/https://www.ilsoftware.it/app/uploads/2024/05/funzionamento-LLM-IA.jpg "Come spiegare il funzionamento di un modello linguistico LLM senza usare la matematica (o quasi)")
Si fa un gran parlare, a tutti i livelli, di intelligenza artificiale generativa e il termine modelli linguistici è ormai sulla bocca di tutti. I Large Language Models (LLM) sono modelli di linguaggio ad alta capacità computazionale progettati per comprendere e generare testo in modo simile a come farebbe una persona in carne ed ossa. Sono capaci di svolgere una vasta gamma di compiti linguistici, come la traduzione automatica, la generazione di testo, la risposta alle domande, la creazione di riassunti e molto altro ancora. Possono “comprendere” il contesto e produrre testo coerente e significativo in risposta a domande o input in linguaggio naturale.
Nei nostri articoli, generalmente mettiamo il verbo “comprendere” tra virgolette perché i LLM non possono ovviamente poggiare sugli stessi meccanismi alla base del cervello umano. Cercano di approssimarne il funzionamento, a volte in modo piuttosto brillante, in altri casi in maniera meno efficace. Ma sempre di un’approssimazione parliamo.
Che cosa fa un LLM (Large Language Model)
Come abbiamo evidenziato in altri approfondimenti, il funzionamento dei LLM non è ben compreso da tanti utenti. Dietro al loro modus operandi c’è tanta matematica e statistica: per questo motivo è considerato ostico.
Al centro dei LLM c’è il concetto di token: spesso sovrapposti alle singole parole, in realtà possono rappresentare sequenze di caratteri oppure più parole (o porzioni di esse). Un token può anche esprimere un punto oppure uno spazio: l’obiettivo di ogni LLM è infatti codificare il testo nel modo più efficiente possibile.
A ogni token presente nel vocabolario proprio di uno specifico LLM, è assegnato un identificativo numerico univoco. Il LLM utilizza un tokenizer (traducibile in italiano come “tokenizzatore“) per effettuare la trasformazione del testo in una sequenza numerica equivalente. Queste rappresentazioni numeriche sono appunto i token.
Un esempio pratico con Python
Il codice Python che proponiamo di seguito utilizza la libreria tiktoken per codificare e decodificare testi utilizzando il modello GPT-2. Si tratta del più semplice modello che OpenAI ha rilasciato come prodotto open source, quindi studiabile nel dettaglio. In un altro articolo abbiamo visto come usare i fogli elettronici e GPT-2 per dimostrare il funzionamento degli LLM.
Dopo l’importazione del modulo, il codice codifica la frase indicata usando il modello GPT-2, con la funzione encoding_for_model(). Vedete i numeri restituiti per ciascun token? Ecco, effettuando un’operazione di decodifica, si può ottenere la frase iniziale.
>>> import tiktoken
>>> encoding = tiktoken.encoding_for_model("gpt-2")
>>> encoding.encode("Il gatto nero attraversa la strada buia.")
[33666, 308, 45807, 299, 3529, 708, 430, 690, 64, 8591, 965, 4763, 809, 544, 13]
>>> encoding.decode([33666, 308, 45807, 299, 3529, 708, 430, 690, 64, 8591, 965, 4763, 809, 544, 13])
'Il gatto nero attraversa la strada buia.'
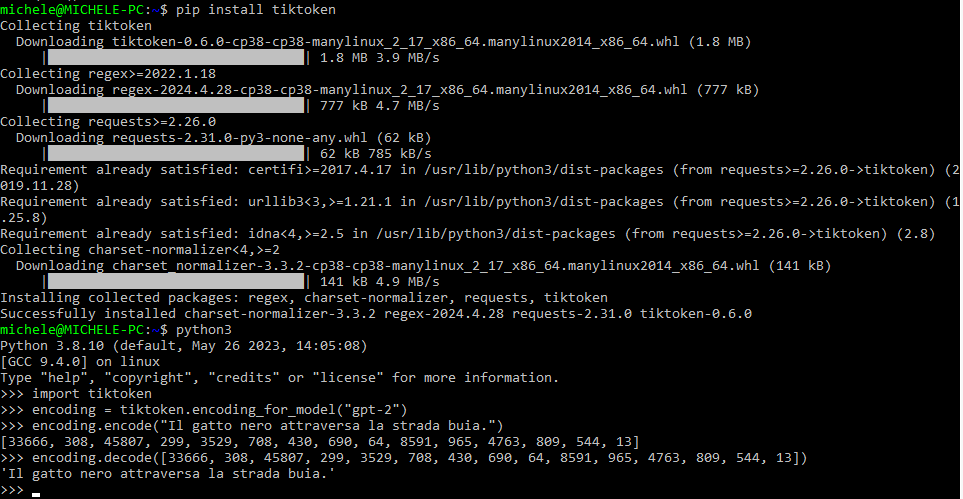
È interessante notare, come accennavamo in precedenza, che un token non contiene necessariamente una parola. Ad esempio, `[308]` viene decodificato in ‘ g’ (l’inizio della parola “gatto” con uno spazio iniziale), `[45807]` in ‘atto’ e `[13]` con un punto. Guardate l’output ottenuto in figura richiamando la funzione encoding.decode:
Da tenere presente che la libreria tiktoken richiamata tramite Python, va necessariamente installata usando il comando pip install tiktoken.
