
I documenti in formato PDF sono spesso utilizzati anche come semplici “contenitori” di immagini acquisite tramite scanner. Tante applicazioni permettono di creare file PDF multipagina: ogni pagina corrisponde a un foglio cartaceo precedentemente acquisito in digitale. Tante volte, però, si riscontrano notevoli difficoltà nel copiare testo da un PDF.
Se, aprendo un documento PDF, non riuscite a selezionare e copiare il testo altrove (CTRL+C, CTRL+V), di solito significa che nel file sono presenti esclusivamente immagini. Annotate una qualunque parola che compare nel file, quindi premete la combinazione di tasti CTRL+F. Se, digitando la stessa parola nella casella di ricerca, non otteneste alcuna occorrenza (zero risultati), avrete un’ulteriore conferma circa l’assenza di testo ricercabile all’interno del documento PDF.
Come riconoscere il testo nel documento PDF usando l’OCR
Esistono molte soluzioni per affrontare il problema di dover cercare o copiare testo da un documento PDF scannerizzato. Una delle migliori, più semplici da usare e a costo zero consiste nel ricorrere all’applicazione open source OCRmyPDF.
Si tratta di uno strumento progettato per aggiungere uno strato di testo ai file PDF che ospitano soltanto delle immagini, usando la funzionalità OCR (riconoscimento ottico dei caratteri).
OCRmyPDF è uno strumento potente e flessibile che risolve uno dei problemi comuni relativi ai file PDF generati a partire da documenti scannerizzati. La sua funzione principale è quella di produrre un file PDF/A ricercabile a partire da un normale PDF, consentendo agli utenti di effettuare ricerche nel documento nonché di copiare e incollare il testo in altri contesti.
Il software OCRmyPDF posiziona con precisione il testo riconosciuto al di sotto dell’immagine originale, semplificando l’operazione di copia e incolla. Conserva inoltre l’esatta risoluzione delle immagini incorporate nel documento originale e può eventualmente correggere, su richiesta, l’inclinazione delle immagini (deskewing) prima di effettuare l’operazione OCR.
OCRmyPDF consente inoltre di ottimizzare le immagini PDF, spesso producendo file più piccoli rispetto al documento fornito in input.
Dal punto di vista delle prestazioni, l’applicazione distribuisce efficientemente il lavoro di elaborazione del PDF suddividendo i compiti tra tutti i core disponibili sulla CPU. In questo modo, OCRmyPDF può ridurre i tempi di gestione dei documenti più pesanti composti da un gran numero di pagine (abbiamo verificato che i risultati sono eccellenti anche con documenti composti da migliaia di pagine).
I passaggi per installare OCRmyPDF
Un software come OCRmyPDF nasce come applicazione destinata in primis ai sistemi GNU/Linux. Tuttavia, si tratta di un’utilità facilissima da usare anche in Windows 10 e in Windows 11.
Il programma è sprovvisto di interfaccia grafica e funziona esclusivamente da riga di comando. A dispetto di ciò, tutto resta davvero semplice e abbordabile per qualunque utente.
Di seguito l’elenco dei comandi utilizzabili sulle varie distribuzioni Linux per installare OCRmyPDF con i vari package manager disponibili:
| Sistema operativo | Comando installazione |
|---|---|
| Debian, Ubuntu | apt install ocrmypdf |
| Windows Subsystem for Linux | apt install ocrmypdf |
| Fedora | dnf install ocrmypdf |
| macOS (Homebrew) | brew install ocrmypdf |
| macOS (nix) | nix-env -i ocrmypdf |
| LinuxBrew | brew install ocrmypdf |
| FreeBSD | pkg install py-ocrmypdf |
| Conda | conda install ocrmypdf |
| Ubuntu Snap | snap install ocrmypdf |
Nella tabella vedete specificato anche Windows Subsystem for Linux (WSL): sì, perché installando ad esempio Ubuntu in Windows 10 e Windows 11 quindi eseguendolo in finestra con WSL, si può comunque sottoporre a OCR il contenuto PDF e ottenere un nuovo file.
Come usare OCRmyPDF in Windows con WSL
Supponendo di eseguire Linux in Windows con WSL e ipotizzando di aver già installato con successo Ubuntu 22.04 (wsl --install -d Ubuntu-22.04 al prompt dei comandi aperto con i diritti di amministratore), è possibile installare OCRmyPDF con una singola istruzione:
sudo apt install ocrmypdf -y
A questo punto è tutto pronto: premendo Windows+R quindi digitando \\WSL$ e premendo Invio, si accede al file system di Ubuntu. Cliccando due volte sulla risorsa Ubuntu-22.04 quindi sulla cartella home e infine sul nome utente configurato in Linux, si può copiare il file PDF da elaborare (quello contenente le scansioni da pagine cartacee).
