/https://www.ilsoftware.it/app/uploads/2023/09/database-duckdb-interrogazione-harlequin.jpg "DuckDB: cos'è, come funziona e come gestire i database con Harlequin")
DuckDB è una soluzione per la gestione di database relazionali (RDBMS) ed è progettato per l’analisi dei dati ad alte prestazioni. Utilizza una combinazione di tecniche di compressione avanzate, elaborazione di query basata su vettori e caching intelligente per spingere l’acceleratore sulle performance. È quindi particolarmente adatto per l’integrazione con applicazioni e strumenti di analisi dei dati così da consentire l’esecuzione di query in tempo reale.
I documenti di supporto disponibili sul sito ufficiale del progetto DuckDB contengono le istruzioni per download e installazione su sistemi Windows, macOS e Linux.
Di base, DuckDB è un’applicazione che funziona da riga di comando: da qui si può creare un nuovo database, applicare modifiche, effettuare interrogazioni, creare basi di dati derivate e così via.
Le funzionalità principali di DuckDB
Facendo riferimento alla documentazione di DuckDB e cliccando sulla sezione Guides nella colonna di sinistra, si ha subito il polso delle potenzialità del database relazionale ad alte prestazioni. Progettato per l’analisi dati veloce ed efficiente, DuckDB offre supporto completo per SQL, compressione dei dati e integrazione con Python e altre librerie, il tutto in un pacchetto open source.
Come si può verificare negli esempi forniti all’interno della documentazione ufficiale, si possono importare ed esportare dati utilizzando SQL attingendo a formati comuni come CSV, Parquet e JSON. In un altro articolo abbiamo proprio visto cos’è un file CSV e come trasformare in database dati che normalmente sono aperti e gestiti con un foglio elettronico.
È inoltre possibile eseguire le query SQL da Python o da altri linguaggio e integrare DuckDB, ad esempio, con le librerie Pandas e i notebook Jupyter. Pandas è una libreria open source per la manipolazione e l’analisi dei dati in Python; i notebook Jupyter, invece, permettono di creare e condividere documenti contenenti codice eseguibile, testo descrittivo, grafici e risultati.
Per quanto riguarda Pandas, come abbiamo visto anche nell’articolo citato in precedenza, è possibile interrogare direttamente i DataFrame ed estrarre i dati d’interesse. Ciò proprio grazie all’integrazione tra DuckDB e Pandas.
Le performance verso le quali tende DuckDB permettono di massimizzare l’efficacia delle ricerche full text, utili per cercare e recuperare velocemente informazioni da documenti di testo. È inoltre possibile eseguire in modo molto semplice i cosiddetti ASOF Join ovvero operazioni di confronto tra dati temporali.
DuckDB: le caratteristiche più importanti
Alte prestazioni: il sistema è progettato per fornire elevate prestazioni nell’esecuzione di query complesse su grandi insiemi di dati. Utilizza tecniche avanzate come l’elaborazione vettoriale, la compressione dei dati e il caching intelligente per ottimizzare le operazioni di interrogazione.
Supporto SQL completo: supporta una vasta gamma di funzionalità SQL standard, inclusi JOIN, GROUP BY, aggregazioni, subquery e altro ancora.
Archiviazione ottimizzata: utilizza tecniche di compressione dei dati per ridurre lo spazio di archiviazione richiesto.
Elaborazione distribuita: supporta l’elaborazione distribuita. Ciò significa che DuckDB può essere utilizzato per gestire dati distribuiti su più nodi.
Utilizzo di dati in memoria: DuckDB consente di lavorare con i dati conservati nella memoria volatile. In questo modo è possibile ottenere analisi dati interattive estremamente performanti.
Estendibilità: è possibile estendere il sistema di gestione database attraverso funzioni personalizzate scritte in C++ o Python.
Integrazione con Python: DuckDB trova nel linguaggio Python il partner più naturale. Librerie quali duckdb-python consentono di predisporre script che interagiscono con i database DuckDB.
