/https://www.ilsoftware.it/app/uploads/2024/04/attenzione-modelli-IA-significato.jpg "Attenzione, i segreti del meccanismo che fa funzionare le intelligenze artificiali")
Nell’ambito dell’intelligenza artificiale (IA), il concetto di Transformer – presentato da un gruppo di ingegneri Google nel 2017 – ha letteralmente rivoluzionato il panorama dei modelli generativi. Questi modelli, alla base del funzionamento di sofisticati chatbot come ChatGPT, si basano su un concetto chiave: l’attenzione (attention).
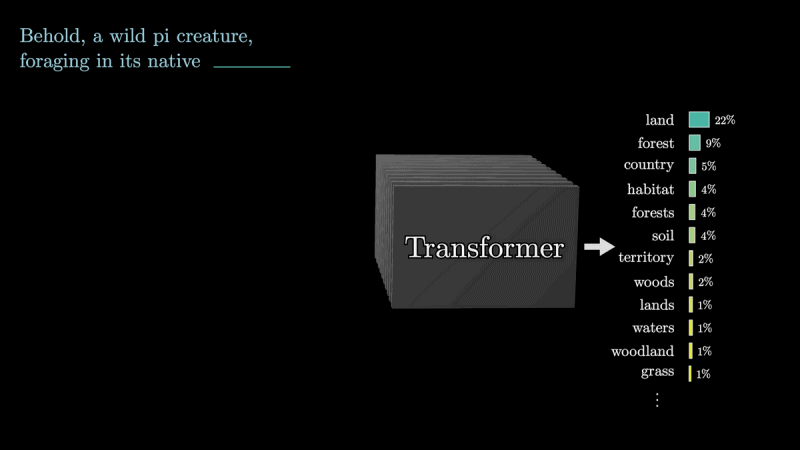
I moderni Large Language Models (LLM) svolgono un compito fondamentale: leggono una frase e cercano prevedere la parola successiva. Questo processo coinvolge la suddivisione delle frasi in unità chiamate token e l’elaborazione di questi token tramite modelli linguistici. I Transformer, in particolare, protagonisti dello storico documento “Attention Is All You Need” si distinguono per la loro capacità di tenere in debita considerazione il contesto nella rappresentazione di ciascun token, proprio grazie al concetto di “attenzione”.
Come funziona l’attenzione nei modelli generativi che governano le intelligenze artificiali
3Blue1Brown ha pubblicato una videoguida che illustra, passo dopo passo, il meccanismo di attenzione spiegando come sia responsabile del corretto funzionamento dei moderni modelli generativi e permetta di ottenere frasi di qualità in risposta a qualunque genere di input.
Come abbiamo evidenziato in precedenza, una frase è suddivisa in più unità chiamate token: i LLM si occupano di elaborare queste unità. In realtà un token non corrisponde esattamente a una singola parola ma nel video, per rendere le cose più semplici, si offre questa visione approssimativa.
L’embedding rappresenta il primo passo nell’elaborazione di un token. Questo processo associa a ciascun token un vettore multidimensionale: questi vettori riflettono le associazioni semantiche, consentendo al modello di comprendere le relazioni tra le parole.

Grazie alla loro natura, i vettori aiutano ad estrarre il significato intrinseco delle parole (ne parliamo anche nell’articolo dedicato alle Vector Search Oracle). Tuttavia, il significato di una parola può variare a seconda del contesto, rendendo necessaria l’attenzione per adeguare l’embedding alle varie situazioni specifiche.
Ruolo dell’attenzione nelle attività di embedding
Osservando lo spazio vettoriale, si scoprirà ovviamente che parole dal significato “compatibile” (semanticamente simili), come ad esempio “figlia-figlio” e “donna-uomo“, sono caratterizzate da vettori molto simili.
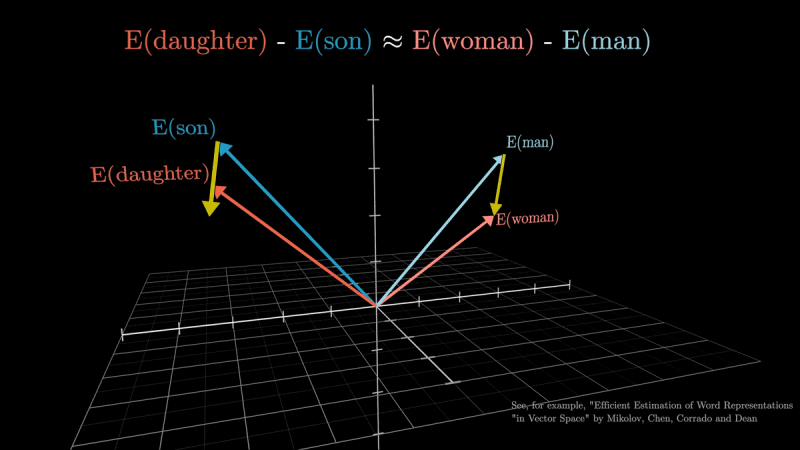
L’attenzione consente di calcolare quanto sono “rilevanti” i token vicini (si pensi alle parole che compongono una frase) regolando gli embedding di conseguenza. Grazie all’attenzione, quindi, il modello generativo può discernere tra significati diversi di una stessa parola o di parole accoppiate insieme ad altre, come ad esempio “torre” e “Torre Eiffel“.