I modelli linguistici fanno previsioni
Torniamo all’asserzione con cui abbiamo cominciato: riferendoci alle abilità di “comprensione” dei LLM, mettiamo il termine fra virgolette. Perché l’approccio utilizzato da questi sistemi è fondamentalmente probabilistico. O meglio ancora, come raccontavamo nell’articolo sui modelli generativi al servizio delle decisioni aziendali, lo schema sfruttato è di tipo stocastico.
I modelli linguistici fanno previsioni su quale token seguirà quello in corso di elaborazione. Immaginate una funzione che restituisce la probabilità con cui ogni singolo termine contenuto nel vocabolario del modello possa seguire uno specifico token.
Poiché il vocabolario di GPT-2 poggia sull’utilizzo di 50.257 voci, la funzione (sviluppata ad esempio in Python) fornirebbe un elenco di numeri con l’indicazione della probabilità con cui il corrispondente token potrebbe seguire dopo la singola parola presa in esame.
Nel caso dell’esempio “Il gatto nero attraversa la strada buia“, si può ipotizzare che – ad esempio – una parola come “tonno” abbia una probabilità prossima allo zero di seguire nella frase. Molto probabilmente potrebbe seguire una congiunzione come “e”. “Il gatto nero attraversa la strada buia e si nasconde in una siepe“. Oppure, ancora, “e viene investito” o “e salta un fossato” o ancora “e sale su un taxi” (certamente meno probabile…).
Le previsioni ragionevoli scaturiscono da un’attenta fase di addestramento del modello. Al modello vengono passati volumi di testo spesso impressionanti in termini di dimensioni. In questo modo, può capire i legami semantici tra le parole del linguaggio, sempre e solo in termini probabilistici.
Al termine dell’addestramento, il modello può calcolare le probabilità con cui ciascun token possa succedere nelle varie frasi, a seconda delle sequenze di token già presenti, sulla base delle strutture dati costruite usando tutto il testo elaborato durante la fase di addestramento.
Generazione di lunghe sequenze di testo
In tanti articoli abbiamo detto che creare un prompt ben fatto è la chiave di volta per ottenere risposte argomentate, contestualizzate e pertinenti da parte dei LLM.
Immaginate un’ipotetica funzione Python che prenda in input una frase fornita dell’utente (il prompt). Quello che il modello fa, innanzi tutto, è tokenizzare il prompt quindi generare una sequenza di valori numerici univoci (l’abbiamo visto prima con encoding.encode).
A questo punto, a seconda della lunghezza del testo che si vuole ottenere in output, fa una serie di previsioni sui token più probabili per completare la sequenza di token in input. Avete notato come gli LLM riutilizzino buona parte dell’input fornito dall’utente nella composizione dalla risposta?
La funzione Python della quale stiamo parlando potrebbe selezionare semplicemente i token con la probabilità più alta di seguire un altro token. Questo approccio è chiamato, in inglese, greedy selection. Utilizzando un generatore di numeri pseudocasuali, tuttavia, è possibile rendere il meccanismo più “dinamico”: anziché scegliere sempre i token più probabili, se ne può selezionare casualmente uno tra quelli che – in termini di probabilità – superano una certa soglia.
Adesso avete capito perché, fornendo uno stesso prompt a un modello generativo in più momenti diversi, questo di solito fornisce risposte a volte molto differenti l’una rispetto all’altra.
La temperatura nei LLM
Nell’ambito dei LLM, la temperatura è un parametro utilizzato nella generazione del testo che controlla quanto “creativo” o “conservativo” deve essere l’output.
