/https://www.ilsoftware.it/app/uploads/2023/05/img_17218.jpg "Da Google Research un sistema per estrarre l'audio che interessa isolandolo dal rumore di fondo")
È chiamato cocktail party effect ed è un termine con cui gli studiosi si riferiscono a quella naturale abilità del cervello umano che consiste nell’isolare il parlato di una persona specifica o un particolare suono scartando il rumore di fondo o altre voci sovrapposte.
Gli ingegneri del team Google Research hanno illustrato gli enormi passi avanti appena compiuti nel consentire alle macchine di svolgere la medesima operazione.
Nello studio da poco pubblicato online i ricercatori di Google hanno descritto una metodologia, basata sull’utilizzo di algoritmi per l’intelligenza artificiale, che permette di estrapolare efficacemente determinate fonti sonore isolandole dal “resto del mondo”.
Inbar Mosseri e Oran Lang hanno spiegato che il loro approccio è efficace sull’audio tradizionale registrato a traccia singola: ciò che l’utente deve fare è semplicemente indicare il volto della persona che si desidera ascoltare. Il suo parlato verrà fatto emergere e il rumore di fondo sapientemente escluso.
L’aspetto davvero unico della tecnica appena messa a punto da Google è che l’intelligenza artificiale riesce a combinare efficacemente il segnale audio con i parametri visuali effettuando ad esempio la correlazione tra i movimenti della bocca e le parole pronunciate e registrate in una sequenza video.
Com’è intuitivo, infatti, i movimenti delle labbra devono essere necessariamente accordarsi con il parlato: se più voci si accavallano, l’intelligenza artificiale sarà così in grado di trovare l’audio che si riferisce inequivocabilmente al soggetto d’interesse.
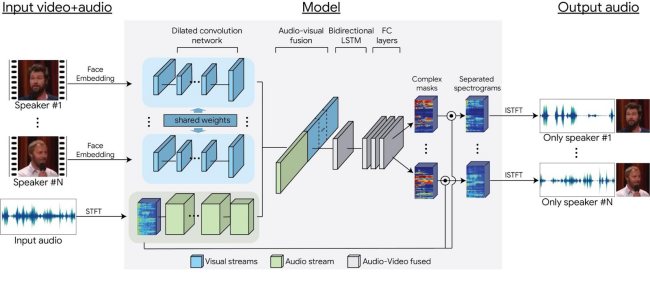
Per ottenere i risultati riscontrabili nel video che abbiamo ripubblicato in precedenza e in quelli contenuti in queste pagine, gli esperti di Google hanno addestrato il modello usando circa 100.000 video ad alta qualità presi da YouTube: sono stati estratte porzioni di parlato senza alcun disturbo in sottofondo producendo circa 2.000 ore di registrato.
Le informazioni raccolte sono state quindi utilizzare per costruire migliaia di differenti situazioni in cui il parlato è appunto combinato con la mimica facciale e, in particolare, i movimenti della bocca.
I dati hanno permesso di creare una rete neurale convoluzionale multi-stream che ha permesso di suddividere in singole tracce il parlato di ciascun soggetto.
/https://www.ilsoftware.it/app/uploads/2024/11/generico-streaming-tv.jpg "Streaming: un'altra piattaforma introduce il Membro Extra")
/https://www.ilsoftware.it/app/uploads/2024/06/YouTube-Music.jpg "YouTube Music introduce nuova funzione per normalizzare il volume")
/https://www.ilsoftware.it/app/uploads/2025/04/pinta-editor-immagini-open-source.jpg "Arriva Pinta 3.0, alternativa leggera a Paint.NET e GIMP")
/https://www.ilsoftware.it/app/uploads/2025/04/formato-RAW-fotocamera-digitale.jpg "RAW: perché i produttori di fotocamere usano formati differenti?")