/https://www.ilsoftware.it/app/uploads/2025/02/vlm-run-riconoscere-testo-immagini-ai.jpg "Addio OCR: come estrarre dati dalle immagini con i Vision Language Models")
L’analisi dei dati visivi rappresenta una delle sfide più complesse per chi si occupa di sviluppo software e per tutti i professionisti che devono estrarre valore da immagini e altri contenuti non direttamente lavorabili. L’evoluzione dalla tecnologia OCR (Optical Character Recognition) ai Vision Language Models (VLM) segna un passaggio fondamentale nel modo in cui le macchine “comprendono” i contenuti visivi.
Gli OCR tradizionali: limitazioni e vantaggi
La tecnologie OCR sono state per decenni un vero e proprio riferimento per l’estrazione di testo dalle immagini. Il funzionamento del sistemi OCR si basa sul riconoscimento dei caratteri all’interno di documenti digitalizzati, come scansioni di documenti, libri, fatture o ricevute.
Testi con bassa risoluzione, distorsioni o sfondi complessi, tuttavia, riducono l’accuratezza dell’OCR. Una soluzione OCR, inoltre, si limita ad estrarre soltanto il testo grezzo senza comprenderne il significato o la struttura. Tabelle, layout dinamici o immagini con elementi grafici possono confondere i motori OCR, portando a risultati ben lontani dalle aspettative.
L’avvento dei Vision Language Models (VLM): un nuovo paradigma
I VLM sono studiati per superare (di ordini di grandezza) tutte le limitazione degli OCR, combinando l’elaborazione visiva con la comprensione linguistica. A differenza dell’OCR, che si limita a “vedere” il testo, i VLM cercando di interpretare il significato e la struttura dei contenuti visivi.
Questi nuovi strumenti non soltanto estrapolano i testi dalle immagini ma sono in grado di “capire” il contesto, grazie all’uso di modelli di intelligenza artificiale generativa addestrati su immagini e linguaggio naturale.
Ad esempio, possono riconoscere una fattura distinguendo intestazioni, importi e dettagli, senza bisogno di regole predefinite. Possono analizzare tabelle, grafici, annotazioni e strutture gerarchiche nei documenti, senza confondersi con i vari elementi grafici presenti.
Ancora, un report aziendale contenente tabelle e paragrafi misti può essere elaborato dal VLM che va a creare una struttura coerente, restituendo dati ben organizzati.
Estrazione di JSON strutturati
Se, da un lato, i vecchi OCR restituiscono solo il testo, i recenti VLM possono generare output in formato JSON. Questi ultimi possono essere utilizzati per elaborare i dati, anche in maniera automatizzata, a seconda delle proprie esigenze. I dati estratti dalle immagini e restituiti all’utente sotto forma di JSON, possono essere elaborati così come sono, importati all’interno di database o in altri sistemi di analisi dei dati.
Personalizzazione e adattabilità
I VLM possono essere personalizzati per specifici settori, imparando a identificare informazioni rilevanti in ambito sanitario, finanziario o legale. Un OCR tradizionale necessita di regole statiche per interpretare nuovi tipi di documenti, mentre un VLM può generalizzare meglio i dati.
Inoltre, mentre un OCR lavora soltanto su immagini statiche, i moderni VLM possono gestire anche frame video, con la possibilità di rilevare il testo in movimento e contestualizzarlo.
VLM Run: un’applicazione concreta della nuova frontiera
Nel recente passato, abbiamo parlato delle abilità di Llama 3.2 Vision, modello che grazie al framework Ollama chiunque può portare in locale e utilizzare per estrarre informazioni rilevanti da qualunque immagine. Utilizzando richieste (prompt) opportunamente congegnate e indicando esplicitamente il percorso e il nome del file da elaborare, un modello come Llama 3.2 Vision può restituire i dati estrapolati dalle immagini in forma strutturata.
VLM Run si inserisce in questo nuovo paradigma, fornendo un’API (Application Programming Interface) in grado di estrarre dati strutturati da immagini, documenti e video con un approccio intelligente e adattivo.