Più nello specifico, la temperatura regola la distribuzione di probabilità delle parole generate dal modello. A una temperatura più alta, il modello è più propenso a produrre risultati creativi e sorprendenti, poiché distribuisce la probabilità in modo più uniforme tra le diverse parole nel suo vocabolario. Al contrario, a una temperatura più bassa, il modello genera risultati più conservativi e coerenti, poiché si affida alle parole più probabili in assoluto (concetto di greedy selection).
Nelle impostazioni avanzate di alcuni LLM potreste aver trovato dei riferimenti ai cosiddetti iperparametri top_p e top_k: controllano quanti dei token più probabili vengono considerati per la selezione.
Una volta scelto un token con l’approccio descritto in precedenza, il ciclo si ripete. La funzione descritta in precedenza è cioè di nuovo richiamata passando un input arricchito con il nuovo token. Si genera così un ulteriore token che segue quello appena “accodato” e così via. Il processo continua.
I LLM non hanno il concetto di frasi e paragrafi, perché – come abbiamo visto – lavorano su un token per volta. Per evitare che il testo generato sia troncato a metà frase, il codice può essere impostato in modo da interrompere il ciclo quando viene generato il token corrispondente a un punto.
Come funziona l’addestramento dei LLM
Semplificando al massimo, supponiamo di utilizzare un LLM che si serva di un vocabolario composto da appena 8 parole in italiano: “il”, “cane”, “gatto”, “mangia”, “beve”, “latte”, “carne”, “pane”.
Supponiamo che a ogni parola corrisponda un singolo token. Ipotizziamo, inoltre, di avere un set di sole 3 frasi di addestramento:
“Il cane mangia carne”
“Il gatto beve il latte”
“Il cane mangia il pane”
Il modello LLM impara a prevedere la probabilità di ogni token in base al contesto delle frasi di addestramento. Crea quindi una tabella, in questo caso 8×8, che conta le occorrenze dei token. In particolare, il LLM scrive in ogni cella quante volte il token indicato in ciascuna riga è seguito dal token riportato nell’intestazione della colonna. Si tenga presente che, sempre per semplicità, non stiamo facendo differenza tra “Il” (con la lettera maiuscola”) e “il” (con la lettera minuscola).
| il | cane | gatto | mangia | beve | latte | carne | pane | |
|---|---|---|---|---|---|---|---|---|
| il | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 1 |
| cane | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
| gatto | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| mangia | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| beve | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| latte | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| carne | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| pane | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Queste occorrenze, derivate dai dati di addestramento, possono essere ovviamente trasformate in probabilità. Probabilità che un token segua un altro token in una frase.
Le dimensioni della finestra di contesto
Il problema di questo approccio, detto catena di Markov, è che considera solo l’ultimo token dell’input. Qualsiasi testo che appare prima dell’ultimo token elaborato, non ha alcuna influenza sulla scelta dei token successivi. La cosiddetta finestra di contesto (context window), quindi, è in questo uguale a un solo token.
Un approccio del genere è pressoché inutile perché il modello salta da una parola all’altra, selezionando nuovi token senza avere alcuna “memoria” dei token elaborati in precedenza. Il risultato è ovvio: il contesto del prompt non può essere in alcun modo conservato.
Per migliorare le previsioni, si deve quindi costruire una tabella delle probabilità di dimensioni maggiori. Si supponga di usare una finestra di contesto formata da due token. Limitandoci agli 8 token usati nell’esempio del paragrafo precedente, alla tabella andrebbero aggiunte 64 nuove righe, al di sotto delle 8 già presenti. Il modello dovrebbe essere quindi nuovamente addestrato.
Anche con una finestra di contesto da due token, tuttavia, è impossibile che i token via via aggiunti si riferiscano a concetti e idee espressi dai token precedenti.
L’ormai superato modello open source GPT-2 di OpenAI, utilizza una finestra di contesto di 1024 token. Per poter implementare una finestra di contesto di queste dimensioni utilizzando le catene di Markov, ciascuna riga della tabella delle probabilità dovrebbe rappresentare una sequenza compresa tra 1 e 1024 token.