Open source: è un progetto open source che può vantare una comunità attiva. Il sorgente è accessibile pubblicamente e può essere eventualmente personalizzato.
Creare un nuovo database
Per importare dati in un nuovo database DuckDB, è sufficiente aprire l’interfaccia a riga di comando quindi digitare quanto segue:
duckdb -database nomedatabase.db
Con il comando COPY è possibile importare dati da un file CSV o da altre fonti di dati direttamente in una tabella DuckDB:
COPY table_name FROM '/path/to/data.csv' (FORMAT csv);
Come abbiamo visto nell’articolo citato in precedenza, si possono anche usare strumenti di terze parti o librerie Python, come Pandas, per caricare i dati da diverse fonti e quindi inserirli nel database DuckDB tramite le API Python.
È anche permessa la creazione di database in-memory: basta specificare il prefisso mem: prima del nome del database. Ad esempio:
duckdb -database mem:miodatabase
In questo caso il database DuckDB è appunto creato in memoria anziché su disco. Il comando COPY o altri metodi di caricamento dati funzionano anche nel caso in cui il database si trovi nella memoria RAM. Il codice Python riportato di seguito importa, ad esempio, i dati contenuti in file CSV all’interno del database creato in memoria:
import pandas as pd
import duckdb
# Legge i dati in un DataFrame Pandas
df = pd.read_csv('/dati.csv')
