/https://www.ilsoftware.it/app/uploads/2024/02/groq-schiaccia-chatgpt-LPU.jpg "Addio ChatGPT, Groq offre prestazioni migliori. Ecco come")
Il documento risalente al 2017, con cui un gruppo di ingegneri Google introdusse il concetto di transformer, è stato la scintilla che ha ispirato OpenAI e portato l’azienda a lanciare i suoi modelli generativi GPT (Generative pre-trained transformer), facendo poi debuttare il chatbot ChatGPT come prodotto più mainstream. La mossa di OpenAI pose Google in una condizione “di affanno”: l’azienda fondata da Larry Page e Sergey Brin non sembrava ancora ben disposta per il debutto nel mercato delle soluzioni basate sull’intelligenza artificiale.
Nell’ultimo biennio abbiamo assistito a una vera e propria gara volta da un lato a offrire agli utenti modelli generativi più o meno specializzati e performanti, ma in primis addestrati su un corpus di dati di qualità, in modo da massimizzare la pertinenza e l’adeguatezza dei risultati riducendo allo stesso tempo il fenomeno delle allucinazioni (comune a tutti i modelli che usano un approccio stocastico).
Groq utilizza i suoi chip LPU per migliorare le prestazioni dei modelli generativi
A scuotere il mondo delle soluzioni basate sull’IA arriva adesso Groq, azienda con sede a Mountain View (come Google) che annuncia di aver raggiunto un nuovo traguardo nello sviluppo di unità di elaborazione del linguaggio (LPU) utilizzando hardware personalizzato. La società ha infatti approntato configurazioni ottimizzate che consentono di eseguire modelli LLM (Large Language Models) con una velocità straordinaria.
Groq, specializzata nello sviluppo di chip ad alte prestazioni e soluzioni software per le applicazioni di intelligenza artificiale, apprendimento automatico e il computing avanzato, sta attirando grande attenzione perché si presenta come una piattaforma rivoluzionaria.
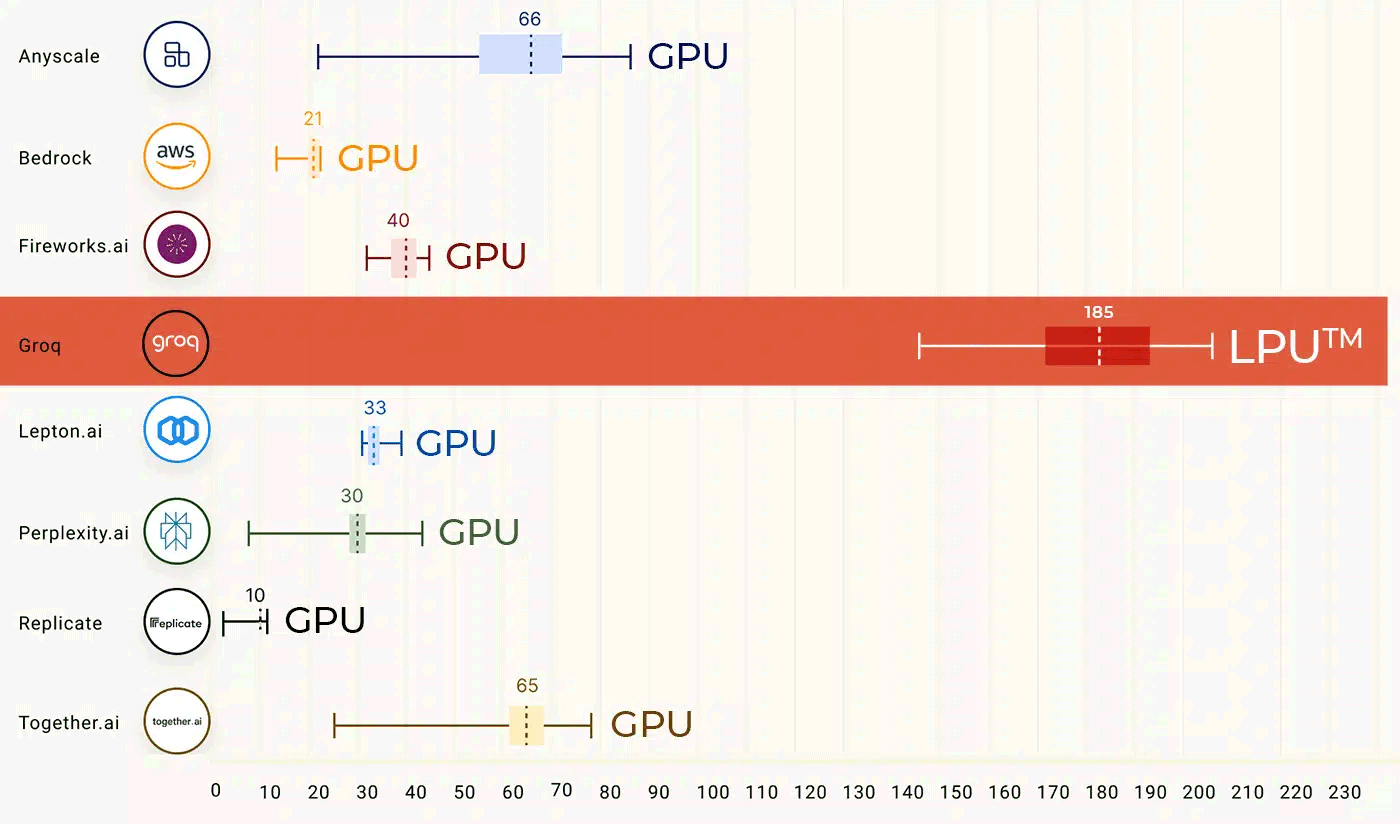
Il chip LPU progettato dagli ingegneri di Groq è descritto come un pilastro fondamentale per offrire prestazioni di molto superiori rispetto alle GPU tradizionali. Ne è una conferma il chatbot pubblicato a questo indirizzo: seppur in versione “alpha”, offre risultati molto più rapidamente rispetto a ChatGPT e agli altri concorrenti. A parità di LLM (al momento Groq non fornisce una sua soluzione ma si basa sui più noti modelli di IA open source), grazie ai suoi chip LPU, Groq può eseguire le elaborazioni fino a 10 volte più velocemente rispetto alle elaborazioni basate su GPU.