Ciò significa che limitandosi al ristretto vocabolario di 8 token/parole visto in precedenza, ci sono ben 81024 possibili sequenze lunghe 1024 token. Le righe della tabella necessarie per rappresentare tutte le possibili probabilità sono quindi 81024:
5809605995369958062859502533304574370686975176362895236661486152287203730997110225737336044533118407251326157754980517443990529594540047121662885672187032401032111639706440498844049850989051627200244765807041812394729680540024104827976584369381522292361208779044769892743225751738076979568811309579125511333093243519553784816306381580161860200247492568448150242515304449577187604136428738580990172551573934146255830366405915000869643732053218566832545291107903722831634138599586406690325959725187447169059540805012310209639011750748760017095360734234945757416272994856013308616958529958304677637019181594088528345061285863898271763457294883546638879554311615446446330199254382340016292057090751175533888161918987295591531536698701292267685465517437915790823154844634780260102891718032495396075041899485513811126977307478969074857043710716150121315922024556759241239013152919710956468406379442914941614357107914462567329693696
Un numero davvero folle! Se si pensa che con GPT-3, la finestra di contesto è stata portata a 2048 token, con GPT-3.5 a 4096 token e con GPT-4 si è arrivati, con diversi successivi “aggiornamenti”, a qualcosa come 128000 token, appare chiaro come le catene di Markov non siano l’approccio migliore.
Tra l’altro, i modelli più moderni stanno iniziando a utilizzare finestre di contesto della dimensione di oltre 1 milione di token. Pensate quindi al numero di righe di una tabella che si otterrebbero specificando come base (a) il numero delle parole del vocabolario e come esponente (b) la dimensione della finestra di contesto: ab.
Dalla tabella delle probabilità alle reti neurali
Gestire una tabella delle probabilità delle dimensioni di quelle descritte in precedenza, soprattutto con i modelli contraddistinti da finestre di contesto particolarmente ampie, richiederebbe una quantità di memoria RAM impressionante. Ecco quindi che accorrono in soccorso le reti neurali.
Una rete neurale può essere pensata come una funzione che approssima le probabilità dei vari token utilizzando un insieme di parametri, più o meno vasto.
I parametri in una rete neurale al servizio di un LLM si riferiscono alle informazioni che la rete neurale stessa impara durante il processo di addestramento. Questi parametri includono i pesi delle connessioni tra i neuroni e i bias di ciascun neurone in ogni strato della rete.
Pesi? Neuroni? Bias? Troppi concetti tutti insieme. Cerchiamo di fare un po’ di chiarezza.
Cosa sono i parametri e i pesi delle connessioni tra i neuroni
Abbiamo detto che i “parametri” si riferiscono alle variabili interne del modello, apprese durante il processo di addestramento. Si tratta di informazioni essenziali per definire il comportamento della rete neurale nel processare i dati in ingresso e generare output.
Le reti neurali sono composte da unità computazionali chiamate neuroni, organizzati in strati (ne parliamo più avanti). Ogni connessione tra neuroni ha un “peso” associato, che indica l’importanza della connessione. Durante l’addestramento, questi pesi sono regolati in modo che la rete possa imparare a rappresentare le relazioni complesse osservate nei dati di input.
Oltre ai pesi delle connessioni, ogni neurone ha un “bias” associato. Il bias rappresenta la soglia di attivazione del neurone: se la somma pesata dei segnali in ingresso supera il valore di bias, il neurone è attivato. Ad esempio, in una rete neurale per la classificazione dei testi, i bias aiutano a determinare quando un certo neurone dovrebbe attivarsi in risposta a determinate parole o caratteristiche linguistiche.
GPT-2 ha circa 1,5 miliardi di parametri, con GPT-3 gli ingegneri di OpenAI hanno portato il conteggio a 175 miliardi di parametri. Nel caso di GPT-4, pur in mancanza di una conferma ufficiale, il numero di parametri dovrebbe essere equivalente a circa 1,76 trillion (1760 miliardi).
Nel contesto di un LLM, i parametri sono fondamentali per rappresentare il modello linguistico e la “conoscenza” acquisita durante l’addestramento. Ad esempio, i pesi delle connessioni riflettono le relazioni semantiche e sintattiche tra le parole, mentre i bias – come detto – influenzano l’attivazione dei neuroni durante il processo di elaborazione del linguaggio.
Ottimizzare il processo di addestramento della rete neurale
Il processo di addestramento della rete neurale consiste nell’individuare i parametri utili a fare in modo che la funzione operi al meglio quando valutata sui dati contenuti nel set di addestramento. Se la funzione si comporta bene con i dati di addestramento, lo farà anche su altri dati, ad esempio con quelli mai visti in precedenza.
Durante l’addestramento di una rete neurale, i parametri sono regolati attraverso un algoritmo di ottimizzazione. Uno dei metodi più comuni utilizzati in questo senso è il processo di backpropagation, che può essere suddiviso in diverse fasi:
- Forward Pass: Durante questa fase, i dati di input vengono forniti alla rete neurale e vengono calcolate le previsioni. Queste previsioni sono confrontate con valori target per calcolare la perdita, una misura della discrepanza tra le predizioni del modello e i valori attesi.