Nei Transformer, l’attenzione è calcolata mediante una serie di passaggi. Per una stessa singola parola, quindi, l’attenzione permette di generare un vettore appropriato in base al contesto circostante. In alcuni casi, l’attenzione può derivare il significato più pertinente da parole piuttosto lontane, oppure può accontentarsi dei vettori che caratterizzano token vicini.

Dopo che un gran numero di vettori sono fatti transitare attraverso una rete contenente diversi blocchi di attenzione, l’ultimo passo provvede a “predire la parola successiva”.
Il concetto di peso
Nei meccanismi di attenzione, il concetto di “peso” è fondamentale. I pesi sono utilizzati per determinare quanto una certa parte dell’input (il prompt fornito dall’utente) sia rilevante rispetto alla produzione dell’output.
Immaginate di avere una frase in input e di voler generare il testo da fornire all’utente come risposta. Quest’operazione si snoda attraverso la successiva generazione di una serie di parole, l’una dopo l’altra. Per fare ciò, il modello deve decidere su quali parti della frase concentrare la sua “attenzione”, ovvero a quali parole/token dare più importanza per generare correttamente la parola successiva.
I pesi dell’attenzione indicano proprio quanto peso dare a ciascuna parola fornita in input. Questi pesi sono calcolati mediante funzioni di scoring, che valutano la rilevanza di ciascuna parola rispetto alla parola successiva da generare. Le parole che sono più rilevanti per la generazione della parola successiva saranno contraddistinte da pesi più alti, mentre quelle meno rilevanti da pesi più bassi.
L’attenzione single-headed e multi-headed
La “single-headed attention” e la “multi-headed attention” sono varianti del meccanismo di attenzione. Nel primo caso, il modello usa un singolo meccanismo di attenzione per calcolare i pesi tra le parole in ingresso e le parole da generare in uscita. Questo approccio ha il vantaggio della semplicità, ma può limitare la capacità del modello di catturare relazioni complesse tra le parole.
La multi-headed attention, viceversa, si focalizza su diverse parti del testo in input. Ciascun output è poi concatenato e combinato per formare una rappresentazione più ricca e completa. Si tratta di uno schema decisamente più potente perché consente al modello di considerare le relazioni tra le parole da molteplici prospettive, migliorando la capacità del modello di catturare informazioni significative.
In generale, i vettori sono utilizzati per rappresentare sia l’input che l’output nei modelli generativi e sono fondamentali per il calcolo dei pesi dell’attenzione, che determinano quale input è rilevante per una data uscita.
I pesi dell’attenzione consentono al modello di focalizzarsi sulle parti più importanti dell’input per il compito di generazione. Il processo di assegnazione dei pesi è guidato dall’apprendimento durante la fase di training del modello: è in questa (onerosa) fase iniziale che il modello impara a determinare automaticamente quali parti dell’input sono più rilevanti per la produzione dell’output desiderato.
In conclusione, l’attenzione rappresenta il cuore dei moderni modelli generativi basati sui Transformer. Il meccanismo consente al modello di “comprendere” e generare testi coerenti e contestualmente rilevanti. L’utilizzo dell’attenzione è fondamentale per lo sviluppo di intelligenze artificiali sempre più sofisticate e “contestualmente consapevoli“.
Le immagini nell’articolo sono tratte dal video di 3Blue1Brown. Credit immagine in apertura: iStock.com – Userba011d64_201
/https://www.ilsoftware.it/app/uploads/2023/09/1-110.jpg "Accordo OpenAI e The Washington Post: ChatGPT integra contenuti dal giornale")
/https://www.ilsoftware.it/app/uploads/2025/01/1-25.jpg "Grok Vision di xAI introduce l'interazione con il mondo reale")
/https://www.ilsoftware.it/app/uploads/2023/08/Conto-corrente.jpg "ChatGPT evolve: presto acquisti diretti grazie a Shopify")
/https://www.ilsoftware.it/app/uploads/2024/09/1-8.jpg "Meta: AI usata per individuare account di minorenni su Instagram")