/https://www.ilsoftware.it/app/uploads/2024/12/paligemma-2-riconosce-immagini.jpg "Computer vision con PaliGemma 2: l'AI riconosce le immagini")
Google sta ulteriormente migliorando le abilità di computer visione (visione artificiale) assicurate dai suoi più aggiornati modelli generativi. Il nuovo PaliGemma 2, potente VLM (Vision Language Model) di ultima generazione, raccoglie l’eredità del predecessore PaliGemma presentato a metà maggio 2024 ed è progettato per integrare la comprensione delle immagini con quella del testo, offrendo una soluzione versatile per l’interpretazione di contenuti visivi in modo dettagliato e contestualizzato.

Caratteristiche di PaliGemma 2
PaliGemma 2 è disponibile in diverse configurazioni per ottimizzare le performance in base alle necessità specifiche. È infatti possibile scegliere tra modelli di dimensioni variabili (3B, 10B, 28B) e risoluzioni (224 x 224, 448 x 448, 896 x 896 pixel). Queste opzioni permettono di adattare il modello alle varie tipologie di task visivi, mantenendo alte prestazioni anche nella gestione delle applicazioni più complesse.
Una delle caratteristiche distintive di PaliGemma 2 è la sua capacità di generare descrizioni più ricche e dettagliate rispetto ai modelli precedenti. Non si limita a riconoscere oggetti, ma è in grado di creare didascalie che spiegano il movimento, l’emozione e il contesto generale di una scena. Il modello ha dimostrato un’elevata competenza nel riconoscimento di formule chimiche, notazioni musicali, nel “ragionamento spaziale” e nell’analisi di immagini mediche (ad esempio le radiografie toraciche).
Fine-tuning semplice
Un altro grande punto di forza di PaliGemma 2 è la possibilità di effettuare attività di fine-tuning in modo facile e accessibile.
Sviluppatori e ricercatori possono così personalizzare il modello in base a specifici requisiti. Una versatilità che apre a nuovi scenari applicativi in settori che vanno dalla medicina alla chimica, fino alle scienze sociali, permettendo di estrarre informazioni dettagliate da contenuti visivi complessi.
Il modello PaliGemma 2 è reso disponibile attraverso diverse piattaforme (GitHub e Hugging Face) e può essere facilmente integrato in progetti di ricerca o commerciali. Google incoraggia gli sviluppatori a partecipare alla community Gemma, nota come “Gemmaverse“: qui possono condividere i loro progetti e scoprire nuove opportunità di utilizzo.
Da questa pagina Hugging Face, si può scaricare il modello basato su 3 miliardi di parametri (3B) che accetta immagini in input con risoluzione 448 x 448 pixel. Effettuando le opportune sostituzioni nella barra degli indirizzi (3B, 10B, 28B) e 224, 448, 896, si possono scaricare le varie versioni di PaliGemma 2.
Come provare PaliGemma 2 per la computer vision
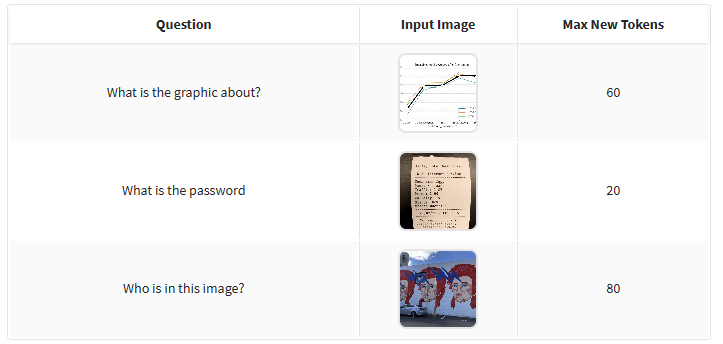
In questa pagina su Hugging Face è possibile trovare una semplice demo di PaliGemma 2: provate a cliccare sulle immagini in basso quindi cliccate su Submit.
Come potete vedere, il quesito varia. In un caso si chiede al modello di analizzare un grafico e specificare che cosa riguarda. In un altro, PaliGemma 2 è utilizzato per leggere ed estrarre la password presente sulla foto di un supporto cartaceo; in un terzo esempio si chiede di indicare il personaggio raffigurato in un murale.