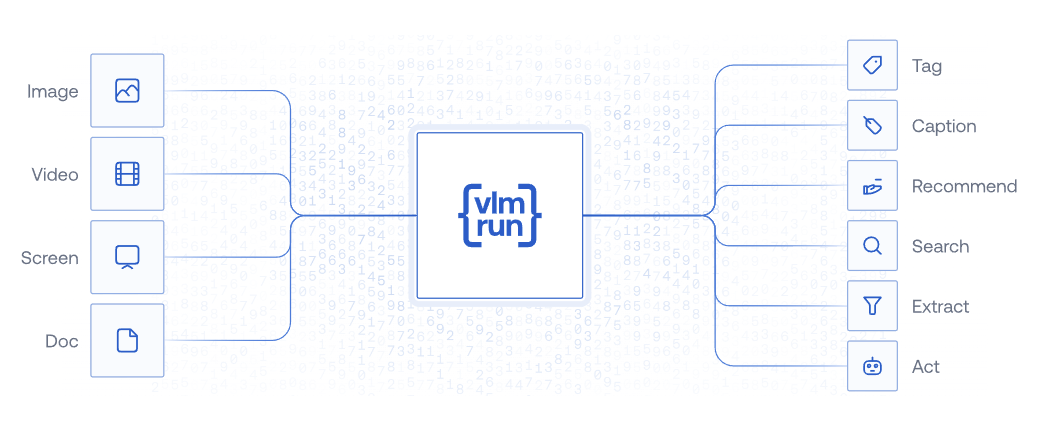
Alla base di VLM Run c’è vlm-1, un Vision Language Model avanzato, ottimizzato per l’estrazione e la categorizzazione di dati non strutturati. Grazie a questa tecnologia, professionisti e aziende possono convertire contenuti visivi in formati leggibili e immediatamente utilizzabili, facilitando l’integrazione nei database e all’interno di flussi di lavoro automatizzati. L’API di VLM Run consente di elaborare:
- Immagini (ad esempio scansioni di documenti, screenshot di interfacce utente)
- PDF e documenti (report, presentazioni, contratti)
- Video (frame per individuare e categorizzare contenuti rilevanti)
Alcuni esempi pratici
Date un’occhiata agli esempi contenuti nei VLM Run Cookbooks, ospitati su GitHub.
VLM Run propone diversi spunti per dimostrare le potenzialità della piattaforma di elaborazione visiva strutturata. Gli esempi coprono vari ambiti e utilizzano schemi predefiniti per analizzare immagini ed estrarre informazioni strutturate. Tra i principali esempi forniti:
- Analisi di fatture. Elaborazione dell’immagine di una fattura per estrarre dettagli come il numero della fattura, la data di emissione, l’indirizzo del cliente, gli articoli acquistati e il totale.
- Analisi di Curriculum Vitae. L’algoritmo analizza un CV per estrarre informazioni come nome, contatti, esperienza lavorativa e istruzione.
- Analisi di passaporti. Un esempio di elaborazione di un passaporto con l’estrazione di dettagli come nome, cognome, numero del documento e data di nascita.
- Analisi di tessere sanitarie. La piattaforma estrae informazioni presenti nelle tessere sanitarie.
- Analisi di partite. Le immagini dei match sportivi possono essere elaborate automaticamente per estrarre in tempo reale informazioni sullo stato della partita.
- Analisi telerilevamento. Utilizzo di immagini satellitari per identificare e interpretare informazioni geospaziali.
- Analisi di e-commerce. Estrazione di descrizioni e caratteristiche di prodotti presenti nelle immagini pubblicate all’interno di cataloghi online.
Credit immagine in apertura: iStock.com – AndSim
/https://www.ilsoftware.it/app/uploads/2024/06/claude-35-sonnet-modello-generativo.jpg "Anthropic Claude ora può cercare sul web e tra le nostre email")
/https://www.ilsoftware.it/app/uploads/2024/12/2-3.jpg "OpenAI introduce libreria immagini per ChatGPT accessibile a tutti")
/https://www.ilsoftware.it/app/uploads/2025/04/microsoft-copilot-studio-computer-use.jpeg "L'AI di Microsoft ora può usare il computer al posto nostro")
/https://www.ilsoftware.it/app/uploads/2025/04/wp_drafter_475329.jpg "Veo 2: presto versione gratuita dello strumento per generare video?")