# Crea una connessione al database DuckDB in memoria
conn = duckdb.connect(database='mem:miodatabase')
# Inserisci il DataFrame nel database DuckDB
conn.register('mytable', df)
Come gestire i database DuckDB con Harlequin
Per rendere molto più dolce la curva di apprendimento di DuckDB, è da oggi possibile utilizzare un software open source come Harlequin.
Si tratta di un’applicazione, scritta in Python, che semplifica la gestione dei database DuckDB tramite la riga di comando. L’autore racconta di aver sviluppato Harlequin inizialmente esigente prettamente personali: perché le sue query diventavano più complesse e i risultati sempre più estesi. La CLI (command-line interface) di DuckDB ha delle limitazioni che, in questi frangenti, rallentano il lavoro.
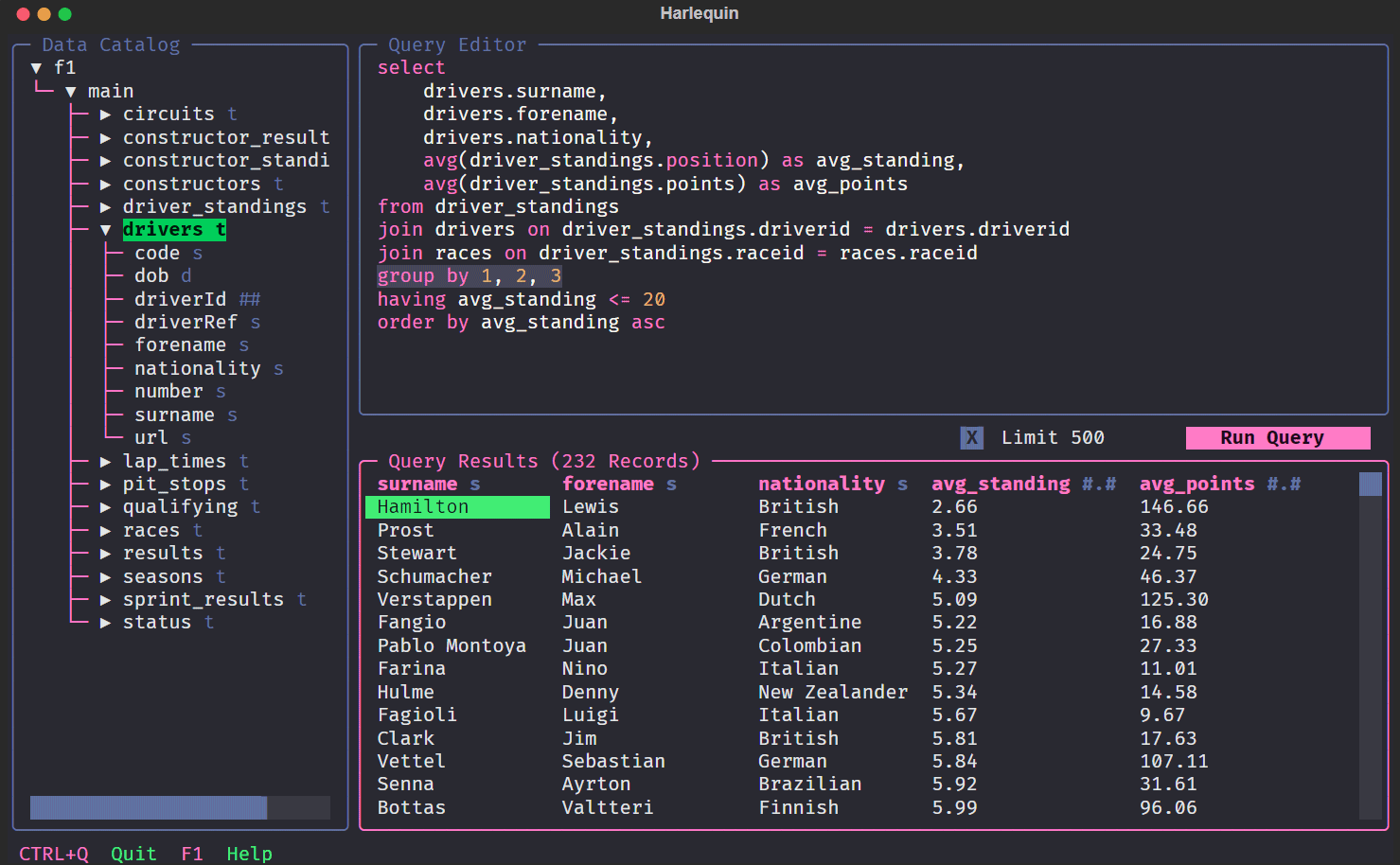
Anche Harlequin lavora da riga di comando ma presenta funzionalità aggiuntive che rendono più agevole l’interazione con i dati. Ad esempio, permette di scorrere il contenuto del database direttamente, accedere alla sua struttura, inviare query SQL e ottenere subito il risultato in un riquadro separato. Inoltre, consente di scegliere tra decini di stili differenti per la sua interfaccia testuale.
L’autore ha reso disponibile Harlequin come software open source, annunciando il rilascio della prima versione finale. Il software diventa accessibile a una vasta comunità di utenti che possono beneficiare delle sue funzionalità.
