/https://www.ilsoftware.it/app/uploads/2024/05/chatbot-locale-browser-secret-llama.jpg "Fantastico Secret Llama: come chattare con i modelli generativi da browser Web")
Quando si usano i chatbot disponibili sul Web c’è sempre un trasferimento dati tra il client dell’utente e i server del fornitore del servizio. Si pensi ad esempio a ChatGPT: non solo il modello generativo (GPT, Generative pre-trained transformer) è in esecuzione sui server di OpenAI ma l’azienda guidata da Sam Altman può utilizzare i prompt, ovvero le informazioni fornite dagli utenti in input, per migliorare il modello. L’autorizzazione a usare i dati conferiti dall’utente per l’addestramento continuo del modello può essere eventualmente revocata agendo sulle impostazioni di ChatGPT.
Secret Llama, un chatbot intelligente che permette di usare i principali modelli generativi senza scaricare nulla
È di questi giorni la presentazione di Secret Llama, un innovativo progetto che consente l’utilizzo di modelli generativi come TinyLlama, Llama 3, Mistral 7B e Phi 1.5 direttamente da browser Web. Il principale vantaggio è che non è necessario utilizzare alcun server né una macchina dedicata allo scopo: il chatbot Secret Llama si appoggia interamente al browser dell’utente, pur necessitando – come requisiti imprescindibili – Chrome/Edge e una scheda video discreta (non basta la GPU eventualmente integrata a livello di processore).
Progetto open source, condiviso su GitHub, Secret Llama nasce a valle della pubblicazione di Web LLM. Web LLM è un pacchetto JavaScript modulare e personalizzabile che porta direttamente i modelli di linguaggio per le chat sui browser Web, sfruttando l’accelerazione hardware. Tutto è eseguito all’interno del browser e i workload sono sostenuti dalla libreria WebGPU, un’API a basso livello che consente alle applicazioni in esecuzione nel browser di “parlare” con la GPU presente sul sistema in uso.
Web LLM è completamente compatibile con l’API di OpenAI. Ciò significa che per dialogare con qualunque modello open source in locale, è possibile utilizzare la stessa “sintassi” adottata per inviare richieste ai modelli GPT di OpenAI.
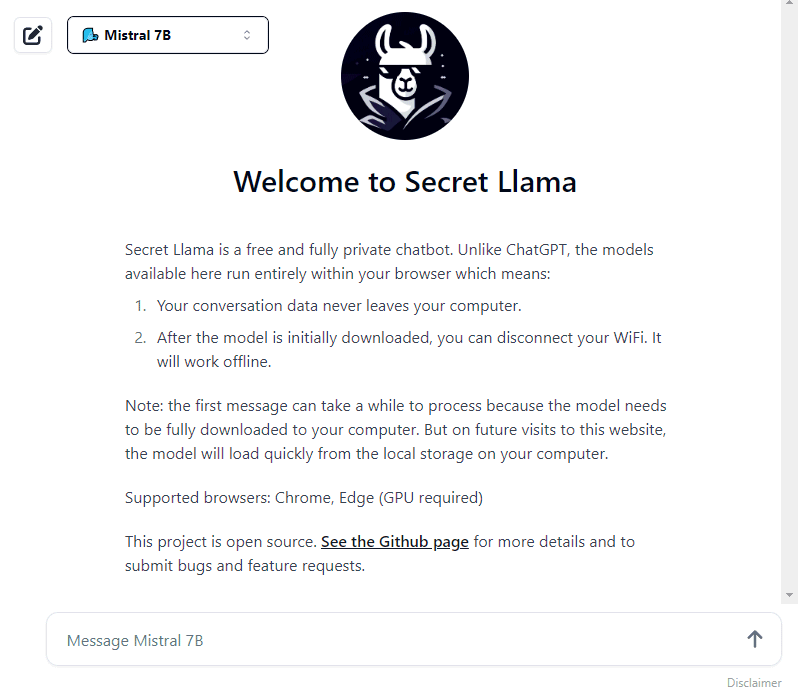
Le principali caratteristiche di Secret Llama
Oltre al fatto che non sono necessarie macchine dedicate, Secret Llama vanta un altro importante fiore all’occhiello: nessun dato dell’utente e nessuna informazione relativa alle conversazioni lascia mai il computer. Questo perché Secret Llama provvede a scaricare il modello generativo scelto “una tantum”, per rispondere al quesito inserito, poi utilizza sempre la copia memorizzata in locale. Non è quindi necessario inviare un singolo bit verso server remoti.
La “prova del nove” è molto semplice: dopo aver lasciato scaricare il modello a Secret Llama (verranno mostrati i messaggi Loading model e Fetching param cache), si può disconnettere il computer dalla rete Internet. Vedrete che anche in modalità offline, l’intelligenza artificiale continuerà a rispondere alle richieste; proprio perché il modello generativo è conservato in locale e interrogato in tempo reale tramite Web LLM.
Infine, Secret Llama è contraddistinto da un’interfaccia semplicissima da usare: in basso c’è il classico riquadro per l’inserimento dell’input da inviare al chatbot; con il pulsante in alto a destra si può avviare una nuova chat; il menu a tendina sulla destra permette di scegliere il LLM (Large Language Model) preferito.
Ovviamente, i modelli più “snelli” come TinyLlama e Phi 1.5 – soprattutto nell’elaborazione delle chat in italiano – tendono a offrire risultati meno attendibili, pertinenti e argomentati. È possibile confrontare gli output ottenuti con quelli prodotti da modelli con un maggior numero di parametri, come Mistral 7B e Llama 3.
Come usare il chatbot nel browser Web
Iniziare ad utilizzare Secret Llama è semplice tanto quanto collegarsi con la home page del progetto e iniziare a digitare un quesito, utilizzando il linguaggio naturale, nel campo Message in basso. Come osservato in precedenza, dapprima Secret Llama disporrà il download del modello e lo porrà nella cache locale del browser.
Nel caso di alcuni modelli, potrebbe essere necessario avviare l’eseguibile del browser Web con un’opzione aggiuntiva: Secret Llama riporta chiaramente la sintassi da usare.
Le operazioni di download e caching dei LLM di dimensioni maggiori sono ovviamente piuttosto onerose e possono richiedere più tempo. Anche chiudendo la scheda di Secret Llama nel browser, per poi riaprirla successivamente, non si dovrà nuovamente effettuare il download del modello.
A questo punto, completata la fase di inizializzazione, è possibile conversare con il chatbot come si farebbe con ChatGPT o con qualsiasi prodotto analogo.
Gli sviluppatori possono anche ricompilare il progetto Secret Llama a partire dal codice React. Le indicazioni per procedere in tal senso sono riportate in questa guida.
Credit immagine in apertura: iStock.com – BlackJack3D
/https://www.ilsoftware.it/app/uploads/2024/06/claude-35-sonnet-modello-generativo.jpg "Anthropic Claude ora può cercare sul web e tra le nostre email")
/https://www.ilsoftware.it/app/uploads/2024/12/2-3.jpg "OpenAI introduce libreria immagini per ChatGPT accessibile a tutti")
/https://www.ilsoftware.it/app/uploads/2025/04/microsoft-copilot-studio-computer-use.jpeg "L'AI di Microsoft ora può usare il computer al posto nostro")
/https://www.ilsoftware.it/app/uploads/2025/04/wp_drafter_475329.jpg "Veo 2: presto versione gratuita dello strumento per generare video?")