Temperatura_Media |
|---|---|---|
| 2020 | Città_A | 22.5 |
| 2020 | Città_B | 23.0 |
| 2020 | Città_C | 21.2 |
| 2021 | Città_A | 23.1 |
| 2021 | Città_B | 24.5 |
| 2021 | Città_C | 22.9 |
| 2022 | Città_A | 22.7 |
| 2022 | Città_B | 23.8 |
| 2022 | Città_C | 21.5 |
Con questo approccio ogni riga rappresenta una specifica combinazione di anno, città e temperatura media. Si tratta di una rappresentazione che semplifica l’analisi dei dati, ad esempio, per calcolare la temperatura media annuale per ciascuna città o per visualizzare i dati in grafici a dispersione.
Melting sul file CSV della BCE
È un po’ lo stesso caso dell’esempio del valore dei tassi di cambio: gli sviluppatori di csvbase, utilizzando lo script presentato in precedenza, hanno generato una sequenza di dati formata da 260.000 record che offre in maniera “esplosa” gli andamenti di ciascuna valuta giorno dopo giorno dai primi anni ’90.
La “magia” sta nell’uso del metodo .melt("Date"), una funzione che esegue appunto l’operazione di melting per ottenere un DataFrame in forma wide. In ogni riga si ottiene una prima colonna con la data, una seconda con l’identificativo della valuta e una terza con il tasso di cambio.
Da ultimo, .to_csv(sys.stdout, index=False) converte di nuovi i dati risultanti in formato CSV inviandoli allo standard output (sys.stdout). L’opzione index=False impedisce la scrittura dell’indice delle righe nel file CSV risultante.
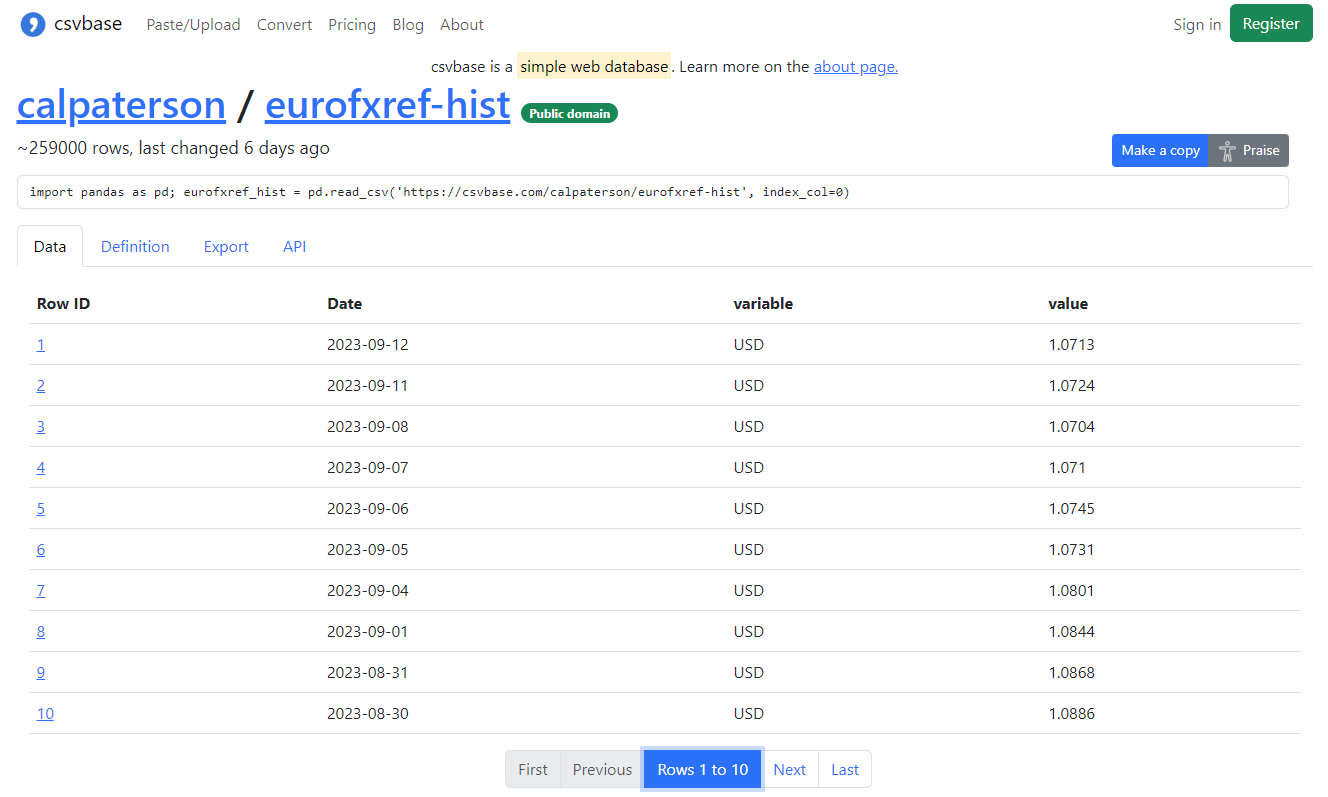
csvbase: cos’è e come funziona
csvbase è un semplice sistema di gestione di database Web progettato per l’interazione e la manipolazione di dati tabellari in formato CSV. Disponibile come progetto open source su GitHub, csvbase offre un’interfaccia Web intuitiva che consente agli utenti di visualizzare, aggiungere, modificare ed eliminare righe all’interno di tabelle di dati direttamente da un browser. Questa facilità d’uso rende csvbase accessibile anche a coloro che non sono esperti di programmazione e che non conoscono SQL a menadito.
