/https://www.ilsoftware.it/app/uploads/2024/02/cohere-aya-cose-come-funziona.jpg "Cohere presenta Aya, un LLM rivoluzionario che copre oltre 100 lingue")
Nell’ultimo biennio, i modelli linguistici di grandi dimensioni (LLM, Large Language Models) hanno rivoluzionato il campo dell’intelligenza artificiale. La maggior parte di essi, tuttavia, è stata sviluppata utilizzando principalmente corpus di informazioni disponibili in lingua inglese. Un aspetto che ha portato a problemi di accuratezza nella generazione di frasi nelle altre lingue, italiano compreso.
La startup canadese Cohere, che di recente ha ottenuto finanziamenti per un miliardo di dollari, ha appena presentato Aya, un LLM che copre più del doppio delle lingue rispetto ai modelli open source esistenti. Proprio di recente abbiamo messo a fuoco le principali alternative open source al chatbot ChatGPT di OpenAI e ai sottostanti Generative pre-trained transformer (GPT). L’idea di transformer, peraltro, nasce da un lavoro sviluppato e pubblicato nel 2017 da un team di Google.
Cos’è e come funziona Cohere Aya: ecco il suo comportamento in italiano
Cohere for AI, organizzazione di ricerca senza scopo di lucro legata alla startup Cohere, ha sviluppato Aya coinvolgendo ben 3.000 ricercatori provenienti da 119 Paesi. Il nuovo LLM, che adesso può pubblicamente fare mostra di sé, è progettato per coprire oltre 100 lingue, andando ben oltre le limitazioni dei modelli preesistenti.
Il dataset utilizzato da Cohere for AI è estremamente ampio, includendo dati tradotti automaticamente in oltre 100 lingue. Tra queste, la metà rappresenta lingue che non possono essere apprese adeguatamente utilizzando set di dati testuali esistenti. L’idea, insomma, era quella di dare un forte impulso per l’utilizzo dei modelli generativi basati su IA e linguaggio naturale, anche per tutti quei soggetti che parlano e scrivono lingue poco diffuse. Un’iniziativa che promette di ridurre le disparità linguistiche e aumentare l’accessibilità della tecnologia per tutte le comunità precedentemente trascurate.
Secondo gli ingegneri software di Cohere for AI, Aya supererebbe di gran lunga modelli come mt0 e bloomz nei principali benchmark, ottenendo costantemente il 75% nelle valutazioni umane e un tasso di vittoria nelle simulazioni pari all’80-90% rispetto ad altri modelli open source leader di mercato.
Un modello linguistico enorme, che convince anche per i tipi di input utilizzati
Sarah Hooker, vicepresidente della ricerca presso Cohere, rivela che agli albori i sostenitori del progetto non avevano la minima idea di quanto si sarebbe evoluto. Alla fine, invece, il dataset è divenuto enormemente esteso e si è rivelato incredibilmente preciso e attendibile per la generazione di output pertinenti e ben argomentati.
I modelli di Aya sono ospitati nel repository di Hugging Face con licenza Apache 2.0, e un dataset contenente 513 milioni di tipi di input in 114 lingue è anch’esso disponibile sulla medesima piattaforma e con uguale licenza. Il termine “tipi di input” si riferisce alle varie categorie o forme di dati utilizzate per allenare o interagire con un modello di linguaggio. I 513 milioni di tipi di input indica la presenza in Aya di un vasto insieme di informazioni adoperati per addestrare e valutare il modello linguistico.
Ciascun “tipo di input” può essere considerato come una frase, una domanda, una descrizione o qualsiasi altro frammento di testo che il modello deve comprendere, elaborare o può usare per generare risposte.