- Backward Pass (retropropagazione): Una volta calcolata la perdita, l’algoritmo di backpropagation elabora i gradienti della perdita. Essi forniscono informazioni su come i parametri della rete dovrebbero essere aggiornati per migliorare le prestazioni del modello. Se il gradiente rispetto a un certo parametro è positivo, significa che un aumento del parametro aumenterebbe la perdita, mentre se è negativo, significa che un aumento del parametro diminuirebbe la perdita.
- Aggiornamento dei parametri: Dopo aver calcolato i gradienti, l’algoritmo di ottimizzazione è utilizzato per aggiornare i valori dei parametri. L’aggiornamento dei parametri avviene tipicamente in base al gradiente della funzione di perdita rispetto ai parametri stessi.
- Iterazione: I passaggi sin qui descritti sono ripetuti iterativamente per l’intero set di dati di addestramento. L’obiettivo è ridurre gradualmente la perdita sulla totalità dei dati di addestramento, migliorando così le capacità predittive della rete neurale.
Strati, Transformer e attenzione
Una rete neurale è configurata per eseguire una catena di operazioni, ciascuna chiamata strato (o livello). Il primo strato riceve l’input ed esegue su di esso un qualche tipo di trasformazione. Gli input trasformati sono passati allo strato seguente ed elaborati ancora una volta. Ciò continua finché i dati non raggiungono lo strato finale e sono trasformati un’ultima volta, generando l’output o la previsione.
L’architettura di rete neurale oggi più popolare per la generazione di testo con i moderni modelli linguistici si chiama Transformer, presentata nel 2017 da un gruppo di ingegneri Google.
La caratteristica distintiva dei LLM basati su Transformer è un’elaborazione a strati eseguita utilizzando il meccanismo dell’attenzione. Protagonista di un altro nostro articolo, l’attenzione consente di derivare relazioni e modelli tra i token presenti nella finestra di contesto, che si riflettono – in termini probabilistici – sulla generazione dei token successivi.
Al cuore del meccanismo di attenzione vi è la capacità del modello di focalizzarsi su parti specifiche dell’input durante il processo di generazione del testo o nel corso dell’elaborazione di compiti linguistici. Il processo è cruciale per garantire che il modello sia in grado di dare maggiore rilevanza a certe parole o parti del testo in base al contesto.
L’input o prompt fornito al LLM basato su Transformer, è suddiviso – come abbiamo visto anche inizialmente – in una sequenza di token, che possono essere parole, sottoinsiemi di parole o simboli. Ogni token in input è quindi espresso usando tre spazi di rappresentazione distinti: Query (Q), Key (K) e Value (V). Queste proiezioni consentono al modello di rappresentare in modo distinto il significato del token (Q), la sua relazione con altri token (K) e l’informazione contenuta nel token stesso (V).
I “punteggi di attivazione” sono valori numerici che rappresentano la rilevanza di una determinata chiave (Key) rispetto a una specifica query (Query). Attraverso il confronto di ogni coppia, i punteggi di attivazione permettono di stabilire quanto peso dare a ciascun valore V corrispondente.
Utilizzando i pesi calcolati, il modello calcola quindi una combinazione pesata dei valori (V) corrispondenti alle chiavi (K) rilevanti per ciascuna query (Q). Questa combinazione pesata costituisce l’attenzione che il modello presta a ciascun elemento dell’input.
Come ultimo passo, i “valori attenzionati” sono aggregati per produrre una rappresentazione contestuale dell’input, che tiene conto dell’attenzione del modello su parti specifiche del prompt stesso. Ed è così che i migliori LLM possono generare output linguistici coerenti e significativi.
Credit immagine in apertura: iStock.com – Olemedia
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475262_1744723681.jpeg "Apple vuole migliorare l'AI con i dati delle nostre email")
/https://www.ilsoftware.it/app/uploads/2025/04/flux_image_475214_1744719949.jpeg "L'AI sta sostituendo il personale qualificato delle centrali nucleari")
/https://www.ilsoftware.it/app/uploads/2025/01/1-25.jpg "Grok potrebbe presto avere una memoria a lungo termine (e non solo)")
/https://www.ilsoftware.it/app/uploads/2025/04/wp_drafter_475220.jpg "AI per comunicare con i delfini: partnership tra Google e Wild Dolphin Project")