Gli utenti possono esportare i dati delle tabelle in vari formati, tra cui CSV, XLSX e altri ancora. Ogni tabella csvbase, inoltre, ha un’unica URL: il tool utilizza lo schema RESTful, in cui ogni tabella può essere richiamata usando i “verbi” del protocollo HTTP.
Ad esempio, con HTTP PUT, si può creare una nuova tabella o sovrascriverne una esistente con altri dati; con HTTP DELETE eliminare una tabella esistente; con HTTP POST aggiungere nuove righe di dati in blocco a una tabella preesistente.
csvbase è compatibile con diversi strumenti di analisi dati e linguaggi di programmazione, tra cui pandas, Apache Spark, R, DuckDB. La piattaforma supporta inoltre qualsiasi altro strumento che possa effettuare richieste HTTP. Ciò facilita l’integrazione dei dati gestiti da csvbase nelle proprie attività di analisi ed elaborazione.
Creare grafici a partire dal CSV con gnuplot e DuckDB
Dopo aver caricato il risultato del melting su csvbase con il comando curl -n --upload-file, si può ad esempio ricorrere a questo script (sempre proposto da Cal Paterson) per ottenere un grafico:
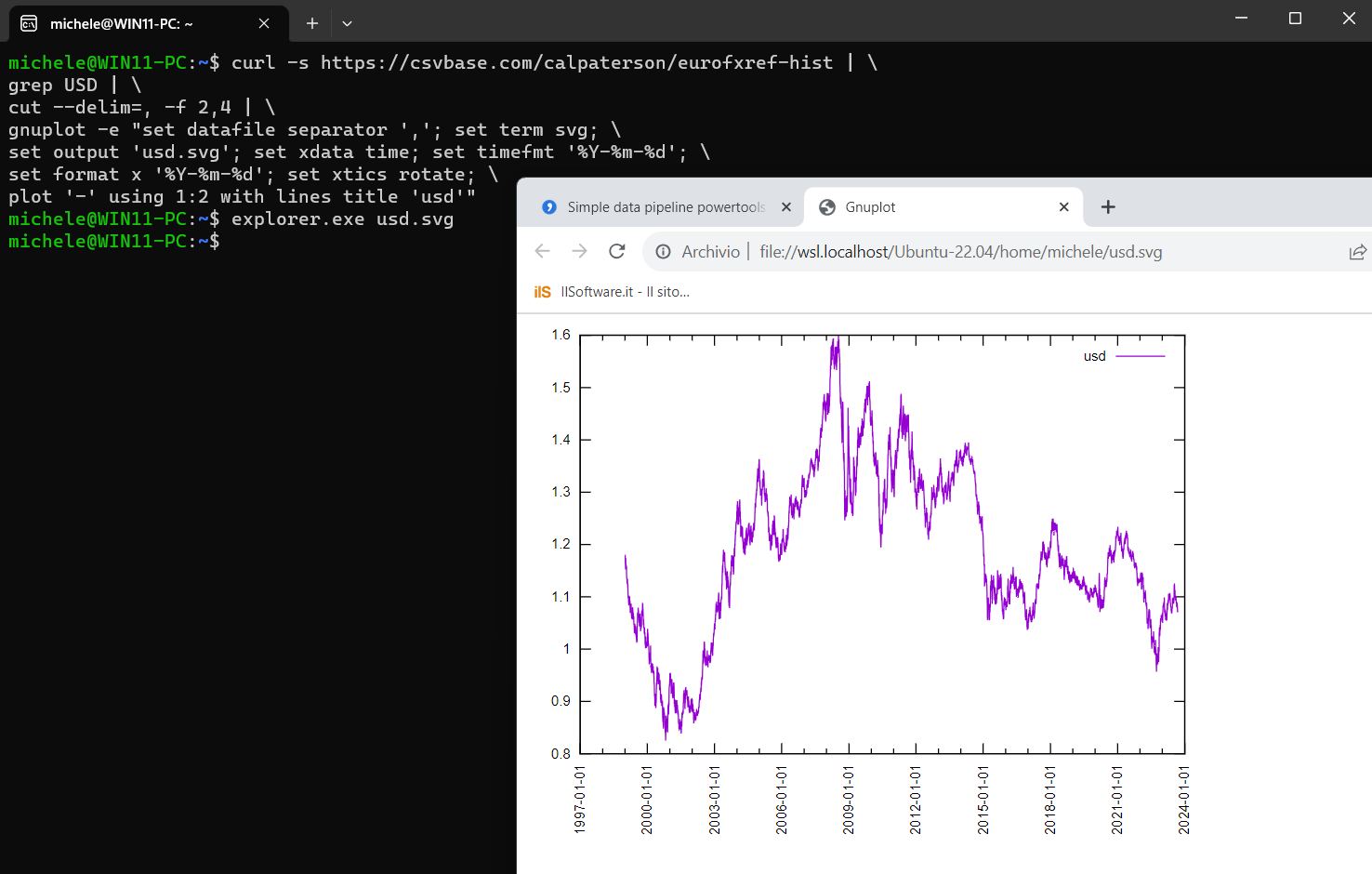
curl -s https://csvbase.com/calpaterson/eurofxref-hist | \ grep USD | \ cut --delim=, -f 2,4 | \ gnuplot -e "set datafile separator ','; set term svg; \ set output 'usd.svg'; set xdata time; set timefmt '%Y-%m-%d'; \ set format x '%Y-%m-%d'; set xtics rotate; \ plot '-' using 1:2 with lines title 'usd'"
Il primo comando scarica i dati da csvbase quindi, con un grep USD, si estraggono molto semplicemente tutte le righe contenenti la stringa “USD” ovvero le informazioni sui tassi di cambio tra l’euro e il dollaro statunitense. Con il comando cut --delim=, -f 2,4 lo script estrae solamente le colonne 2 e 4.