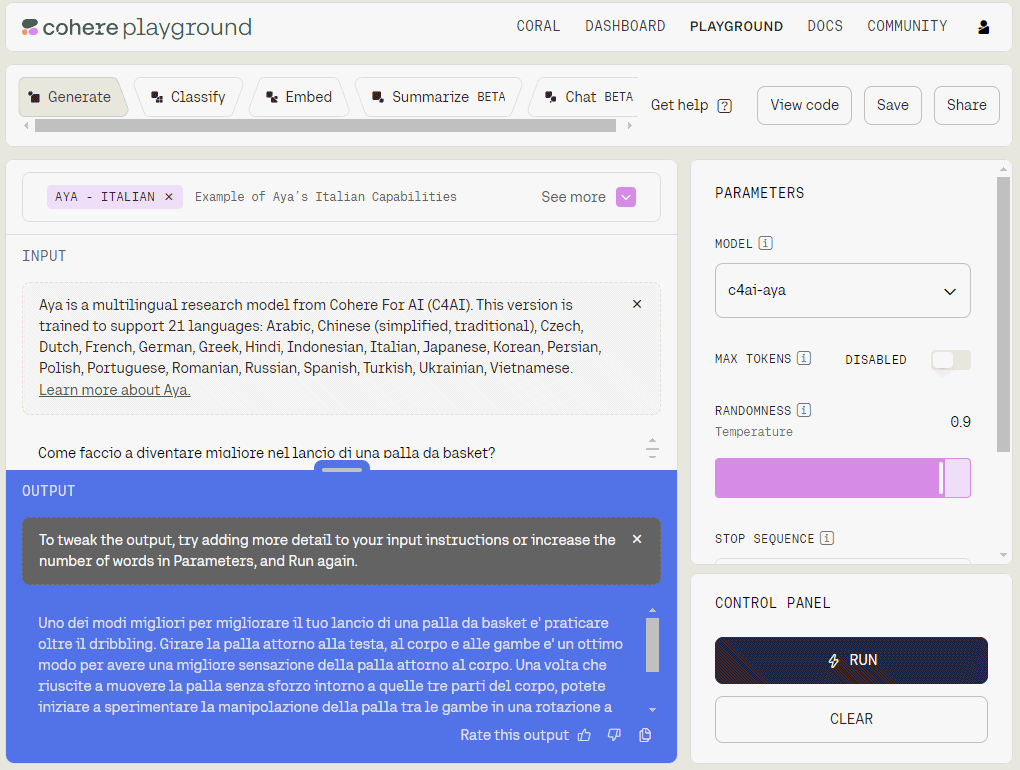
Come provare il LLM Cohere Aya
Per mettere subito alla prova Aya, è possibile visitare la pagina ufficiale del progetto quindi fare clic sul pulsante “Try Aya in the playground“. Previo login alla dashboard di Cohere (con un account Google, GitHub o via email), si deve quindi selezionare Go to playground. Per provare direttamente Aya con il supporto l’italiano, si può incollare nella barra degli indirizzi del browser Web questo indirizzo.
Agendo sui parametri contenuti nella colonna di destra, si può scegliere il modello da usare, il numero di token massimo ottenibili in output, decidere se il LLM possa essere più o meno creativo (Temperature) e altro ancora.
Con un clic sul pulsante Run, si può dare il via alla generazione del testo a partire dal prompt fornito dall’utente.
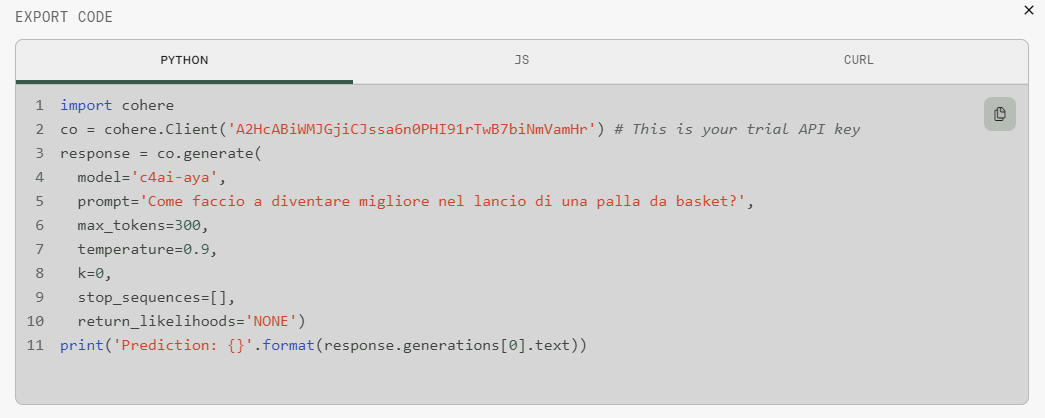
Grazie alle API che Cohere mette a disposizione, con un clic su View code si hanno a disposizione esempi di codice pronto all’uso in Python e JavaScript. C’è anche la sintassi da usare dalla finestra del terminale inviando una richiesta con il comando curl.
/https://www.ilsoftware.it/app/uploads/2024/12/3-11.jpg "Ora è possibile sostituire Gemini con ChatGPT sul tuo telefono Android")
/https://www.ilsoftware.it/app/uploads/2024/04/gaming-xbox.jpg "Al via i test per l'assistente AI di Microsoft che aiuta i videogiocatori")
/https://www.ilsoftware.it/app/uploads/2023/12/intelligenza-artificiale-browser-mozilla.jpg "AI e motori di ricerca: nel 60% dei casi citate fonti errate")
/https://www.ilsoftware.it/app/uploads/2025/03/ILSOFTWARE-7-2.jpg "OpenAI, nuovo modello per la scrittura creativa: ecco come funziona")