Con PaliGemma 2, Google apre nuove frontiere nell’interazione tra visione e linguaggio, offrendo agli sviluppatori strumenti potenti per costruire applicazioni AI innovative. La combinazione di prestazioni avanzate e facile personalizzazione, posiziona PaliGemma 2 come uno degli strumenti di punta nel campo dell’intelligenza artificiale visiva.
Come spiegato in questo post introduttivo, per il momento è necessario usare Python, il package manager pip e installare transformers. Per ottimizzare le prestazioni, è importante usare un sistema basato su GPU compatibile CUDA.
Questo esempio che sfrutta semplice codice Python permette di avviare attività di inferenza con PaliGemma 2 per generare didascalie a partire dalle immagini sottoposte al modello. Per ridurre l’utilizzo di memoria e aumentare la velocità di elaborazione, è possibile caricare il modello con quantizzazione a 4 bit usando BitsAndBytesConfig.
PaliGemma 2 in arrivo su Ollama
Ollama, il runner che democratizza l’accesso ai modelli generativi (la loro esecuzione si sposta in locale sui sistemi degli utenti) a breve integrerà anche PaliGemma 2.
Nel frattempo ci si può “accontentare” di Llama 3.2 Vision, un modello sviluppato da Meta che aiuta ad automatizzare l’analisi del contenuto delle immagini. Basta digitare la richiesta (ad esempio l’estrazione di un dato dall’immagine o la generazione di una frase descrittiva del contenuto) e indicare il percorso completo (locale) del file da elaborare.
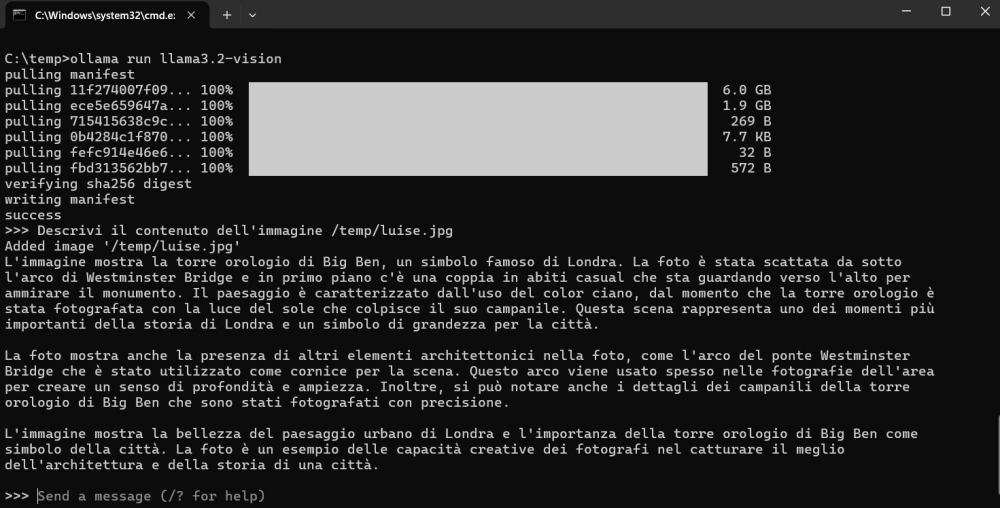
Nell’immagine abbiamo chiesto a Llama 3.2 Vision di descrivere il contenuto di questa immagine, scaricata da Unsplash nel formato originale e salvata in locale con il nome di /temp/luise.jpg.
Come spiegato in questo documento di supporto, è possibile interfacciare Llama 3.2 Vision con tutti i principali linguaggi di programmazione. Inoltre, si può beneficiare di framework come Stregatto AI che aiuta a sviluppare componenti personalizzati con la possibilità di integrarli facilmente nei propri progetti software.
/https://www.ilsoftware.it/app/uploads/2025/04/comandi-ai-tag-gestire-schede-browser.jpg "Browser Opera: intelligenza artificiale per gestire le schede aperte")
/https://www.ilsoftware.it/app/uploads/2024/12/3-11.jpg "ChatGPT: generazione di immagini migliorata di nuovo disponibile per tutti")
/https://www.ilsoftware.it/app/uploads/2025/04/whatsapp-automazione-claude-AI.jpg "È davvero possibile integrare WhatsApp con Claude e altri modelli AI?")
/https://www.ilsoftware.it/app/uploads/2025/04/vulnerabilita-bootloader-AI.jpg "Microsoft usa l'AI per scoprire vulnerabilità in GRUB2, U-Boot e Barebox")