Generazione del grafico con gnuplot
Infine, ricorrendo a gnuplot, lo script provvede a creare un grafico basato sui dati filtrati precedentemente. Gnuplot è un software open source che semplifica la creazione di grafici e la visualizzazione di dati in forma grafica. È ampiamente utilizzato in ambito scientifico, ingegneristico e tecnico per generare grafici di dati su vari sistemi operativi, compresi Linux, macOS e Windows. Gnuplot offre numerose funzionalità e opzioni di personalizzazione per creare una vasta gamma di tipi di grafici, tra cui grafici a dispersione, grafici a barre, grafici a linee, istogrammi e molto altro. Nell’esempio elaborato da Paterson, compaiono i seguenti switch e comandi:
set datafile separator ',': Specifica che il separatore di dati nel file in ingresso è la virgola, in quanto i dati sono in formato CSV.set term svg: Imposta il formato di output del grafico come SVG (Scalable Vector Graphics).set output 'usd.svg': Specifica il nome del file in cui verrà salvato il grafico.set xdata time: Indica che i dati sull’asse delle ascisse rappresentano valori temporali.set timefmt '%Y-%m-%d': Specifica il formato della data nei dati in ingresso. La stringa indicata permette di rappresentare le date nel formato “AAAA-MM-GG”.set format x '%Y-%m-%d': Imposta il formato delle etichette sull’asse delle ascisse.set xtics rotate: Ruota le etichette dell’asse delle ascisse per migliorare la leggibilità.plot '-' using 1:2 with lines title 'usd': È il comando che traccia materialmente il grafico. Utilizza i dati provenienti dallo standard input (indicato da “-“) e traccia una linea utilizzando la prima colonna (data) come asse delle ascisse e la seconda colonna (tasso di cambio USD) come asse delle ordinate. La stringa “usd” è utilizzata come titolo del grafico.
