/https://www.ilsoftware.it/app/uploads/2023/05/img_24228.jpg "Filamenti di DNA per leggere e scrivere dati: ampliato l'alfabeto per ottenere possibilità di storage infinite")
Da anni si parla dei possibili utilizzi di filamenti di DNA come strumenti per la memorizzazione dei dati. L’obiettivo consiste nell’affiancare alle memorie flash e ai supporti magnetici dei quali si fa ampio uso oggigiorno materiale biologico trattando il DNA come qualsiasi altro dispositivo per la memorizzazione digitale.
Il DNA codifica l’informazione genetica con quattro molecole chiamate nucleotidi: adenina, guanina, citosina e timina (A, G, C e T). Sintetizzando filamenti di DNA che immagazzinano 96 bit, dove ciascuna delle basi (A, G, C e T) rappresenta un valore binario (T e G = 1, A e C = 0) si ha la possibilità di gestire enormi quantitativi di dati sfruttando l’incredibile densità del DNA e della sua capacità di sopravvivere inalterato per migliaia di anni (si è visto che non subisce modifiche da quando è nata la vita sulla Terra).
È inoltre sufficiente tenere in considerazione che un solo grammo di DNA sarebbe in grado di conservare fino a 215 Petabyte di dati per almeno 2.000 anni; le informazioni conservate da un intero data center, insomma, potrebbero essere stivate in un oggetto delle dimensioni paragonabili a quelle di un cubetto di zucchero.
Per leggere le informazioni memorizzate nel DNA è sufficiente sequenziarlo – come si farebbe con un genoma umano – e convertire ciascuna delle basi in binario.
Nel 2019 avevamo parlato del traguardo raggiunto da Microsoft i cui tecnici erano riusciti ad automatizzare il processo di scrittura dei dati nel DNA.
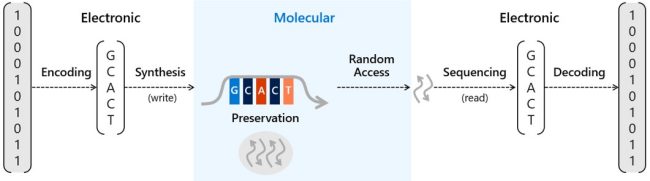
Fonte dell’immagine: Microsoft.
Adesso un gruppo di ricercatori del Beckman Institute, unità dell’Università dell’Illinois dedicata alla ricerca interdisciplinare, ha spiegato di aver esteso artificialmente l'”alfabeto” utilizzato nella memorizzazione del DNA con l’obiettivo di aumentarne ulteriormente le capacità di storage dei dati. Invece di convertire zero e uno solo nelle basi A, G, C e T, il nuovo alfabeto mira a offrire un supporto di archiviazione digitale potenzialmente illimitato.
I ricercatori hanno anche coniato un nuovo meccanismo che legge accuratamente i dati dal DNA sintetizzato: il sistema utilizza algoritmi di deep learning e l’intelligenza artificiale per discernere tra le sette lettere artificiali del DNA aggiunte dall’uomo e quelle utilizzate in natura. “Abbiamo provato 77 diverse combinazioni degli 11 nucleotidi e il nostro metodo è stato in grado di differenziarle perfettamente“, spiegano gli accademici.
Lo stoccaggio di dati usando filamenti di DNA è una delle tecniche più audaci per superare i limiti che ci vincolano oggi ma passeranno ancora decenni prima che possa diventare una valida opzione.
Tradurre i bit in configurazioni di DNA sintetizzato non è affatto semplice: sia la scrittura che la successiva lettura delle informazioni in forma digitale richiedono ad oggi molto tempo e apparecchiature costose.
/https://www.ilsoftware.it/app/uploads/2025/10/backup-whatsapp-passkey.jpg "Backup WhatsApp protetti con passkey: cosa cambia davvero?")
/https://www.ilsoftware.it/app/uploads/2025/10/truenas-25-10-novita-storage-professionale-dati.jpg "TrueNAS 25.10, soluzione per lo storage professionale abbraccia NVMe over Fabric")
/https://www.ilsoftware.it/app/uploads/2025/10/QNAP-Virtualization-Station-lancio.jpg "QNAP Virtualization Station 4.1: VM ad Alta Disponibilità per NAS senza downtime")
/https://www.ilsoftware.it/app/uploads/2025/06/perdita-dati-microsoft-onedrive-blocco-account.jpg "30 anni di dati persi: cosa succede se Microsoft ti blocca l'account")