Come provare il chatbot
Dalla home page di Groq, agendo sul menu a tendina Model in alto a sinistra, è possibile selezionare lo specifico modello generativo da usare. In questa prima fase, si può ricorrere sia a Llama 2 70B sviluppato da Meta che a Mixtral 8x7B, realizzato da Mistral AI.
Nel campo Enter prompt here, si può evidentemente inserire l’input da trasferire al modello (anche in italiano). Una volta ottenuta la risposta, di solito appropriata, aderente e ben argomentata, è eventualmente possibile cliccare su Modify per modificare il tono della risposta, da informale a più formale/professionale.
/https://www.ilsoftware.it/app/uploads/2024/02/groq-chatbot-output.png)
Si può addirittura chiedere la generazione di una lista puntata che riassuma i contenuti più importanti del testo, estendere il contenuto, creare una tabella così come diverse altre varianti.
Com’è scontato, Groq tiene a mostrare in tempo reale le prestazioni di elaborazione sbandierando dati come il numero di token elaborati, la velocità di calcolo e il tempo di inferenza (sia nelle fase di input che di output).
Integrare Groq nelle proprie applicazioni
Con il preciso intento di favorire l’utilizzo di Groq nelle applicazioni degli utenti, l’azienda mette a disposizione delle API (Application Programming Interface) che consentono di dialogare con i chip LPU e i sottostanti modelli LLM.
Il periodo di prova gratuito di 10 giorni mette a disposizione 1 milione di token, liberamente utilizzabili per verificare le abilità di Groq e integrare il sistema nei propri progetti. Inoltre, la “furbata” è che Groq è compatibile con la struttura delle API OpenAI. Ciò significa che migrare da OpenAI a Groq è semplice tanto quanto la modifica di una semplice stringa di connessione.
Groq assicura supporto a framework di machine learning standard come PyTorch, TensorFlow e ONNX per l’inferenza. Questo significa che la piattaforma è in grado di eseguire previsioni o inferenze utilizzando modelli di machine learning già addestrati su questi framework.
Attualmente, Groq non supporta l’addestramento di modelli utilizzando il motore basato su LPU: ciò implica che, al momento, la piattaforma non è progettata per l’addestramento di nuovi modelli, ma piuttosto per l’esecuzione veloce di modelli già addestrati.
Ampie possibilità di personalizzazione, anche in termini di ottimizzazione dei workload
Per lo sviluppo personalizzato, Groq fornisce la suite GroqWare, che include il Groq Compiler. Si tratta di una soluzione che garantisce esperienza semplificata, essenziale per un rapido utilizzo dei modelli. Il Groq Compiler permette tra l’altro anche l’ottimizzazione dei carichi di lavoro, con la possibilità di sviluppare codice “ad hoc” per l’architettura Groq e ottenere un controllo dettagliato a livello di processore.
Groq è un’azienda di elaborazione specifica per applicazione (ASIC) che ha creato un processore progettato specificamente per l’esecuzione di carichi di lavoro di intelligenza artificiale e apprendimento automatico. Ecco alcuni dei vantaggi dell’utilizzo di Groq:
I vantaggi dell’utilizzo di Groq includono prestazioni elevate, efficienza energetica, facilità di programmazione, scalabilità e sicurezza. Tutti aspetti che rendono la nuova piattaforma una scelta interessante per le applicazioni di intelligenza artificiale e machine learning che richiedono una potenza di calcolo elevata e un’eccellente efficienza energetica.
/https://www.ilsoftware.it/app/uploads/2024/03/wish-disney.jpg "OpenAI potrà usare i personaggi Disney, Google no")
/https://www.ilsoftware.it/app/uploads/2025/06/grok-donald-trump.jpg "Trump blinda l'AI: più controllo col nuovo ordine esecutivo")
/https://www.ilsoftware.it/app/uploads/2025/07/grok.jpeg "Le scuole di El Salvador si affidano all'AI Grok di Elon Musk")
/https://www.ilsoftware.it/app/uploads/2025/12/novita-GPT-52.jpg "GPT-5.2: analisi delle novità del nuovo modello AI integrato in ChatGPT e nelle API")