Per aprire il file usd.svg contenente l’andamento dei tassi dollaro-euro nel tempo dalla finestra di WSL in Windows, basta digitare explorer.exe usd.svg e premere Invio.
DuckDB: cos’è e a cosa serve
DuckDB è un sistema di gestione di database relazionale (DBMS) open source progettato per l’analisi di dati veloci e l’esecuzione di query complesse su grandi set di dati. È sviluppato principalmente per applicazioni di analisi dei dati e di business intelligence (BI), dove la velocità di esecuzione delle query è cruciale.
Tra le caratteristiche peculiari di DuckDB, ricordiamo la velocità elevata, l’utilizzo della compressione per ridurre lo spazio di archiviazione necessario e migliorare le prestazioni delle query, il supporto per la sintassi SQL standard, quello per la libreria pandas di Python, per l’esecuzione di aggregazioni in modo parallelo così da sfruttare al massimo i processori multicore.
DuckDB, inoltre, poggia su uno storage columnar: i dati sono organizzati per colonne anziché per righe. L’architettura è ottimizzata per operazioni di aggregazione e analisi, poiché consente di ridurre al minimo l’accesso ai dati non necessari durante l’esecuzione delle query. Proprio per questo DuckDB è stato scelto da Paterson nell’esempio in questione.
Non solo. Usando il comando CREATE TABLE nome_tabella AS SELECT * FROM read_csv_auto("URL"); si può ad esempio importare direttamente i dati con DuckDB da un file CSV pubblicato sul Web, anche su csvbase.
Ecco quindi che Paterson mette la proverbiale ciliegina sulla torta. Il comando seguente consente di disegnare un grafico con una linea che riassume la tendenza dei vari valori:
curl -s https://csvbase.com/calpaterson/eurofxref-hist | \
./duckdb -csv -c "select Date, avg(value) over \
(order by date rows between 100 preceding and current row) \
as rolling from read_csv_auto('/dev/stdin')
where variable = 'USD';" | \
gnuplot -e "set datafile separator ','; set term svg; \
set output 'usd2.svg'; set xdata time; set timefmt '%Y-%m-%d'; \
set format x '%Y-%m-%d'; set xtics rotate; \
plot '-' using 1:2 with lines title 'usd'"
In questo caso, lo script crea un file chiamato usd2.svg. Il compito svolto da gnupilot può eventualmente essere inserito in una funzione bash che prende in ingresso, ad esempio, il nome del file SVG da creare.
Uno degli aspetti più apprezzati di DuckDB è che risulta particolarmente abile nel comprendere i tipi di dati passati tramite un file CSV. Riesce inoltre a rilevare la dimensione del display concentrandosi sulla visualizzazione delle informazioni più utili.
Come installare DuckDB su Linux
Per installare DuckDB su Ubuntu Linux, è possibile usare i comandi seguenti:
wget https://github.com/duckdb/duckdb/releases/download/v0.8.1/duckdb_cli-linux-amd64.zip sudo install unzip -y unzip duckdb_cli-linux-amd64.zip ./duckdb --version
Al posto dell’URL associato al comando wget, va specificato quanto riportato in questa pagina.
Credit immagine in apertura: iStock.com/champpixs
/https://www.ilsoftware.it/app/uploads/2025/04/codex-cli-openai-cos-e-come-funziona.jpg "Codex CLI: cos'è l'agente AI di OpenAI che scrive e interpreta codice dal terminale")
/https://www.ilsoftware.it/app/uploads/2025/04/compleanno-git-20-anni-linus-torvalds.jpg "Git compie 20 anni e Linus Torvalds parla della sua creatura")
/https://www.ilsoftware.it/app/uploads/2025/04/sorgente-altair-basic.jpg "Microsoft rilascia il suo codice sorgente! Per festeggiare 50 anni di attività")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")