/https://www.ilsoftware.it/app/uploads/2024/08/chatbot-cerebras-inference-IA.jpg "Cerebras Inference: provate il nuovo chatbot per risposte fulminee")
L’inferenza è la fase in cui un modello generativo, precedentemente addestrato, è utilizzato per elaborare dati input e generare informazioni in output. Questo processo è notoriamente impegnativo dal punto di vista computazionale, soprattutto con i Large Language Models (LLM) più estesi, che richiedono risorse importanti in termini di memoria e larghezza di banda.
I limiti intrinseci dovuti alla necessità di trasferire grandi quantità di dati tra la memoria esterna e i core di calcolo per ogni token generato, rallenta significativamente il processo di inferenza, rendendo difficoltoso ottenere risposte in tempo reale.
Cerebras Inference: inferenza 22 volte più veloce rispetto alle GPU NVIDIA H100
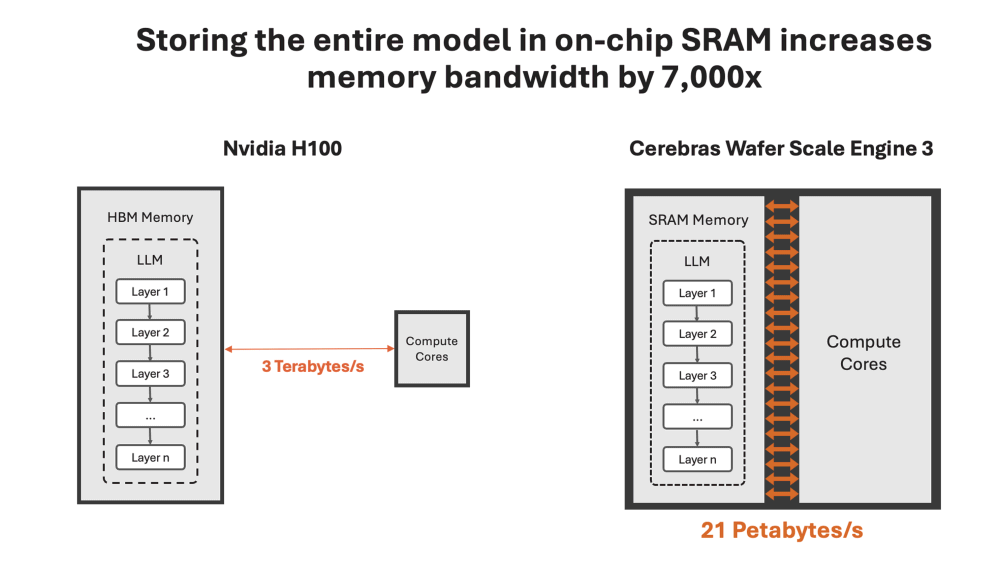
Cerebras ha annunciato il suo Wafer Scale Engine 3 (WSE-3), il chip attualmente più grande al mondo, con 44 GB di memoria SRAM integrata. L’obiettivo è fare la parte del leone nel segmento di mercato dell’intelligenza artificiale, eliminando così la necessità di memoria esterna e spazzando via le latenze aggiuntive.
Il design messo a punto di tecnici di Cerebras consente al chip di offrire un’incredibile larghezza di banda di memoria aggregata pari a 21 petabyte al secondo, circa 7.000 volte quella di una GPU H100. Questo permette al WSE-3 di gestire interamente i modelli AI sulla memoria on-chip, accelerando notevolmente il processo di inferenza.
Prendendo come benchmark il modello Llama 3.1, WSE-3 permette di gestirlo a velocità impossibili da raggiungere con le tecnologie tradizionali. In particolare, il servizio è in grado di elaborare 1.800 token al secondo per il modello Llama 3.1 8B e 450 token al secondo per il modello Llama 3.1 70B. Questi numeri rappresentano una velocità 20 volte superiore rispetto ai cloud hyperscale basati su GPU.
Cerebras Inference utilizza inoltre i pesi dei modelli originali a 16 bit, rilasciati da Meta. Un aspetto che si rivela particolarmente importante in contesti in cui la precisione è critica, come nelle conversazioni complesse o nelle attività di ragionamento matematico.
![]()
Il futuro dell’AI con Cerebras
Cerebras non si ferma qui: in futuro, il servizio supporterà modelli ancora più grandi, come il Llama 3 405B e il Mistral Large, continuando a stabilire nuovi standard nel settore dell’AI.
Con l’accesso aperto via API, gli sviluppatori possono integrare facilmente le capacità di inferenza di Cerebras nelle loro applicazioni, sfruttando velocità, precisione e costo.
A proposito di costi, infatti, Cerebras applica 10 centesimi per milione di token per il modello Llama 3.1 8B e 60 centesimi per milione di token nel caso del modello Llama 3.1 70B. Questo rappresenta un notevole risparmio rispetto alle soluzioni basate su GPU, che risultano essere cinque volte più economicamente impegnative.
La capacità di fornire risposte in tempo reale, unita a costi competitivi e a una precisione senza compromessi, apre nuove possibilità per lo sviluppo di applicazioni di IA avanzate, segnando l’inizio di una nuova era nell’intelligenza artificiale.
Come provare le risposte istantanee di Cerebras AI
Con il preciso obiettivo di mostrare i vantaggi derivanti dalla tecnologia Cerebras Inference e dal chip WSE-3, l’azienda ha pubblicato il chatbot Cerebras AI, che può essere utilizzato inviando anche richieste in italiano per generare ogni tipo di contenuto.
Il menu a tendina in alto a destra permette di scegliere se usare il LLM Llama 3.1 8B oppure il più complesso e pesante Llama 3.1 70B. Notate, in entrambi i casi, la velocità delle risposte fornite dal sistema.
Credit immagine in apertura: iStock.com – Vertigo3d
/https://www.ilsoftware.it/app/uploads/2024/03/wish-disney.jpg "OpenAI potrà usare i personaggi Disney, Google no")
/https://www.ilsoftware.it/app/uploads/2025/06/grok-donald-trump.jpg "Trump blinda l'AI: più controllo col nuovo ordine esecutivo")
/https://www.ilsoftware.it/app/uploads/2025/07/grok.jpeg "Le scuole di El Salvador si affidano all'AI Grok di Elon Musk")
/https://www.ilsoftware.it/app/uploads/2025/12/novita-GPT-52.jpg "GPT-5.2: analisi delle novità del nuovo modello AI integrato in ChatGPT e nelle API")