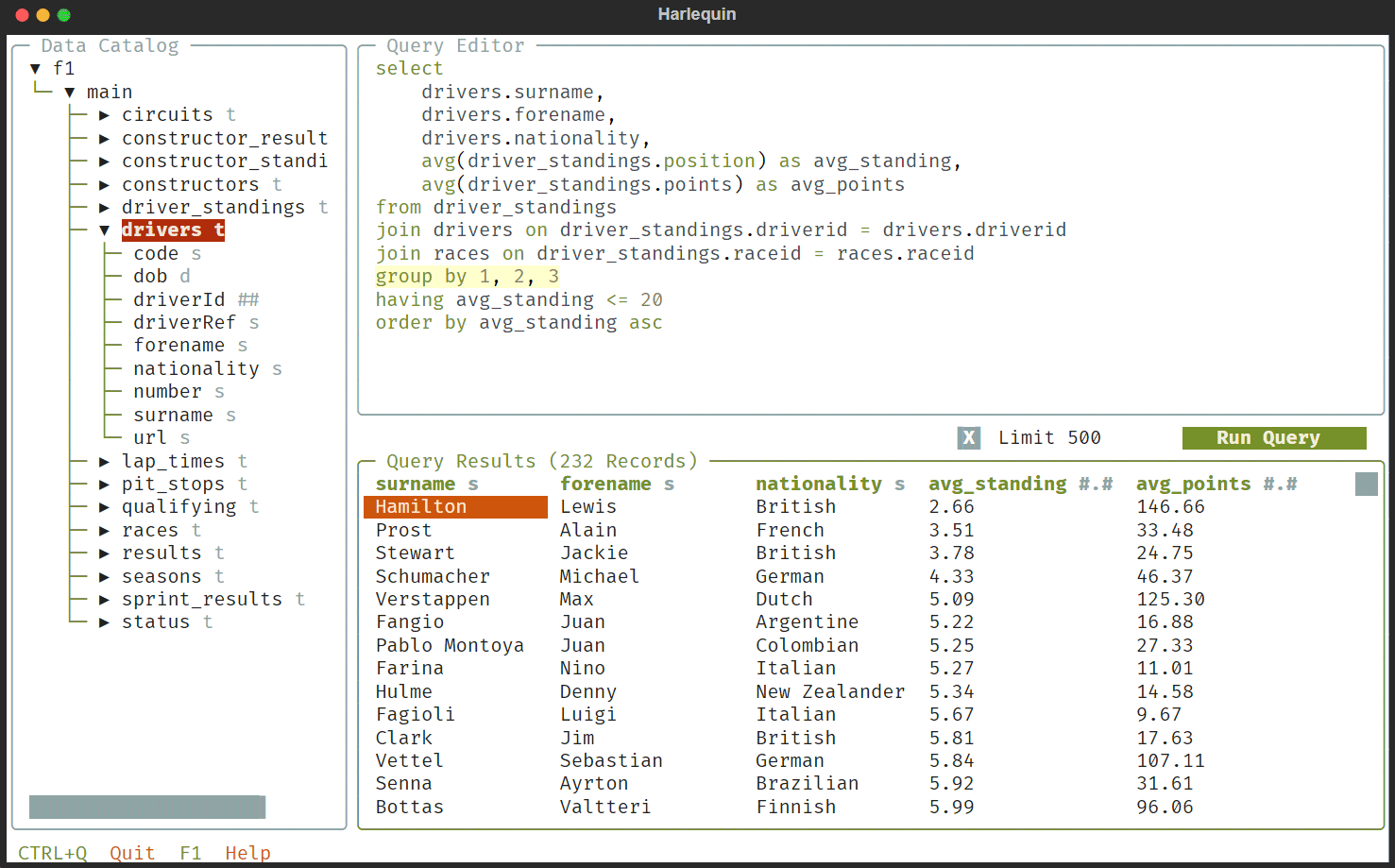
Ricorrendo ad Harlequin, si può lavorare su qualunque database DuckDB, compresi quelli in-memory. Per installare il software è necessario disporre della più recente versione di Python:
pipx install harlequin
Per aprire uno o più database DuckDB, è possibile utilizzare il seguente comando da qualsiasi shell, fornendo i percorsi ai file da elaborare come argomenti:
harlequin "path/to/miodatabase.db" "altrodatabase.db"
Nella sintassi di esempio, si chiede ad Harlequin di aprire due database DuckDB specificandone le corrispondenti denominazioni.
Credit immagine in apertura: iStock.com/islander11
/https://www.ilsoftware.it/app/uploads/2025/12/consumo-RAM-app-windows-11.jpg "Perché Windows 11 sta consumando gigabyte di RAM con Discord, Teams e WhatsApp?")
/https://www.ilsoftware.it/app/uploads/2025/12/react2shell.jpg "React2Shell: falla critica che minaccia migliaia di app Next.js. Il tuo server è al sicuro?")
/https://www.ilsoftware.it/app/uploads/2025/12/javascript-compie-30-anni.jpg "30 anni di JavaScript: il linguaggio che ha trasformato il Web")
/https://www.ilsoftware.it/app/uploads/2025/12/anthropic-bun-claude-code.jpg "Perché Anthropic ha acquisito Bun: la svolta che cambia Claude Code e lo sviluppo AI")