Nella finestra di WSL, si può quindi digitare il comando che segue:
ocrmypdf input.pdf output.pdf
Al posto di input.pdf va indicato il nome del file PDF originale, appena copiato nel file system di Ubuntu. La stringa output.pdf va invece sostituita con il nome del documento che si desidera ottenere. Aggiungendo eventualmente anche l’opzione --skip-text, OCRmyPDF ignora le pagine che contengono già del testo, concentrandosi invece su quelle che presentano esclusivamente immagini. L’opzione è utile per tutti quei documenti “misti” che uniscono contenuti creati in digitale e copie di pagine stampate acquisite con lo scanner o mediante foto.
È inoltre adatta per “normalizzare” i PDF e convertirli nel formato PDF/A, indipendentemente dalla loro tipologia e dai contenuti che ospitano:
ocrmypdf --skip-text input.pdf output.pdf
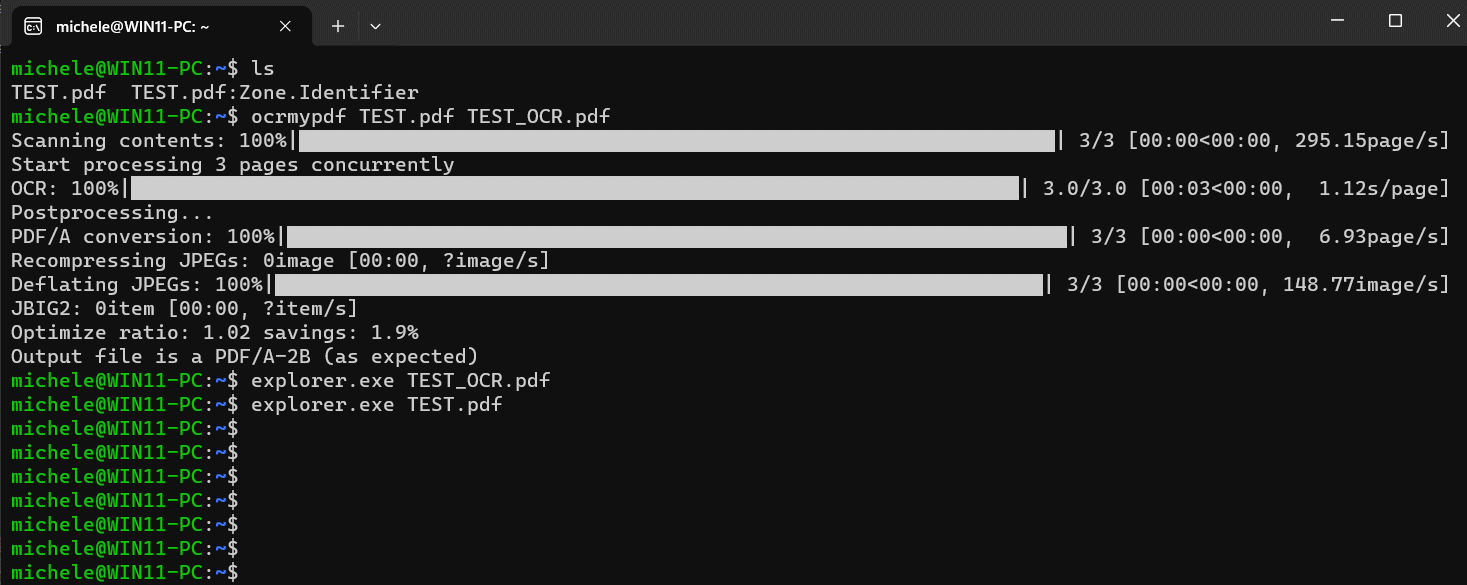
Il seguente comando effettua l’OCR sul file PDF di input specificato, crea un nuovo PDF con riconoscimento delle lingue inglese e italiana, correggendo eventuali inclinazioni imperfette delle immagini (cosa piuttosto comune con le pagine acquisite mediante scanner):
ocrmypdf input.pdf output.pdf --language eng+ita --deskew
OCRmyPDF si presenta come uno strumento essenziale per chiunque lavori con documenti scannerizzati in formato PDF. Con le sue numerose funzionalità e la capacità di gestire grandi volumi di pagine, rende immediatamente effettuabile la selezione del testo e la successiva operazione di copia e incolla.
Il file output.pdf creato nella cartella principale dell’utente Ubuntu, può essere facilmente copiato altrove usando Esplora file.
Ulteriori informazioni sulla sintassi avanzata di OCRmyPDF sono disponibili nel Cookbook, che vi invitiamo a consultare.
Credit immagine in apertura: iStock.com – monticelllo
/https://www.ilsoftware.it/app/uploads/2023/06/blocco-outlook-microsoft-365.jpg "Microsoft ammette: bug Outlook causa problemi con CPU")
/https://www.ilsoftware.it/app/uploads/2025/04/office-2016-crash-patch.jpg "Crash Office 2016: Microsoft rilascia un aggiornamento di emergenza")
/https://www.ilsoftware.it/app/uploads/2025/02/installazione-office-microsoft-365-gratuito.jpg "Ecco come sono le nuove icone delle app di Microsoft Office")
/https://www.ilsoftware.it/app/uploads/2025/03/startup-boost-precaricamento-office.jpg "La moda dell'Avvio rapido contagia anche Microsoft Office")